 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron ColEmbed V2: Top-Performing Late Interaction embedding models for Visual Document Retrieval
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems have been popular for generative applications, powering language models by injecting external knowledge. Companies have been trying to leverage their large catalog of documents (e.g. PDFs, presentation slides) in such RAG pipelines, whose first step is the retrieval component. Dense retrieval has been a popular approach, where embedding models are used to generate a dense representation of the user query that is closer to relevant content embeddings. More recently, VLM-based embedding models have become popular for visual document retrieval, as they preserve visual information and simplify the indexing pipeline compared to OCR text extraction. Motivated by the growing demand for visual document retrieval, we introduce Nemotron ColEmbed V2, a family of models that achieve state-of-the-art performance on the ViDoRe benchmarks. We release three variants - with 3B, 4B, and 8B parameters - based on pre-trained VLMs: NVIDIA Eagle 2 with Llama 3.2 3B backbone, Qwen3-VL-4B-Instruct and Qwen3-VL-8B-Instruct, respectively. The 8B model ranks first on the ViDoRe V3 leaderboard as of February 03, 2026, achieving an average NDCG@10 of 63.42. We describe the main techniques used across data processing, training, and post-training - such as cluster-based sampling, hard-negative mining, bidirectional attention, late interaction, and model merging - that helped us build our top-performing models. We also discuss compute and storage engineering challenges posed by the late interaction mechanism and present experiments on how to balance accuracy and storage with lower dimension embeddings.
MIRACL-VISION: A Large, multilingual, visual document retrieval benchmark
May 16, 2025Document retrieval is an important task for search and Retrieval-Augmented Generation (RAG) applications. Large Language Models (LLMs) have contributed to improving the accuracy of text-based document retrieval. However, documents with complex layout and visual elements like tables, charts and infographics are not perfectly represented in textual format. Recently, image-based document retrieval pipelines have become popular, which use visual large language models (VLMs) to retrieve relevant page images given a query. Current evaluation benchmarks on visual document retrieval are limited, as they primarily focus only English language, rely on synthetically generated questions and offer a small corpus size. Therefore, we introduce MIRACL-VISION, a multilingual visual document retrieval evaluation benchmark. MIRACL-VISION covers 18 languages, and is an extension of the MIRACL dataset, a popular benchmark to evaluate text-based multilingual retrieval pipelines. MIRACL was built using a human-intensive annotation process to generate high-quality questions. In order to reduce MIRACL-VISION corpus size to make evaluation more compute friendly while keeping the datasets challenging, we have designed a method for eliminating the "easy" negatives from the corpus. We conducted extensive experiments comparing MIRACL-VISION with other benchmarks, using popular public text and image models. We observe a gap in state-of-the-art VLM-based embedding models on multilingual capabilities, with up to 59.7% lower retrieval accuracy than a text-based retrieval models. Even for the English language, the visual models retrieval accuracy is 12.1% lower compared to text-based models. MIRACL-VISION is a challenging, representative, multilingual evaluation benchmark for visual retrieval pipelines and will help the community build robust models for document retrieval.
Enhancing Q&A Text Retrieval with Ranking Models: Benchmarking, fine-tuning and deploying Rerankers for RAG
Sep 12, 2024Ranking models play a crucial role in enhancing overall accuracy of text retrieval systems. These multi-stage systems typically utilize either dense embedding models or sparse lexical indices to retrieve relevant passages based on a given query, followed by ranking models that refine the ordering of the candidate passages by its relevance to the query. This paper benchmarks various publicly available ranking models and examines their impact on ranking accuracy. We focus on text retrieval for question-answering tasks, a common use case for Retrieval-Augmented Generation systems. Our evaluation benchmarks include models some of which are commercially viable for industrial applications. We introduce a state-of-the-art ranking model, NV-RerankQA-Mistral-4B-v3, which achieves a significant accuracy increase of ~14% compared to pipelines with other rerankers. We also provide an ablation study comparing the fine-tuning of ranking models with different sizes, losses and self-attention mechanisms. Finally, we discuss challenges of text retrieval pipelines with ranking models in real-world industry applications, in particular the trade-offs among model size, ranking accuracy and system requirements like indexing and serving latency / throughput.
