 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Databases Faster with LLM Evolutionary Sampling
Feb 11, 2026Traditional query optimization relies on cost-based optimizers that estimate execution cost (e.g., runtime, memory, and I/O) using predefined heuristics and statistical models. Improving these heuristics requires substantial engineering effort, and even when implemented, these heuristics often cannot take into account semantic correlations in queries and schemas that could enable better physical plans. Using our DBPlanBench harness for the DataFusion engine, we expose the physical plan through a compact serialized representation and let the LLM propose localized edits that can be applied and executed. We then apply an evolutionary search over these edits to refine candidates across iterations. Our key insight is that LLMs can leverage semantic knowledge to identify and apply non-obvious optimizations, such as join orderings that minimize intermediate cardinalities. We obtain up to 4.78$\times$ speedups on some queries and we demonstrate a small-to-large workflow in which optimizations found on small databases transfer effectively to larger databases.
Safe, Untrusted, "Proof-Carrying" AI Agents: toward the agentic lakehouse
Oct 10, 2025Data lakehouses run sensitive workloads, where AI-driven automation raises concerns about trust, correctness, and governance. We argue that API-first, programmable lakehouses provide the right abstractions for safe-by-design, agentic workflows. Using Bauplan as a case study, we show how data branching and declarative environments extend naturally to agents, enabling reproducibility and observability while reducing the attack surface. We present a proof-of-concept in which agents repair data pipelines using correctness checks inspired by proof-carrying code. Our prototype demonstrates that untrusted AI agents can operate safely on production data and outlines a path toward a fully agentic lakehouse.
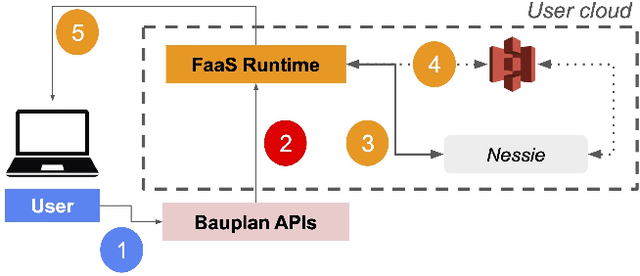
Bauplan: zero-copy, scale-up FaaS for data pipelines
Oct 22, 2024



Chaining functions for longer workloads is a key use case for FaaS platforms in data applications. However, modern data pipelines differ significantly from typical serverless use cases (e.g., webhooks and microservices); this makes it difficult to retrofit existing pipeline frameworks due to structural constraints. In this paper, we describe these limitations in detail and introduce bauplan, a novel FaaS programming model and serverless runtime designed for data practitioners. bauplan enables users to declaratively define functional Directed Acyclic Graphs (DAGs) along with their runtime environments, which are then efficiently executed on cloud-based workers. We show that bauplan achieves both better performance and a superior developer experience for data workloads by making the trade-off of reducing generality in favor of data-awareness
Reproducible data science over data lakes: replayable data pipelines with Bauplan and Nessie
Apr 21, 2024

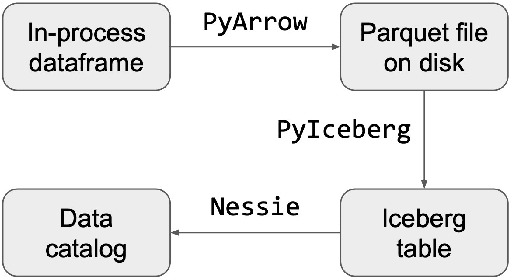
As the Lakehouse architecture becomes more widespread, ensuring the reproducibility of data workloads over data lakes emerges as a crucial concern for data engineers. However, achieving reproducibility remains challenging. The size of data pipelines contributes to slow testing and iterations, while the intertwining of business logic and data management complicates debugging and increases error susceptibility. In this paper, we highlight recent advancements made at Bauplan in addressing this challenge. We introduce a system designed to decouple compute from data management, by leveraging a cloud runtime alongside Nessie, an open-source catalog with Git semantics. Demonstrating the system's capabilities, we showcase its ability to offer time-travel and branching semantics on top of object storage, and offer full pipeline reproducibility with a few CLI commands.
Space is Not the Final Frontier: Product Search as Program Synthesis
Apr 22, 2023
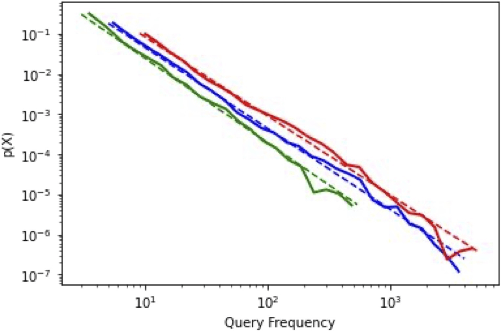

