 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Temporal Ensembling for Learning with Noisy Labels
Sep 29, 2021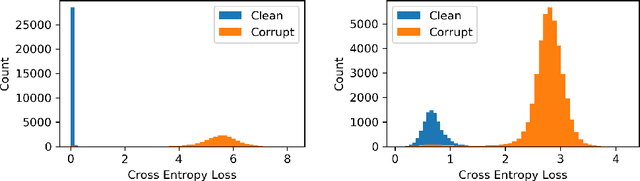
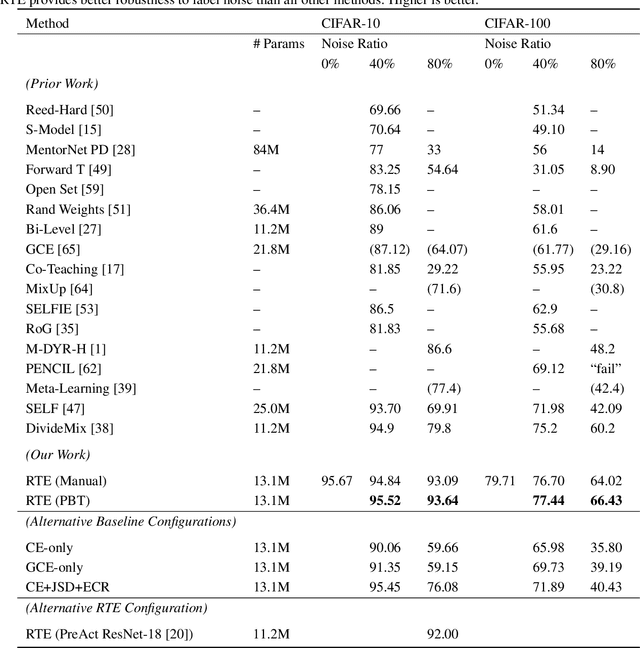
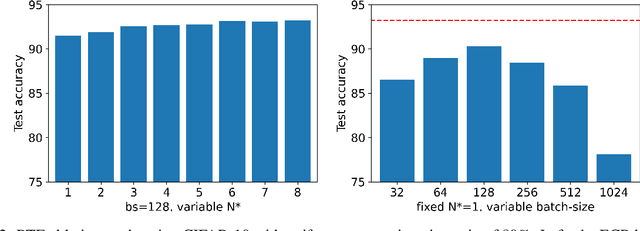
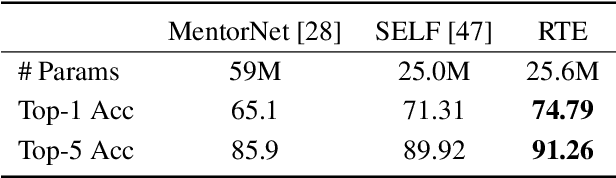
Successful training of deep neural networks with noisy labels is an essential capability as most real-world datasets contain some amount of mislabeled data. Left unmitigated, label noise can sharply degrade typical supervised learning approaches. In this paper, we present robust temporal ensembling (RTE), which combines robust loss with semi-supervised regularization methods to achieve noise-robust learning. We demonstrate that RTE achieves state-of-the-art performance across the CIFAR-10, CIFAR-100, ImageNet, WebVision, and Food-101N datasets, while forgoing the recent trend of label filtering and/or fixing. Finally, we show that RTE also retains competitive corruption robustness to unforeseen input noise using CIFAR-10-C, obtaining a mean corruption error (mCE) of 13.50% even in the presence of an 80% noise ratio, versus 26.9% mCE with standard methods on clean data.
