 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Surgical Activity Recognition with One Labeled Sequence
Paper and Code
Jul 20, 2019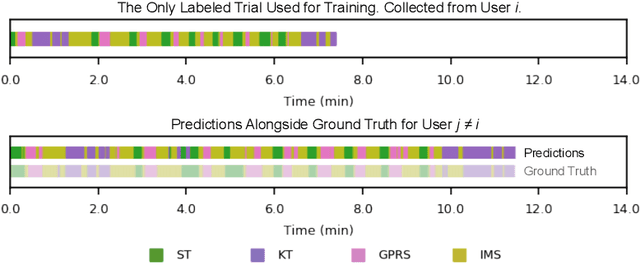
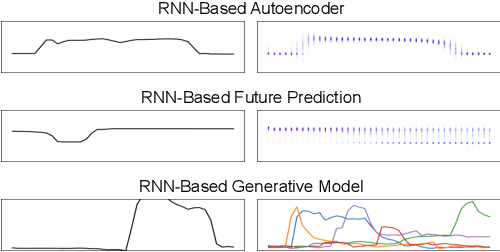
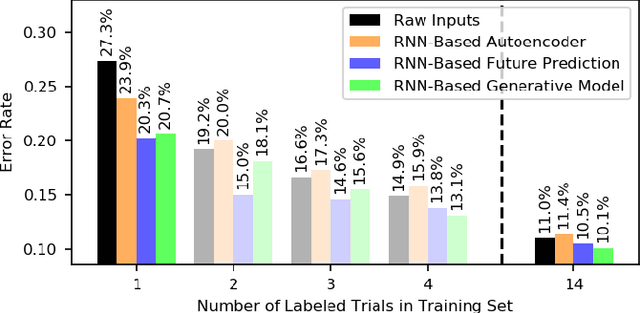
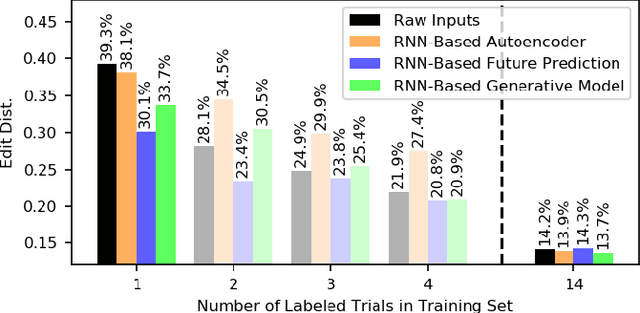
Prior work has demonstrated the feasibility of automated activity recognition in robot-assisted surgery from motion data. However, these efforts have assumed the availability of a large number of densely-annotated sequences, which must be provided manually by experts. This process is tedious, expensive, and error-prone. In this paper, we present the first analysis under the assumption of scarce annotations, where as little as one annotated sequence is available for training. We demonstrate feasibility of automated recognition in this challenging setting, and we show that learning representations in an unsupervised fashion, before the recognition phase, leads to significant gains in performance. In addition, our paper poses a new challenge to the community: how much further can we push performance in this important yet relatively unexplored regime?