 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learned Full-3D Object Completion from Single View
Paper and Code
Aug 21, 2018
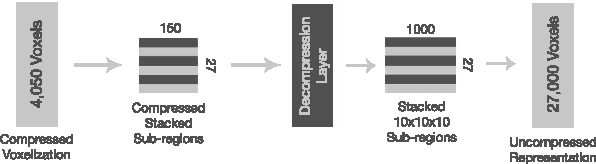

3D geometry is a very informative cue when interacting with and navigating an environment. This writing proposes a new approach to 3D reconstruction and scene understanding, which implicitly learns 3D geometry from depth maps pairing a deep convolutional neural network architecture with an auto-encoder. A data set of synthetic depth views and voxelized 3D representations is built based on ModelNet, a large-scale collection of CAD models, to train networks. The proposed method offers a significant advantage over current, explicit reconstruction methods in that it learns key geometric features offline and makes use of those to predict the most probable reconstruction of an unseen object. The relatively small network, consisting of roughly 4 million weights, achieves a 92.9% reconstruction accuracy at a 30x30x30 resolution through the use of a pre-trained decompression layer. This is roughly 1/4 the weights of the current leading network. The fast execution time of the model makes it suitable for real-time applications.