NV-Retriever: Improving text embedding models with effective hard-negative mining
Jul 22, 2024Text embedding models have been popular for information retrieval applications such as semantic search and Question-Answering systems based on Retrieval-Augmented Generation (RAG). Those models are typically Transformer models that are fine-tuned with contrastive learning objectives. Many papers introduced new embedding model architectures and training approaches, however, one of the key ingredients, the process of mining negative passages, remains poorly explored or described. One of the challenging aspects of fine-tuning embedding models is the selection of high quality hard-negative passages for contrastive learning. In this paper we propose a family of positive-aware mining methods that leverage the positive relevance score for more effective false negatives removal. We also provide a comprehensive ablation study on hard-negative mining methods over their configurations, exploring different teacher and base models. We demonstrate the efficacy of our proposed methods by introducing the NV-Retriever-v1 model, which scores 60.9 on MTEB Retrieval (BEIR) benchmark and 0.65 points higher than previous methods. The model placed 1st when it was published to MTEB Retrieval on July 07, 2024.
E Pluribus Unum: Guidelines on Multi-Objective Evaluation of Recommender Systems
Apr 20, 2023Recommender Systems today are still mostly evaluated in terms of accuracy, with other aspects beyond the immediate relevance of recommendations, such as diversity, long-term user retention and fairness, often taking a back seat. Moreover, reconciling multiple performance perspectives is by definition indeterminate, presenting a stumbling block to those in the pursuit of rounded evaluation of Recommender Systems. EvalRS 2022 -- a data challenge designed around Multi-Objective Evaluation -- was a first practical endeavour, providing many insights into the requirements and challenges of balancing multiple objectives in evaluation. In this work, we reflect on EvalRS 2022 and expound upon crucial learnings to formulate a first-principles approach toward Multi-Objective model selection, and outline a set of guidelines for carrying out a Multi-Objective Evaluation challenge, with potential applicability to the problem of rounded evaluation of competing models in real-world deployments.
EvalRS: a Rounded Evaluation of Recommender Systems
Jul 12, 2022
Much of the complexity of Recommender Systems (RSs) comes from the fact that they are used as part of more complex applications and affect user experience through a varied range of user interfaces. However, research focused almost exclusively on the ability of RSs to produce accurate item rankings while giving little attention to the evaluation of RS behavior in real-world scenarios. Such narrow focus has limited the capacity of RSs to have a lasting impact in the real world and makes them vulnerable to undesired behavior, such as reinforcing data biases. We propose EvalRS as a new type of challenge, in order to foster this discussion among practitioners and build in the open new methodologies for testing RSs "in the wild".
Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation
Jul 11, 2021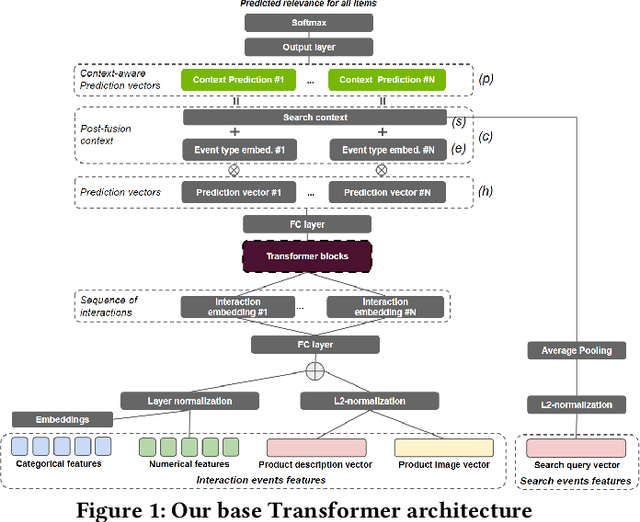
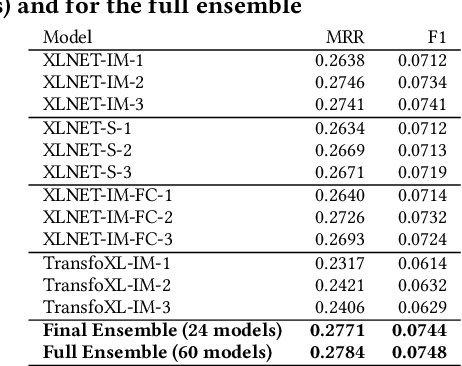
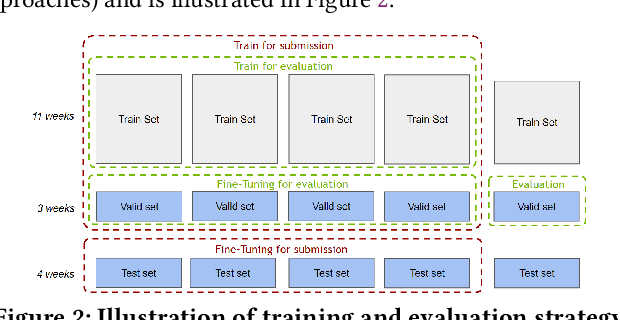
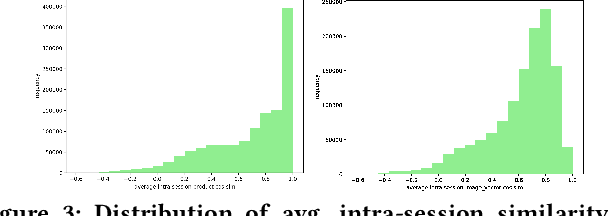
Session-based recommendation is an important task for e-commerce services, where a large number of users browse anonymously or may have very distinct interests for different sessions. In this paper we present one of the winning solutions for the Recommendation task of the SIGIR 2021 Workshop on E-commerce Data Challenge. Our solution was inspired by NLP techniques and consists of an ensemble of two Transformer architectures - Transformer-XL and XLNet - trained with autoregressive and autoencoding approaches. To leverage most of the rich dataset made available for the competition, we describe how we prepared multi-model features by combining tabular events with textual and image vectors. We also present a model prediction analysis to better understand the effectiveness of our architectures for the session-based recommendation.
Hybrid Session-based News Recommendation using Recurrent Neural Networks
Jun 22, 2020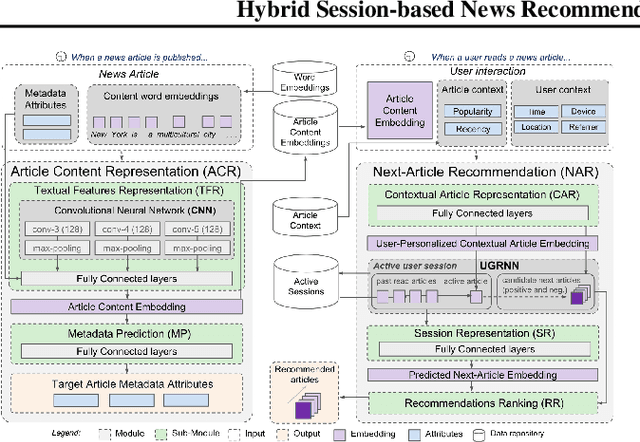


We describe a hybrid meta-architecture -- the CHAMELEON -- for session-based news recommendation that is able to leverage a variety of information types using Recurrent Neural Networks. We evaluated our approach on two public datasets, using a temporal evaluation protocol that simulates the dynamics of a news portal in a realistic way. Our results confirm the benefits of modeling the sequence of session clicks with RNNs and leveraging side information about users and articles, resulting in significantly higher recommendation accuracy and catalog coverage than other session-based algorithms.
