 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Augmentation with Synthetic Images Improves Semantic Segmentation
Jun 26, 2018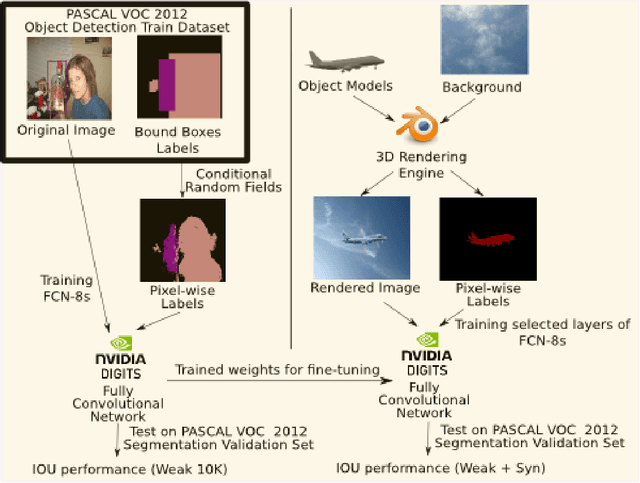
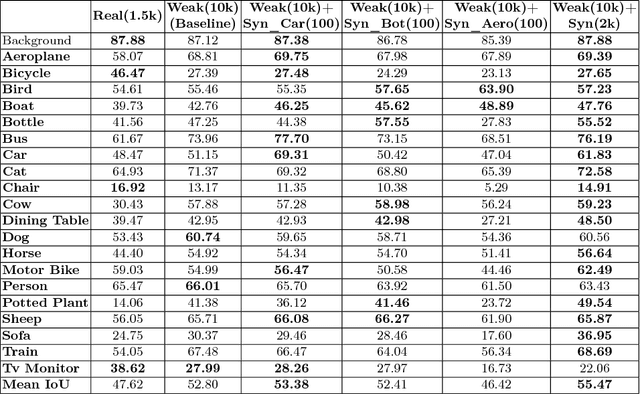


Although Deep Convolutional Neural Networks trained with strong pixel-level annotations have significantly pushed the performance in semantic segmentation, annotation efforts required for the creation of training data remains a roadblock for further improvements. We show that augmentation of the weakly annotated training dataset with synthetic images minimizes both the annotation efforts and also the cost of capturing images with sufficient variety. Evaluation on the PASCAL 2012 validation dataset shows an increase in mean IOU from 52.80% to 55.47% by adding just 100 synthetic images per object class. Our approach is thus a promising solution to the problems of annotation and dataset collection.
Object Detection Using Deep CNNs Trained on Synthetic Images
Sep 18, 2017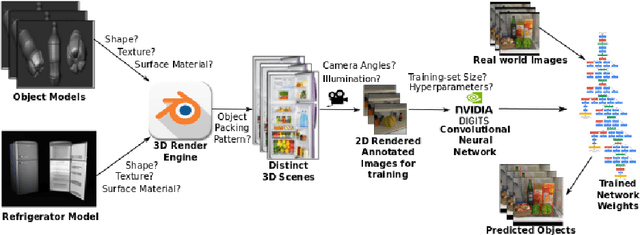



