 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducible data science over data lakes: replayable data pipelines with Bauplan and Nessie
Paper and Code


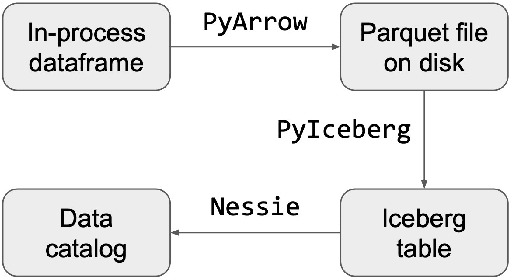
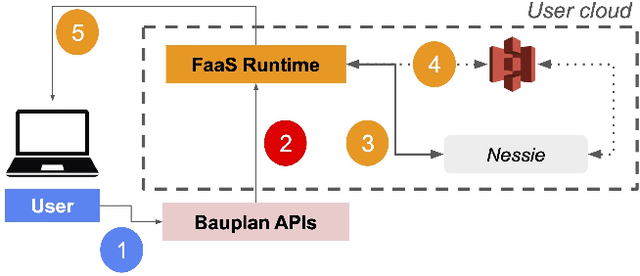
As the Lakehouse architecture becomes more widespread, ensuring the reproducibility of data workloads over data lakes emerges as a crucial concern for data engineers. However, achieving reproducibility remains challenging. The size of data pipelines contributes to slow testing and iterations, while the intertwining of business logic and data management complicates debugging and increases error susceptibility. In this paper, we highlight recent advancements made at Bauplan in addressing this challenge. We introduce a system designed to decouple compute from data management, by leveraging a cloud runtime alongside Nessie, an open-source catalog with Git semantics. Demonstrating the system's capabilities, we showcase its ability to offer time-travel and branching semantics on top of object storage, and offer full pipeline reproducibility with a few CLI commands.