On the Importance of News Content Representation in Hybrid Neural Session-based Recommender Systems
Aug 19, 2019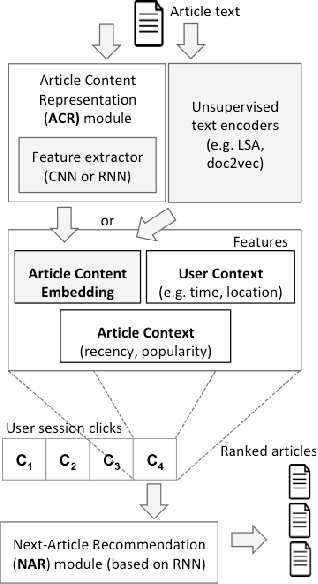



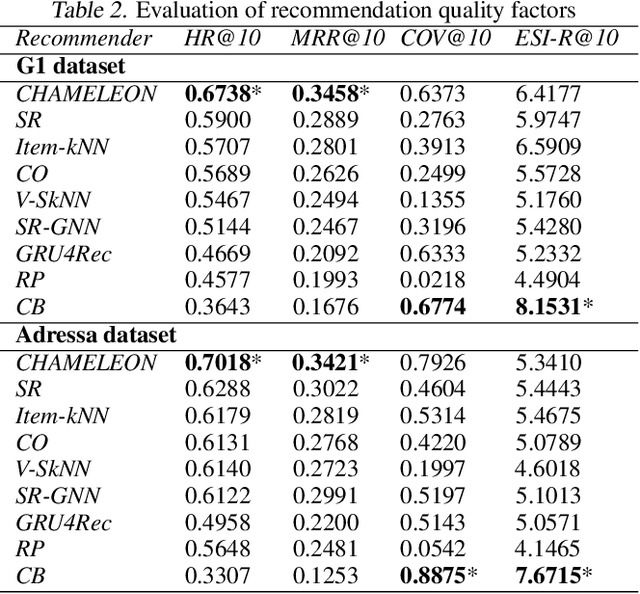
News recommender systems are designed to surface relevant information for online readers by personalizing their user experiences. A particular problem in that context is that online readers are often anonymous, which means that this personalization can only be based on the last few recorded interactions with the user, a setting named session-based recommendation. Another particularity of the news domain is that constantly fresh articles are published, which should be immediately considered for recommendation. To deal with this item cold-start problem, it is important to consider the actual content of items when recommending. Hybrid approaches are therefore often considered as the method of choice in such settings. In this work, we analyze the importance of considering content information in a hybrid neural news recommender system. We contrast content-aware and content-agnostic techniques and also explore the effects of using different content encodings. Experiments on two public datasets confirm the importance of adopting a hybrid approach. Furthermore, we show that the choice of the content encoding can have an impact on the resulting performance.
