 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron ColEmbed V2: Top-Performing Late Interaction embedding models for Visual Document Retrieval
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems have been popular for generative applications, powering language models by injecting external knowledge. Companies have been trying to leverage their large catalog of documents (e.g. PDFs, presentation slides) in such RAG pipelines, whose first step is the retrieval component. Dense retrieval has been a popular approach, where embedding models are used to generate a dense representation of the user query that is closer to relevant content embeddings. More recently, VLM-based embedding models have become popular for visual document retrieval, as they preserve visual information and simplify the indexing pipeline compared to OCR text extraction. Motivated by the growing demand for visual document retrieval, we introduce Nemotron ColEmbed V2, a family of models that achieve state-of-the-art performance on the ViDoRe benchmarks. We release three variants - with 3B, 4B, and 8B parameters - based on pre-trained VLMs: NVIDIA Eagle 2 with Llama 3.2 3B backbone, Qwen3-VL-4B-Instruct and Qwen3-VL-8B-Instruct, respectively. The 8B model ranks first on the ViDoRe V3 leaderboard as of February 03, 2026, achieving an average NDCG@10 of 63.42. We describe the main techniques used across data processing, training, and post-training - such as cluster-based sampling, hard-negative mining, bidirectional attention, late interaction, and model merging - that helped us build our top-performing models. We also discuss compute and storage engineering challenges posed by the late interaction mechanism and present experiments on how to balance accuracy and storage with lower dimension embeddings.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks
Nov 10, 2025We introduce llama-embed-nemotron-8b, an open-weights text embedding model that achieves state-of-the-art performance on the Multilingual Massive Text Embedding Benchmark (MMTEB) leaderboard as of October 21, 2025. While recent models show strong performance, their training data or methodologies are often not fully disclosed. We aim to address this by developing a fully open-source model, publicly releasing its weights and detailed ablation studies, and planning to share the curated training datasets. Our model demonstrates superior performance across all major embedding tasks -- including retrieval, classification and semantic textual similarity (STS) -- and excels in challenging multilingual scenarios, such as low-resource languages and cross-lingual setups. This state-of-the-art performance is driven by a novel data mix of 16.1 million query-document pairs, split between 7.7 million samples from public datasets and 8.4 million synthetically generated examples from various open-weight LLMs. One of our key contributions is a detailed ablation study analyzing core design choices, including a comparison of contrastive loss implementations, an evaluation of synthetic data generation (SDG) strategies, and the impact of model merging. The llama-embed-nemotron-8b is an instruction-aware model, supporting user-defined instructions to enhance performance for specific use-cases. This combination of top-tier performance, broad applicability, and user-driven flexibility enables it to serve as a universal text embedding solution.
MIRACL-VISION: A Large, multilingual, visual document retrieval benchmark
May 16, 2025Document retrieval is an important task for search and Retrieval-Augmented Generation (RAG) applications. Large Language Models (LLMs) have contributed to improving the accuracy of text-based document retrieval. However, documents with complex layout and visual elements like tables, charts and infographics are not perfectly represented in textual format. Recently, image-based document retrieval pipelines have become popular, which use visual large language models (VLMs) to retrieve relevant page images given a query. Current evaluation benchmarks on visual document retrieval are limited, as they primarily focus only English language, rely on synthetically generated questions and offer a small corpus size. Therefore, we introduce MIRACL-VISION, a multilingual visual document retrieval evaluation benchmark. MIRACL-VISION covers 18 languages, and is an extension of the MIRACL dataset, a popular benchmark to evaluate text-based multilingual retrieval pipelines. MIRACL was built using a human-intensive annotation process to generate high-quality questions. In order to reduce MIRACL-VISION corpus size to make evaluation more compute friendly while keeping the datasets challenging, we have designed a method for eliminating the "easy" negatives from the corpus. We conducted extensive experiments comparing MIRACL-VISION with other benchmarks, using popular public text and image models. We observe a gap in state-of-the-art VLM-based embedding models on multilingual capabilities, with up to 59.7% lower retrieval accuracy than a text-based retrieval models. Even for the English language, the visual models retrieval accuracy is 12.1% lower compared to text-based models. MIRACL-VISION is a challenging, representative, multilingual evaluation benchmark for visual retrieval pipelines and will help the community build robust models for document retrieval.
AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
Apr 23, 2025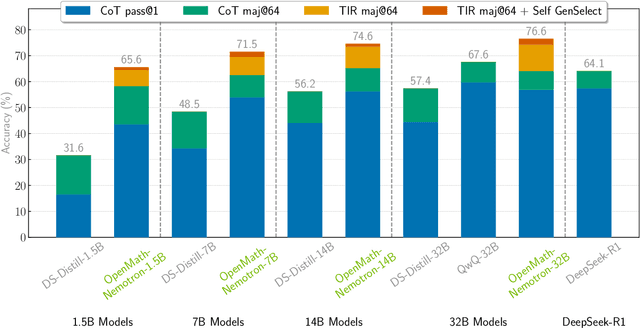
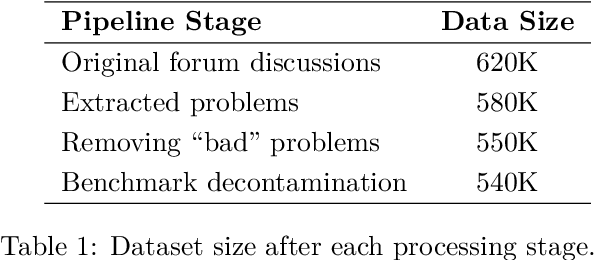

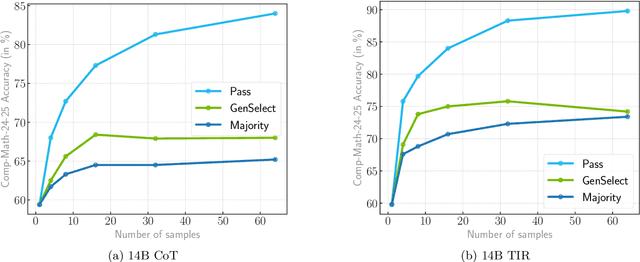
This paper presents our winning submission to the AI Mathematical Olympiad - Progress Prize 2 (AIMO-2) competition. Our recipe for building state-of-the-art mathematical reasoning models relies on three key pillars. First, we create a large-scale dataset comprising 540K unique high-quality math problems, including olympiad-level problems, and their 3.2M long-reasoning solutions. Second, we develop a novel method to integrate code execution with long reasoning models through iterative training, generation, and quality filtering, resulting in 1.7M high-quality Tool-Integrated Reasoning solutions. Third, we create a pipeline to train models to select the most promising solution from many candidates. We show that such generative solution selection (GenSelect) can significantly improve upon majority voting baseline. Combining these ideas, we train a series of models that achieve state-of-the-art results on mathematical reasoning benchmarks. To facilitate further research, we release our code, models, and the complete OpenMathReasoning dataset under a commercially permissive license.
Enhancing Q&A Text Retrieval with Ranking Models: Benchmarking, fine-tuning and deploying Rerankers for RAG
Sep 12, 2024Ranking models play a crucial role in enhancing overall accuracy of text retrieval systems. These multi-stage systems typically utilize either dense embedding models or sparse lexical indices to retrieve relevant passages based on a given query, followed by ranking models that refine the ordering of the candidate passages by its relevance to the query. This paper benchmarks various publicly available ranking models and examines their impact on ranking accuracy. We focus on text retrieval for question-answering tasks, a common use case for Retrieval-Augmented Generation systems. Our evaluation benchmarks include models some of which are commercially viable for industrial applications. We introduce a state-of-the-art ranking model, NV-RerankQA-Mistral-4B-v3, which achieves a significant accuracy increase of ~14% compared to pipelines with other rerankers. We also provide an ablation study comparing the fine-tuning of ranking models with different sizes, losses and self-attention mechanisms. Finally, we discuss challenges of text retrieval pipelines with ranking models in real-world industry applications, in particular the trade-offs among model size, ranking accuracy and system requirements like indexing and serving latency / throughput.
Winning Amazon KDD Cup'24
Aug 05, 2024This paper describes the winning solution of all 5 tasks for the Amazon KDD Cup 2024 Multi Task Online Shopping Challenge for LLMs. The challenge was to build a useful assistant, answering questions in the domain of online shopping. The competition contained 57 diverse tasks, covering 5 different task types (e.g. multiple choice) and across 4 different tracks (e.g. multi-lingual). Our solution is a single model per track. We fine-tune Qwen2-72B-Instruct on our own training dataset. As the competition released only 96 example questions, we developed our own training dataset by processing multiple public datasets or using Large Language Models for data augmentation and synthetic data generation. We apply wise-ft to account for distribution shifts and ensemble multiple LoRA adapters in one model. We employed Logits Processors to constrain the model output on relevant tokens for the tasks. AWQ 4-bit Quantization and vLLM are used during inference to predict the test dataset in the time constraints of 20 to 140 minutes depending on the track. Our solution achieved the first place in each individual track and is the first place overall of Amazons KDD Cup 2024.
