 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeySpot: Automating Service Key Detection for Digital Electrical Layout Plans in the Construction Industry
Aug 14, 2025Legacy floor plans, often preserved only as scanned documents, remain essential resources for architecture, urban planning, and facility management in the construction industry. However, the lack of machine-readable floor plans render large-scale interpretation both time-consuming and error-prone. Automated symbol spotting offers a scalable solution by enabling the identification of service key symbols directly from floor plans, supporting workflows such as cost estimation, infrastructure maintenance, and regulatory compliance. This work introduces a labelled Digitised Electrical Layout Plans (DELP) dataset comprising 45 scanned electrical layout plans annotated with 2,450 instances across 34 distinct service key classes. A systematic evaluation framework is proposed using pretrained object detection models for DELP dataset. Among the models benchmarked, YOLOv8 achieves the highest performance with a mean Average Precision (mAP) of 82.5\%. Using YOLOv8, we develop SkeySpot, a lightweight, open-source toolkit for real-time detection, classification, and quantification of electrical symbols. SkeySpot produces structured, standardised outputs that can be scaled up for interoperable building information workflows, ultimately enabling compatibility across downstream applications and regulatory platforms. By lowering dependency on proprietary CAD systems and reducing manual annotation effort, this approach makes the digitisation of electrical layouts more accessible to small and medium-sized enterprises (SMEs) in the construction industry, while supporting broader goals of standardisation, interoperability, and sustainability in the built environment.
Quantifying Spatial Domain Explanations in BCI using Earth Mover's Distance
May 02, 2024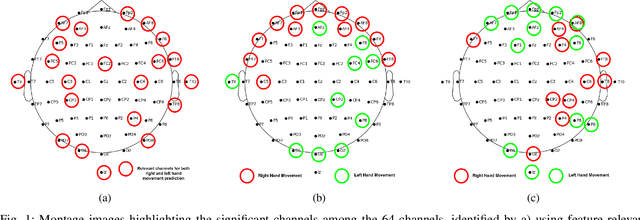
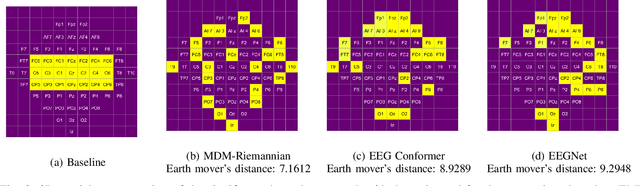
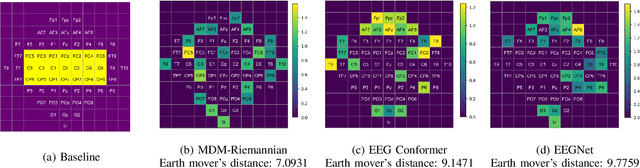
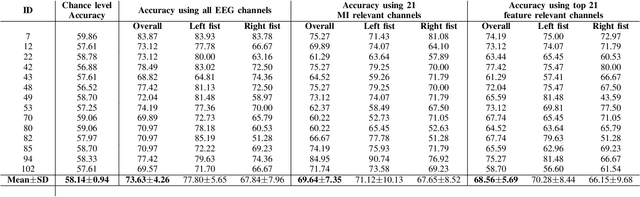
Brain-computer interface (BCI) systems facilitate unique communication between humans and computers, benefiting severely disabled individuals. Despite decades of research, BCIs are not fully integrated into clinical and commercial settings. It's crucial to assess and explain BCI performance, offering clear explanations for potential users to avoid frustration when it doesn't work as expected. This work investigates the efficacy of different deep learning and Riemannian geometry-based classification models in the context of motor imagery (MI) based BCI using electroencephalography (EEG). We then propose an optimal transport theory-based approach using earth mover's distance (EMD) to quantify the comparison of the feature relevance map with the domain knowledge of neuroscience. For this, we utilized explainable AI (XAI) techniques for generating feature relevance in the spatial domain to identify important channels for model outcomes. Three state-of-the-art models are implemented - 1) Riemannian geometry-based classifier, 2) EEGNet, and 3) EEG Conformer, and the observed trend in the model's accuracy across different architectures on the dataset correlates with the proposed feature relevance metrics. The models with diverse architectures perform significantly better when trained on channels relevant to motor imagery than data-driven channel selection. This work focuses attention on the necessity for interpretability and incorporating metrics beyond accuracy, underscores the value of combining domain knowledge and quantifying model interpretations with data-driven approaches in creating reliable and robust Brain-Computer Interfaces (BCIs).
