 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking
Oct 25, 2023Recently, large language models (LLMs) have exhibited significant progress in language understanding and generation. By leveraging textual features, customized LLMs are also applied for recommendation and demonstrate improvements across diverse recommendation scenarios. Yet the majority of existing methods perform training-free recommendation that heavily relies on pretrained knowledge (e.g., movie recommendation). In addition, inference on LLMs is slow due to autoregressive generation, rendering existing methods less effective for real-time recommendation. As such, we propose a two-stage framework using large language models for ranking-based recommendation (LlamaRec). In particular, we use small-scale sequential recommenders to retrieve candidates based on the user interaction history. Then, both history and retrieved items are fed to the LLM in text via a carefully designed prompt template. Instead of generating next-item titles, we adopt a verbalizer-based approach that transforms output logits into probability distributions over the candidate items. Therefore, the proposed LlamaRec can efficiently rank items without generating long text. To validate the effectiveness of the proposed framework, we compare against state-of-the-art baseline methods on benchmark datasets. Our experimental results demonstrate the performance of LlamaRec, which consistently achieves superior performance in both recommendation performance and efficiency.
Synthetic Data and Simulators for Recommendation Systems: Current State and Future Directions
Dec 21, 2021Synthetic data and simulators have the potential to markedly improve the performance and robustness of recommendation systems. These approaches have already had a beneficial impact in other machine-learning driven fields. We identify and discuss a key trade-off between data fidelity and privacy in the past work on synthetic data and simulators for recommendation systems. For the important use case of predicting algorithm rankings on real data from synthetic data, we provide motivation and current successes versus limitations. Finally we outline a number of exciting future directions for recommendation systems that we believe deserve further attention and work, including mixing real and synthetic data, feedback in dataset generation, robust simulations, and privacy-preserving methods.
Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation
Jul 11, 2021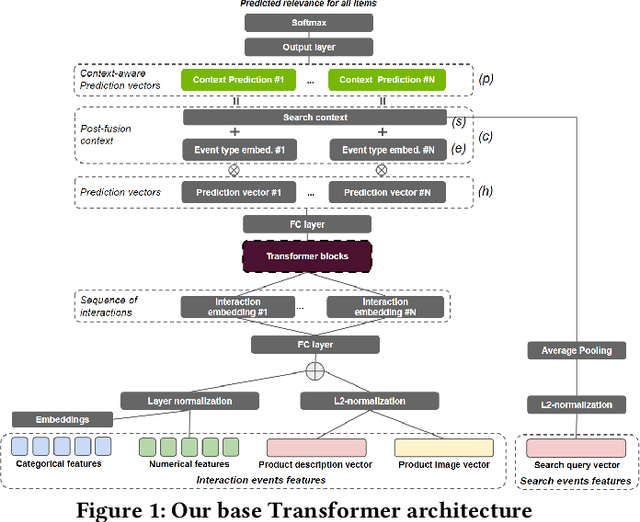
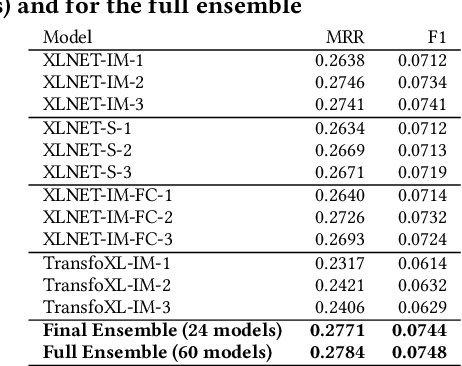
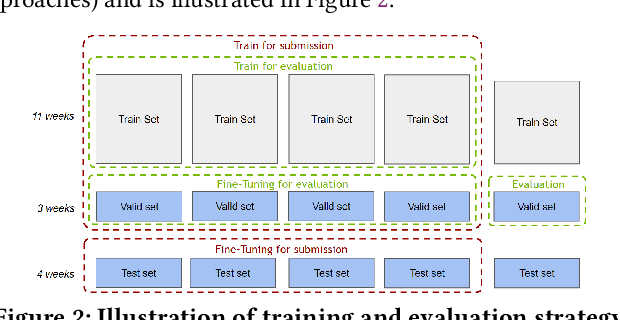
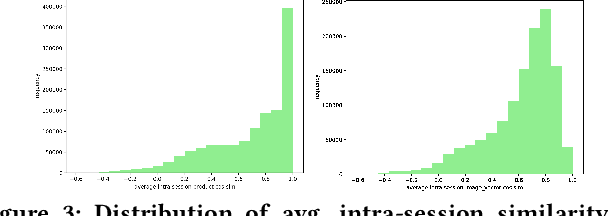
Session-based recommendation is an important task for e-commerce services, where a large number of users browse anonymously or may have very distinct interests for different sessions. In this paper we present one of the winning solutions for the Recommendation task of the SIGIR 2021 Workshop on E-commerce Data Challenge. Our solution was inspired by NLP techniques and consists of an ensemble of two Transformer architectures - Transformer-XL and XLNet - trained with autoregressive and autoencoding approaches. To leverage most of the rich dataset made available for the competition, we describe how we prepared multi-model features by combining tabular events with textual and image vectors. We also present a model prediction analysis to better understand the effectiveness of our architectures for the session-based recommendation.