 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learned Full-3D Object Completion from Single View
Aug 21, 2018
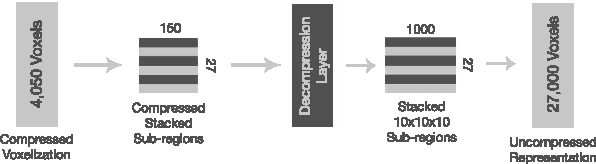

3D geometry is a very informative cue when interacting with and navigating an environment. This writing proposes a new approach to 3D reconstruction and scene understanding, which implicitly learns 3D geometry from depth maps pairing a deep convolutional neural network architecture with an auto-encoder. A data set of synthetic depth views and voxelized 3D representations is built based on ModelNet, a large-scale collection of CAD models, to train networks. The proposed method offers a significant advantage over current, explicit reconstruction methods in that it learns key geometric features offline and makes use of those to predict the most probable reconstruction of an unseen object. The relatively small network, consisting of roughly 4 million weights, achieves a 92.9% reconstruction accuracy at a 30x30x30 resolution through the use of a pre-trained decompression layer. This is roughly 1/4 the weights of the current leading network. The fast execution time of the model makes it suitable for real-time applications.
Long Short-Term Memory Kalman Filters:Recurrent Neural Estimators for Pose Regularization
Aug 06, 2017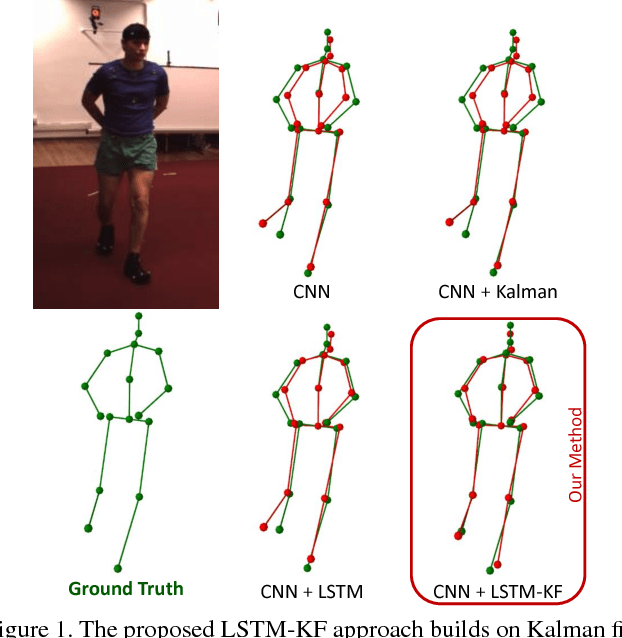
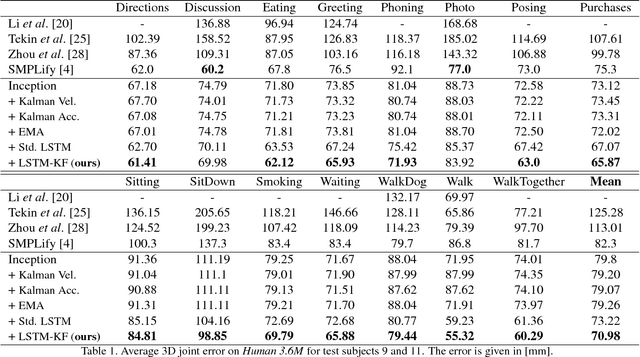
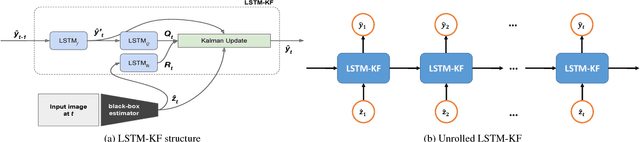
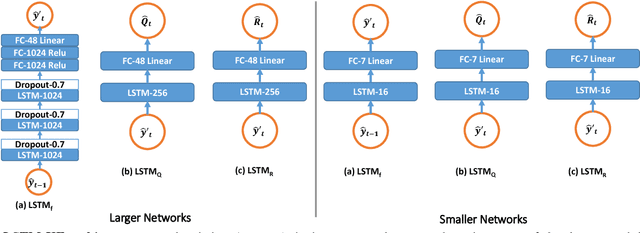
One-shot pose estimation for tasks such as body joint localization, camera pose estimation, and object tracking are generally noisy, and temporal filters have been extensively used for regularization. One of the most widely-used methods is the Kalman filter, which is both extremely simple and general. However, Kalman filters require a motion model and measurement model to be specified a priori, which burdens the modeler and simultaneously demands that we use explicit models that are often only crude approximations of reality. For example, in the pose-estimation tasks mentioned above, it is common to use motion models that assume constant velocity or constant acceleration, and we believe that these simplified representations are severely inhibitive. In this work, we propose to instead learn rich, dynamic representations of the motion and noise models. In particular, we propose learning these models from data using long short term memory, which allows representations that depend on all previous observations and all previous states. We evaluate our method using three of the most popular pose estimation tasks in computer vision, and in all cases we obtain state-of-the-art performance.