 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning for Surgical Motion by Learning to Predict the Future
Paper and Code
Jun 08, 2018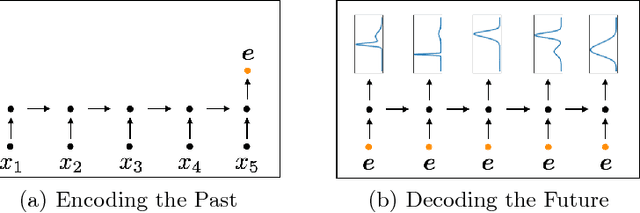
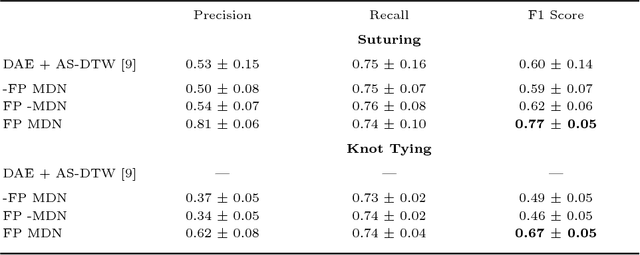
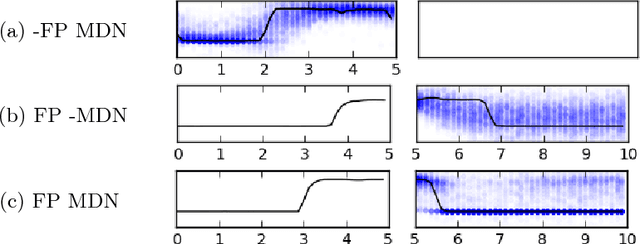

We show that it is possible to learn meaningful representations of surgical motion, without supervision, by learning to predict the future. An architecture that combines an RNN encoder-decoder and mixture density networks (MDNs) is developed to model the conditional distribution over future motion given past motion. We show that the learned encodings naturally cluster according to high-level activities, and we demonstrate the usefulness of these learned encodings in the context of information retrieval, where a database of surgical motion is searched for suturing activity using a motion-based query. Future prediction with MDNs is found to significantly outperform simpler baselines as well as the best previously-published result for this task, advancing state-of-the-art performance from an F1 score of 0.60 +- 0.14 to 0.77 +- 0.05.