The need for large annotated image datasets for training Convolutional Neural Networks (CNNs) has been a significant impediment for their adoption in computer vision applications. We show that with transfer learning an effective object detector can be trained almost entirely on synthetically rendered datasets. We apply this strategy for detecting pack- aged food products clustered in refrigerator scenes. Our CNN trained only with 4000 synthetic images achieves mean average precision (mAP) of 24 on a test set with 55 distinct products as objects of interest and 17 distractor objects. A further increase of 12% in the mAP is obtained by adding only 400 real images to these 4000 synthetic images in the training set. A high degree of photorealism in the synthetic images was not essential in achieving this performance. We analyze factors like training data set size and 3D model dictionary size for their influence on detection performance. Additionally, training strategies like fine-tuning with selected layers and early stopping which affect transfer learning from synthetic scenes to real scenes are explored. Training CNNs with synthetic datasets is a novel application of high-performance computing and a promising approach for object detection applications in domains where there is a dearth of large annotated image data.
GPGPU Acceleration of the KAZE Image Feature Extraction Algorithm
Jun 21, 2017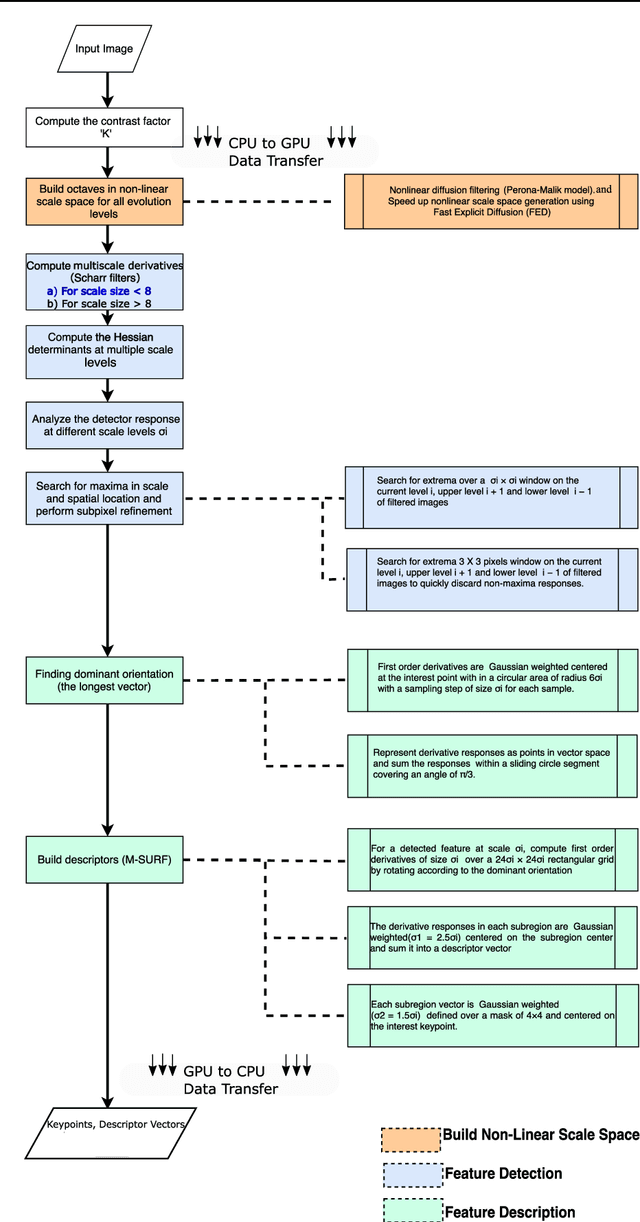
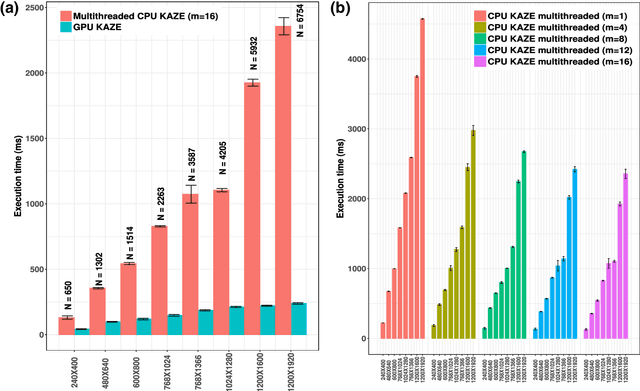


The recently proposed open-source KAZE image feature detection and description algorithm offers unprecedented performance in comparison to conventional ones like SIFT and SURF as it relies on nonlinear scale spaces instead of Gaussian linear scale spaces. The improved performance, however, comes with a significant computational cost limiting its use for many applications. We report a GPGPU implementation of the KAZE algorithm without resorting to binary descriptors for gaining speedup. For a 1920 by 1200 sized image our Compute Unified Device Architecture (CUDA) C based GPU version took around 300 milliseconds on a NVIDIA GeForce GTX Titan X (Maxwell Architecture-GM200) card in comparison to nearly 2400 milliseconds for a multithreaded CPU version (16 threaded Intel(R) Xeon(R) CPU E5-2650 processsor). The CUDA based parallel implementation is described in detail with fine-grained comparison between the GPU and CPU implementations. By achieving nearly 8 fold speedup without performance degradation our work expands the applicability of the KAZE algorithm. Additionally, the strategies described here can prove useful for the GPU implementation of other nonlinear scale space based methods.
Multiagent Control of Self-reconfigurable Robots
Jun 20, 2000

We demonstrate how multiagent systems provide useful control techniques for modular self-reconfigurable (metamorphic) robots. Such robots consist of many modules that can move relative to each other, thereby changing the overall shape of the robot to suit different tasks. Multiagent control is particularly well-suited for tasks involving uncertain and changing environments. We illustrate this approach through simulation experiments of Proteo, a metamorphic robot system currently under development.
* 15 pages, 10 color figures, including low-resolution photos of prototype hardware