Automated Surgical Activity Recognition with One Labeled Sequence
Jul 20, 2019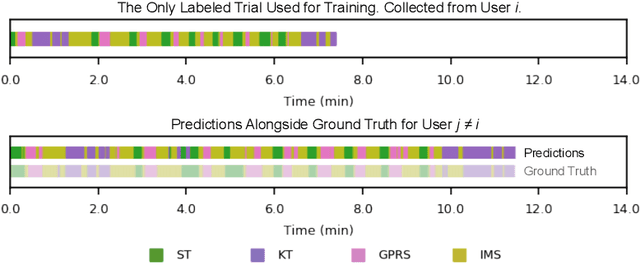
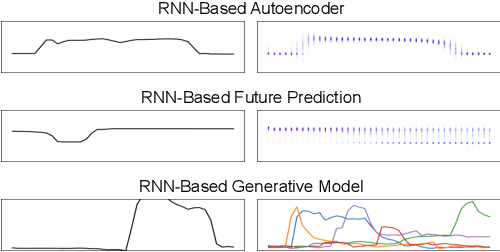
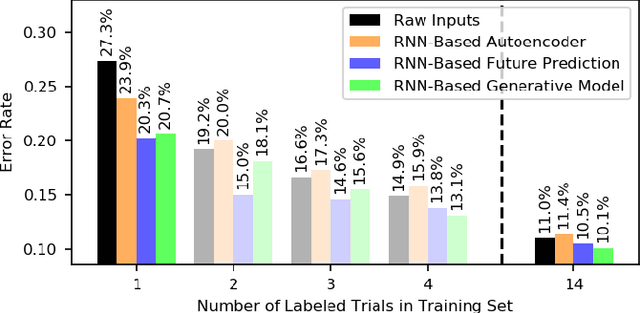
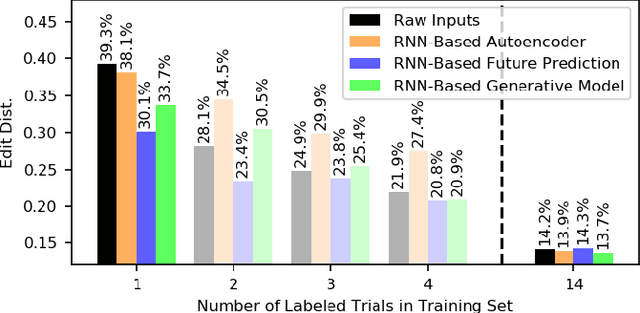
Prior work has demonstrated the feasibility of automated activity recognition in robot-assisted surgery from motion data. However, these efforts have assumed the availability of a large number of densely-annotated sequences, which must be provided manually by experts. This process is tedious, expensive, and error-prone. In this paper, we present the first analysis under the assumption of scarce annotations, where as little as one annotated sequence is available for training. We demonstrate feasibility of automated recognition in this challenging setting, and we show that learning representations in an unsupervised fashion, before the recognition phase, leads to significant gains in performance. In addition, our paper poses a new challenge to the community: how much further can we push performance in this important yet relatively unexplored regime?
Unsupervised Learning for Surgical Motion by Learning to Predict the Future
Jun 08, 2018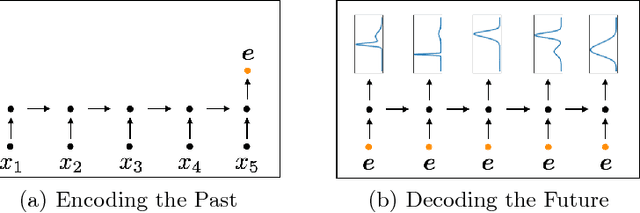
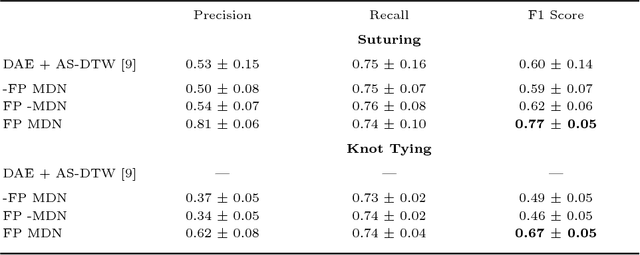
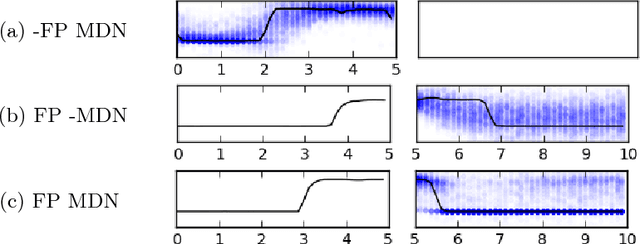

We show that it is possible to learn meaningful representations of surgical motion, without supervision, by learning to predict the future. An architecture that combines an RNN encoder-decoder and mixture density networks (MDNs) is developed to model the conditional distribution over future motion given past motion. We show that the learned encodings naturally cluster according to high-level activities, and we demonstrate the usefulness of these learned encodings in the context of information retrieval, where a database of surgical motion is searched for suturing activity using a motion-based query. Future prediction with MDNs is found to significantly outperform simpler baselines as well as the best previously-published result for this task, advancing state-of-the-art performance from an F1 score of 0.60 +- 0.14 to 0.77 +- 0.05.