NV-Retriever: Improving text embedding models with effective hard-negative mining
Jul 22, 2024Text embedding models have been popular for information retrieval applications such as semantic search and Question-Answering systems based on Retrieval-Augmented Generation (RAG). Those models are typically Transformer models that are fine-tuned with contrastive learning objectives. Many papers introduced new embedding model architectures and training approaches, however, one of the key ingredients, the process of mining negative passages, remains poorly explored or described. One of the challenging aspects of fine-tuning embedding models is the selection of high quality hard-negative passages for contrastive learning. In this paper we propose a family of positive-aware mining methods that leverage the positive relevance score for more effective false negatives removal. We also provide a comprehensive ablation study on hard-negative mining methods over their configurations, exploring different teacher and base models. We demonstrate the efficacy of our proposed methods by introducing the NV-Retriever-v1 model, which scores 60.9 on MTEB Retrieval (BEIR) benchmark and 0.65 points higher than previous methods. The model placed 1st when it was published to MTEB Retrieval on July 07, 2024.
Robust Temporal Ensembling for Learning with Noisy Labels
Sep 29, 2021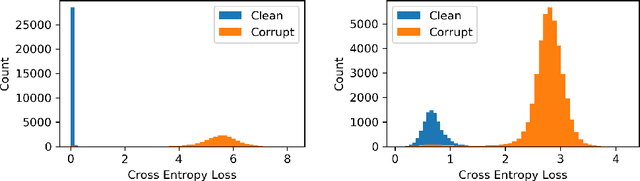
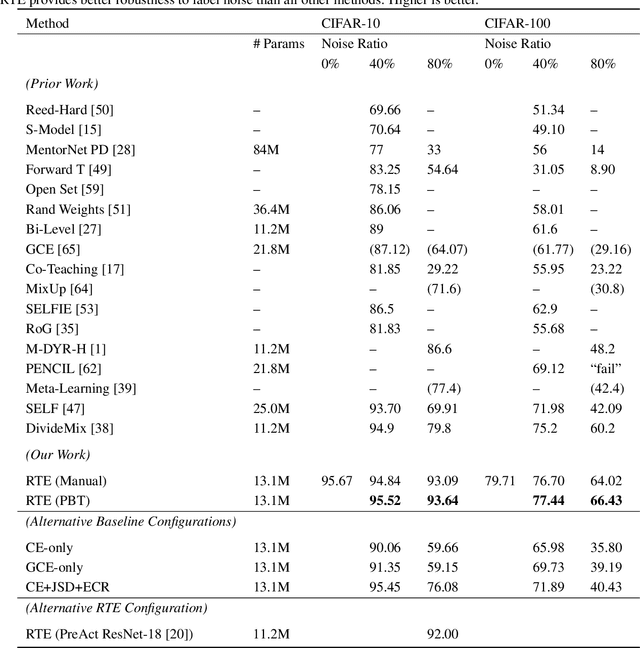
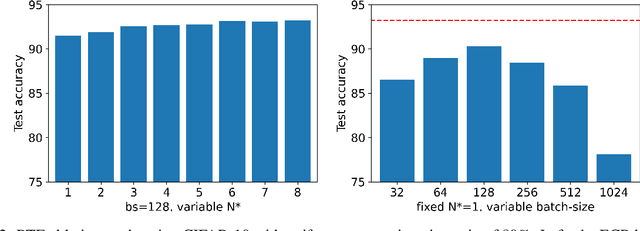
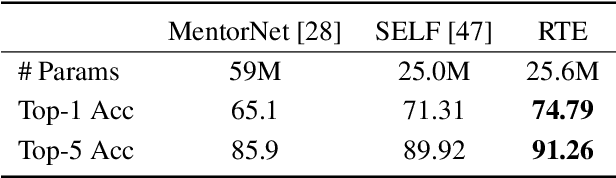
Successful training of deep neural networks with noisy labels is an essential capability as most real-world datasets contain some amount of mislabeled data. Left unmitigated, label noise can sharply degrade typical supervised learning approaches. In this paper, we present robust temporal ensembling (RTE), which combines robust loss with semi-supervised regularization methods to achieve noise-robust learning. We demonstrate that RTE achieves state-of-the-art performance across the CIFAR-10, CIFAR-100, ImageNet, WebVision, and Food-101N datasets, while forgoing the recent trend of label filtering and/or fixing. Finally, we show that RTE also retains competitive corruption robustness to unforeseen input noise using CIFAR-10-C, obtaining a mean corruption error (mCE) of 13.50% even in the presence of an 80% noise ratio, versus 26.9% mCE with standard methods on clean data.