 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Trajectory Prediction for Autonomous Vehicles
Nov 18, 2019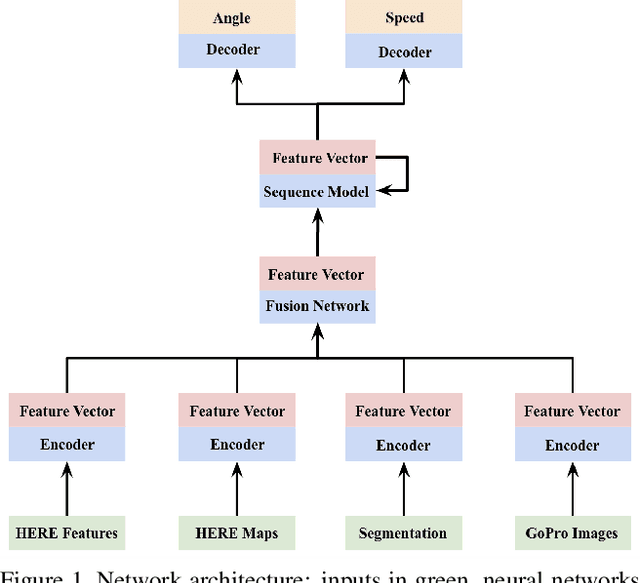


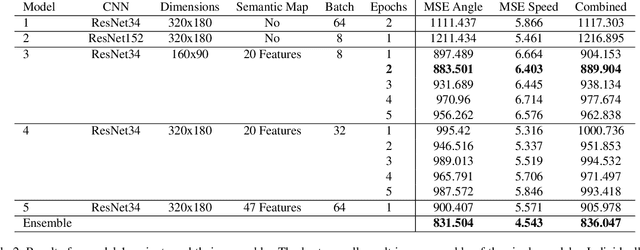
Predicting vehicle trajectories, angle and speed is important for safe and comfortable driving. We demonstrate the best predicted angle, speed, and best performance overall winning the top three places of the ICCV 2019 Learning to Drive challenge. Our key contributions are (i) a general neural network system architecture which embeds and fuses together multiple inputs by encoding, and decodes multiple outputs using neural networks, (ii) using pre-trained neural networks for augmenting the given input data with segmentation maps and semantic information, and (iii) leveraging the form and distribution of the expected output in the model.
Winning the ICCV 2019 Learning to Drive Challenge
Oct 23, 2019



Autonomous driving has a significant impact on society. Predicting vehicle trajectories, specifically, angle and speed, is important for safe and comfortable driving. This work focuses on fusing inputs from camera sensors and visual map data which lead to significant improvement in performance and plays a key role in winning the challenge. We use pre-trained CNN's for processing image frames, a neural network for fusing the image representation with visual map data, and train a sequence model for time series prediction. We demonstrate the best performing MSE angle and best performance overall, to win the ICCV 2019 Learning to Drive challenge. We make our models and code publicly available.
Deep neural network ensemble by data augmentation and bagging for skin lesion classification
Jul 24, 2018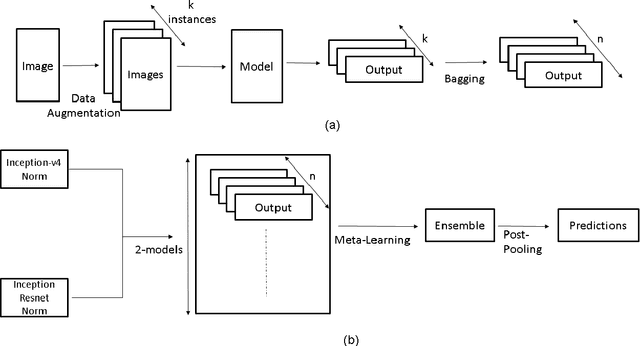

This work summarizes our submission for the Task 3: Disease Classification of ISIC 2018 challenge in Skin Lesion Analysis Towards Melanoma Detection. We use a novel deep neural network (DNN) ensemble architecture introduced by us that can effectively classify skin lesions by using data-augmentation and bagging to address paucity of data and prevent over-fitting. The ensemble is composed of two DNN architectures: Inception-v4 and Inception-Resnet-v2. The DNN architectures are combined in to an ensemble by using a $1\times1$ convolution for fusion in a meta-learning layer.
Dataset Augmentation with Synthetic Images Improves Semantic Segmentation
Jun 26, 2018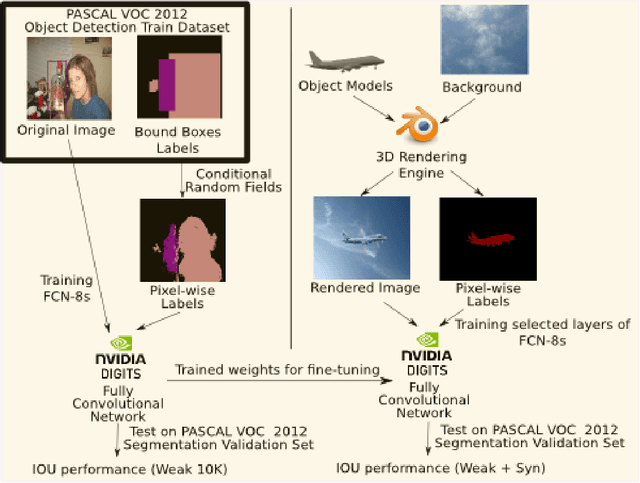
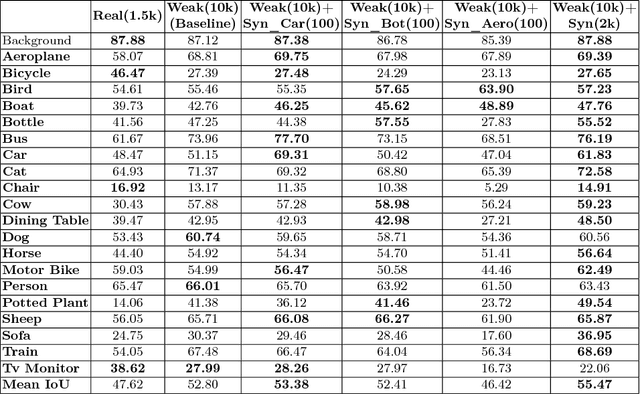


Although Deep Convolutional Neural Networks trained with strong pixel-level annotations have significantly pushed the performance in semantic segmentation, annotation efforts required for the creation of training data remains a roadblock for further improvements. We show that augmentation of the weakly annotated training dataset with synthetic images minimizes both the annotation efforts and also the cost of capturing images with sufficient variety. Evaluation on the PASCAL 2012 validation dataset shows an increase in mean IOU from 52.80% to 55.47% by adding just 100 synthetic images per object class. Our approach is thus a promising solution to the problems of annotation and dataset collection.