Analyzing and Exploiting NARX Recurrent Neural Networks for Long-Term Dependencies
Apr 20, 2018
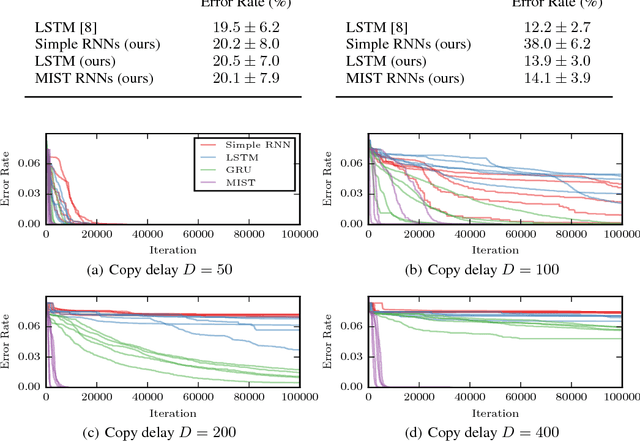


Recurrent neural networks (RNNs) have achieved state-of-the-art performance on many diverse tasks, from machine translation to surgical activity recognition, yet training RNNs to capture long-term dependencies remains difficult. To date, the vast majority of successful RNN architectures alleviate this problem using nearly-additive connections between states, as introduced by long short-term memory (LSTM). We take an orthogonal approach and introduce MIST RNNs, a NARX RNN architecture that allows direct connections from the very distant past. We show that MIST RNNs 1) exhibit superior vanishing-gradient properties in comparison to LSTM and previously-proposed NARX RNNs; 2) are far more efficient than previously-proposed NARX RNN architectures, requiring even fewer computations than LSTM; and 3) improve performance substantially over LSTM and Clockwork RNNs on tasks requiring very long-term dependencies.
Learning in an Uncertain World: Representing Ambiguity Through Multiple Hypotheses
Aug 22, 2017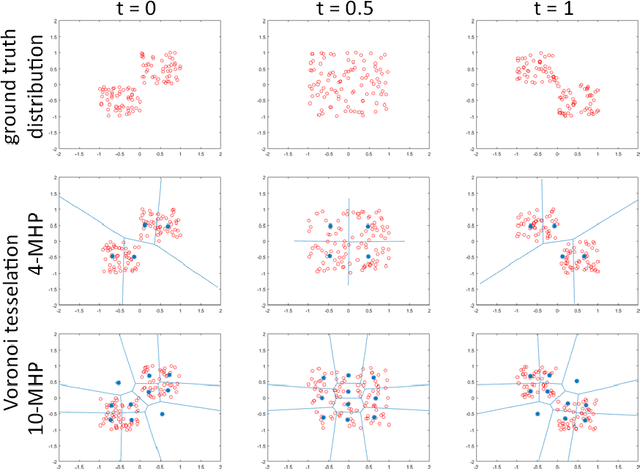

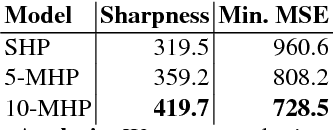
Many prediction tasks contain uncertainty. In some cases, uncertainty is inherent in the task itself. In future prediction, for example, many distinct outcomes are equally valid. In other cases, uncertainty arises from the way data is labeled. For example, in object detection, many objects of interest often go unlabeled, and in human pose estimation, occluded joints are often labeled with ambiguous values. In this work we focus on a principled approach for handling such scenarios. In particular, we propose a framework for reformulating existing single-prediction models as multiple hypothesis prediction (MHP) models and an associated meta loss and optimization procedure to train them. To demonstrate our approach, we consider four diverse applications: human pose estimation, future prediction, image classification and segmentation. We find that MHP models outperform their single-hypothesis counterparts in all cases, and that MHP models simultaneously expose valuable insights into the variability of predictions.
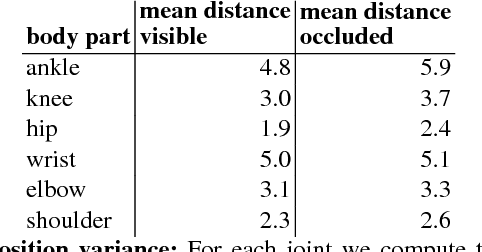
Long Short-Term Memory Kalman Filters:Recurrent Neural Estimators for Pose Regularization