News Session-Based Recommendations using Deep Neural Networks
Sep 17, 2018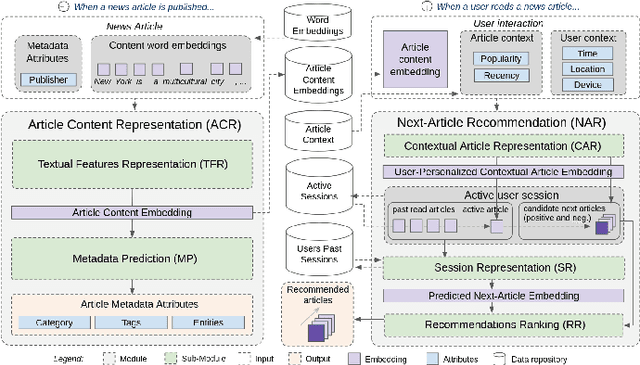
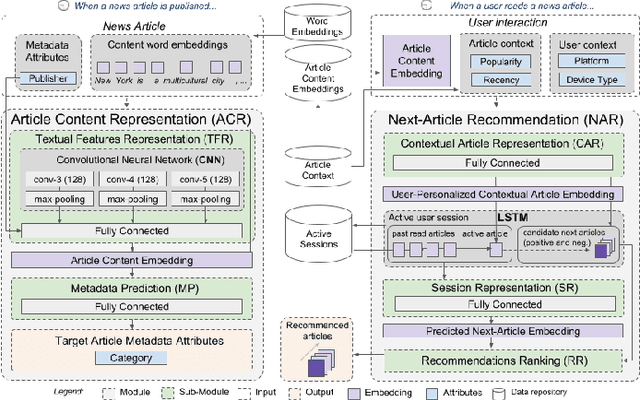
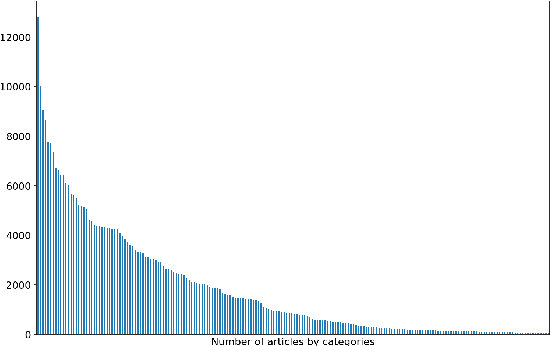
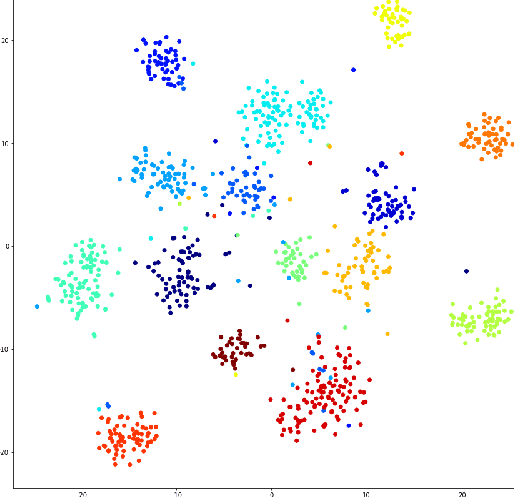
News recommender systems are aimed to personalize users experiences and help them to discover relevant articles from a large and dynamic search space. Therefore, news domain is a challenging scenario for recommendations, due to its sparse user profiling, fast growing number of items, accelerated item's value decay, and users preferences dynamic shift. Some promising results have been recently achieved by the usage of Deep Learning techniques on Recommender Systems, specially for item's feature extraction and for session-based recommendations with Recurrent Neural Networks. In this paper, it is proposed an instantiation of the CHAMELEON -- a Deep Learning Meta-Architecture for News Recommender Systems. This architecture is composed of two modules, the first responsible to learn news articles representations, based on their text and metadata, and the second module aimed to provide session-based recommendations using Recurrent Neural Networks. The recommendation task addressed in this work is next-item prediction for users sessions: "what is the next most likely article a user might read in a session?" Users sessions context is leveraged by the architecture to provide additional information in such extreme cold-start scenario of news recommendation. Users' behavior and item features are both merged in an hybrid recommendation approach. A temporal offline evaluation method is also proposed as a complementary contribution, for a more realistic evaluation of such task, considering dynamic factors that affect global readership interests like popularity, recency, and seasonality. Experiments with an extensive number of session-based recommendation methods were performed and the proposed instantiation of CHAMELEON meta-architecture obtained a significant relative improvement in top-n accuracy and ranking metrics (10% on Hit Rate and 13% on MRR) over the best benchmark methods.