As ecommerce continues growing, huge investments in ML and NLP for Information Retrieval are following. While the vector space model dominated retrieval modelling in product search - even as vectorization itself greatly changed with the advent of deep learning -, our position paper argues in a contrarian fashion that program synthesis provides significant advantages for many queries and a significant number of players in the market. We detail the industry significance of the proposed approach, sketch implementation details, and address common objections drawing from our experience building a similar system at Tooso.
E Pluribus Unum: Guidelines on Multi-Objective Evaluation of Recommender Systems
Apr 20, 2023Recommender Systems today are still mostly evaluated in terms of accuracy, with other aspects beyond the immediate relevance of recommendations, such as diversity, long-term user retention and fairness, often taking a back seat. Moreover, reconciling multiple performance perspectives is by definition indeterminate, presenting a stumbling block to those in the pursuit of rounded evaluation of Recommender Systems. EvalRS 2022 -- a data challenge designed around Multi-Objective Evaluation -- was a first practical endeavour, providing many insights into the requirements and challenges of balancing multiple objectives in evaluation. In this work, we reflect on EvalRS 2022 and expound upon crucial learnings to formulate a first-principles approach toward Multi-Objective model selection, and outline a set of guidelines for carrying out a Multi-Objective Evaluation challenge, with potential applicability to the problem of rounded evaluation of competing models in real-world deployments.
EvalRS 2023. Well-Rounded Recommender Systems For Real-World Deployments
Apr 19, 2023EvalRS aims to bring together practitioners from industry and academia to foster a debate on rounded evaluation of recommender systems, with a focus on real-world impact across a multitude of deployment scenarios. Recommender systems are often evaluated only through accuracy metrics, which fall short of fully characterizing their generalization capabilities and miss important aspects, such as fairness, bias, usefulness, informativeness. This workshop builds on the success of last year's workshop at CIKM, but with a broader scope and an interactive format.
EvalRS: a Rounded Evaluation of Recommender Systems
Jul 12, 2022
Much of the complexity of Recommender Systems (RSs) comes from the fact that they are used as part of more complex applications and affect user experience through a varied range of user interfaces. However, research focused almost exclusively on the ability of RSs to produce accurate item rankings while giving little attention to the evaluation of RS behavior in real-world scenarios. Such narrow focus has limited the capacity of RSs to have a lasting impact in the real world and makes them vulnerable to undesired behavior, such as reinforcing data biases. We propose EvalRS as a new type of challenge, in order to foster this discussion among practitioners and build in the open new methodologies for testing RSs "in the wild".
FashionCLIP: Connecting Language and Images for Product Representations
Apr 11, 2022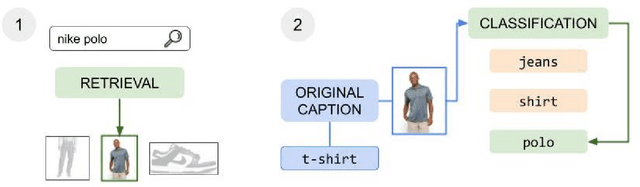
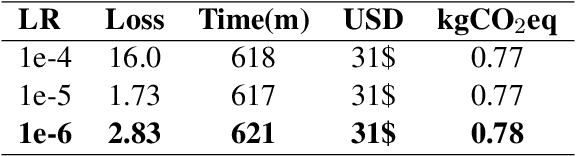
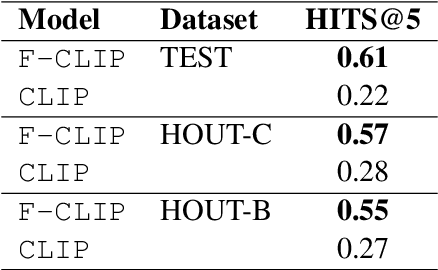

The steady rise of online shopping goes hand in hand with the development of increasingly complex ML and NLP models. While most use cases are cast as specialized supervised learning problems, we argue that practitioners would greatly benefit from more transferable representations of products. In this work, we build on recent developments in contrastive learning to train FashionCLIP, a CLIP-like model for the fashion industry. We showcase its capabilities for retrieval, classification and grounding, and release our model and code to the community.
"Does it come in black?" CLIP-like models are zero-shot recommenders
Apr 11, 2022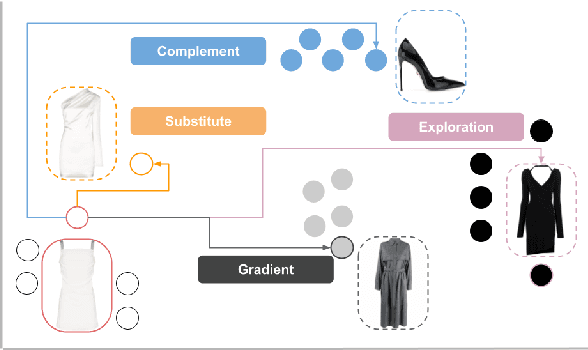
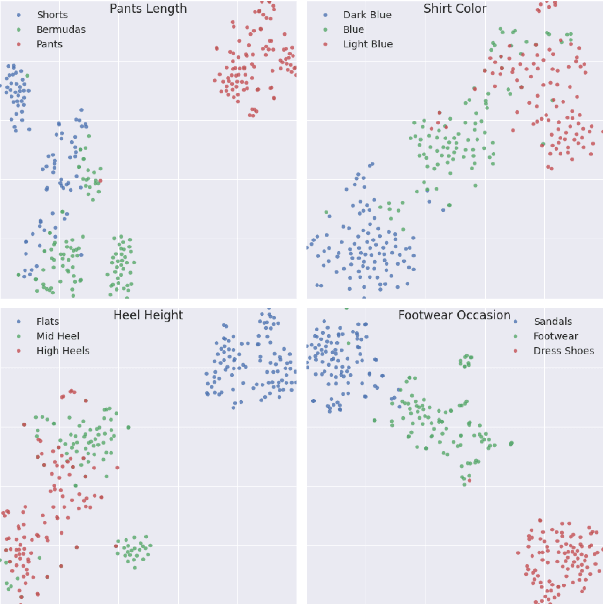


Product discovery is a crucial component for online shopping. However, item-to-item recommendations today do not allow users to explore changes along selected dimensions: given a query item, can a model suggest something similar but in a different color? We consider item recommendations of the comparative nature (e.g. "something darker") and show how CLIP-based models can support this use case in a zero-shot manner. Leveraging a large model built for fashion, we introduce GradREC and its industry potential, and offer a first rounded assessment of its strength and weaknesses.