Aug 06, 2017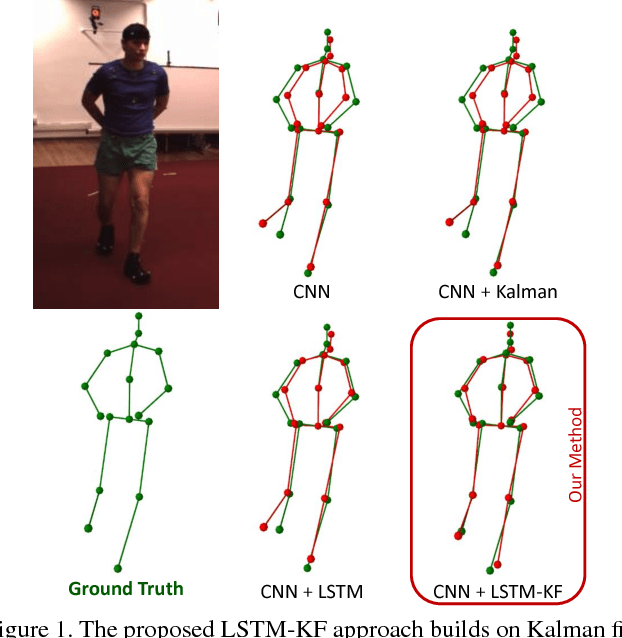
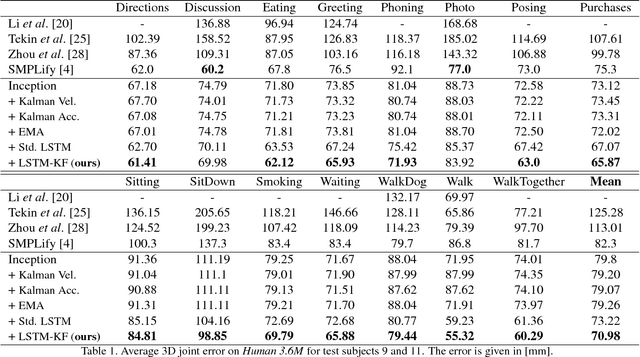
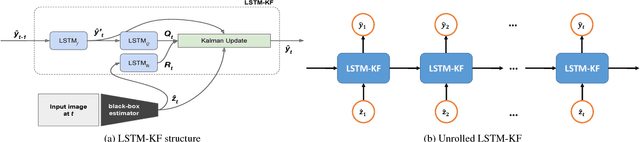
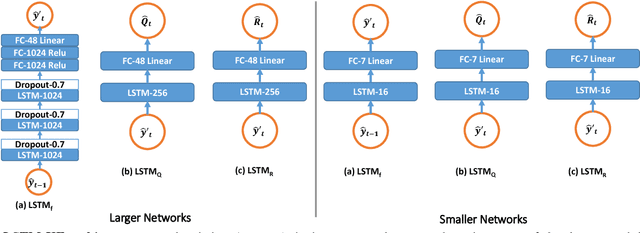
One-shot pose estimation for tasks such as body joint localization, camera pose estimation, and object tracking are generally noisy, and temporal filters have been extensively used for regularization. One of the most widely-used methods is the Kalman filter, which is both extremely simple and general. However, Kalman filters require a motion model and measurement model to be specified a priori, which burdens the modeler and simultaneously demands that we use explicit models that are often only crude approximations of reality. For example, in the pose-estimation tasks mentioned above, it is common to use motion models that assume constant velocity or constant acceleration, and we believe that these simplified representations are severely inhibitive. In this work, we propose to instead learn rich, dynamic representations of the motion and noise models. In particular, we propose learning these models from data using long short term memory, which allows representations that depend on all previous observations and all previous states. We evaluate our method using three of the most popular pose estimation tasks in computer vision, and in all cases we obtain state-of-the-art performance.
Recognizing Surgical Activities with Recurrent Neural Networks
Jun 22, 2016

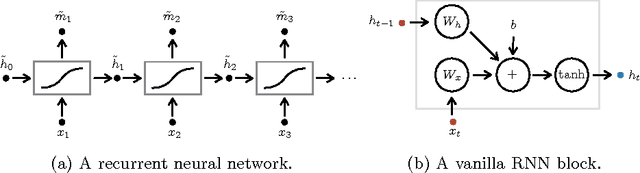
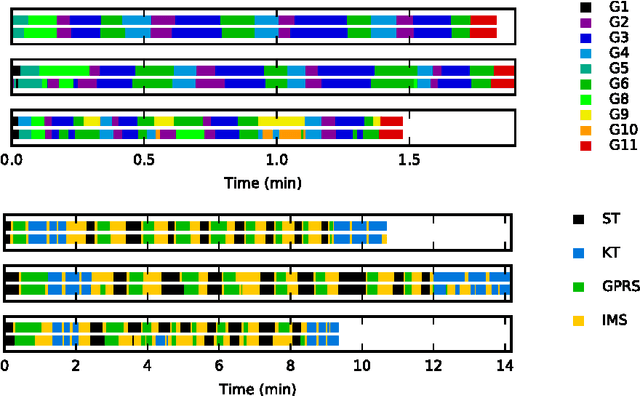
We apply recurrent neural networks to the task of recognizing surgical activities from robot kinematics. Prior work in this area focuses on recognizing short, low-level activities, or gestures, and has been based on variants of hidden Markov models and conditional random fields. In contrast, we work on recognizing both gestures and longer, higher-level activites, or maneuvers, and we model the mapping from kinematics to gestures/maneuvers with recurrent neural networks. To our knowledge, we are the first to apply recurrent neural networks to this task. Using a single model and a single set of hyperparameters, we match state-of-the-art performance for gesture recognition and advance state-of-the-art performance for maneuver recognition, in terms of both accuracy and edit distance. Code is available at https://github.com/rdipietro/miccai-2016-surgical-activity-rec .