Explainable artificial intelligence approaches for brain-computer interfaces: a review and design space
Dec 20, 2023This review paper provides an integrated perspective of Explainable Artificial Intelligence techniques applied to Brain-Computer Interfaces. BCIs use predictive models to interpret brain signals for various high-stake applications. However, achieving explainability in these complex models is challenging as it compromises accuracy. The field of XAI has emerged to address the need for explainability across various stakeholders, but there is a lack of an integrated perspective in XAI for BCI (XAI4BCI) literature. It is necessary to differentiate key concepts like explainability, interpretability, and understanding in this context and formulate a comprehensive framework. To understand the need of XAI for BCI, we pose six key research questions for a systematic review and meta-analysis, encompassing its purposes, applications, usability, and technical feasibility. We employ the PRISMA methodology -- preferred reporting items for systematic reviews and meta-analyses to review (n=1246) and analyze (n=84) studies published in 2015 and onwards for key insights. The results highlight that current research primarily focuses on interpretability for developers and researchers, aiming to justify outcomes and enhance model performance. We discuss the unique approaches, advantages, and limitations of XAI4BCI from the literature. We draw insights from philosophy, psychology, and social sciences. We propose a design space for XAI4BCI, considering the evolving need to visualize and investigate predictive model outcomes customised for various stakeholders in the BCI development and deployment lifecycle. This paper is the first to focus solely on reviewing XAI4BCI research articles. This systematic review and meta-analysis findings with the proposed design space prompt important discussions on establishing standards for BCI explanations, highlighting current limitations, and guiding the future of XAI in BCI.
Dataset Augmentation with Synthetic Images Improves Semantic Segmentation
Jun 26, 2018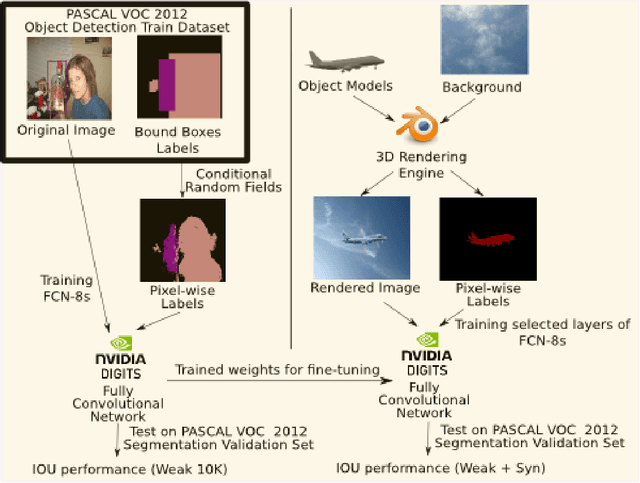
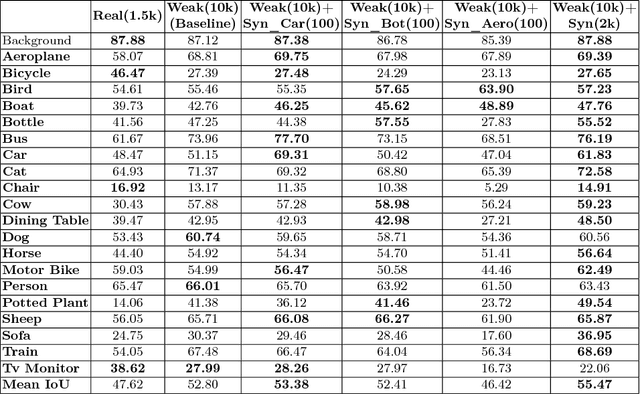


Although Deep Convolutional Neural Networks trained with strong pixel-level annotations have significantly pushed the performance in semantic segmentation, annotation efforts required for the creation of training data remains a roadblock for further improvements. We show that augmentation of the weakly annotated training dataset with synthetic images minimizes both the annotation efforts and also the cost of capturing images with sufficient variety. Evaluation on the PASCAL 2012 validation dataset shows an increase in mean IOU from 52.80% to 55.47% by adding just 100 synthetic images per object class. Our approach is thus a promising solution to the problems of annotation and dataset collection.