 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaRec: Two-Stage Recommendation using Large Language Models for Ranking
Oct 25, 2023Recently, large language models (LLMs) have exhibited significant progress in language understanding and generation. By leveraging textual features, customized LLMs are also applied for recommendation and demonstrate improvements across diverse recommendation scenarios. Yet the majority of existing methods perform training-free recommendation that heavily relies on pretrained knowledge (e.g., movie recommendation). In addition, inference on LLMs is slow due to autoregressive generation, rendering existing methods less effective for real-time recommendation. As such, we propose a two-stage framework using large language models for ranking-based recommendation (LlamaRec). In particular, we use small-scale sequential recommenders to retrieve candidates based on the user interaction history. Then, both history and retrieved items are fed to the LLM in text via a carefully designed prompt template. Instead of generating next-item titles, we adopt a verbalizer-based approach that transforms output logits into probability distributions over the candidate items. Therefore, the proposed LlamaRec can efficiently rank items without generating long text. To validate the effectiveness of the proposed framework, we compare against state-of-the-art baseline methods on benchmark datasets. Our experimental results demonstrate the performance of LlamaRec, which consistently achieves superior performance in both recommendation performance and efficiency.
Synthetic Data and Simulators for Recommendation Systems: Current State and Future Directions
Dec 21, 2021Synthetic data and simulators have the potential to markedly improve the performance and robustness of recommendation systems. These approaches have already had a beneficial impact in other machine-learning driven fields. We identify and discuss a key trade-off between data fidelity and privacy in the past work on synthetic data and simulators for recommendation systems. For the important use case of predicting algorithm rankings on real data from synthetic data, we provide motivation and current successes versus limitations. Finally we outline a number of exciting future directions for recommendation systems that we believe deserve further attention and work, including mixing real and synthetic data, feedback in dataset generation, robust simulations, and privacy-preserving methods.
CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]
Dec 29, 2019![Figure 1 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F4-Table1-1.png&w=640&q=75)
![Figure 3 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F4-Figure3-1.png&w=640&q=75)
Recommender Systems (RS) have became a popular research topic and, since 2016, Deep Learning methods and techniques have been increasingly explored in this area. News RS are aimed to personalize users experiences and help them discover relevant articles from a large and dynamic search space. The main contribution of this research was named CHAMELEON, a Deep Learning meta-architecture designed to tackle the specific challenges of news recommendation. It consists of a modular reference architecture which can be instantiated using different neural building blocks. As information about users' past interactions is scarce in the news domain, the user context can be leveraged to deal with the user cold-start problem. Articles' content is also important to tackle the item cold-start problem. Additionally, the temporal decay of items (articles) relevance is very accelerated in the news domain. Furthermore, external breaking events may temporally attract global readership attention, a phenomenon generally known as concept drift in machine learning. All those characteristics are explicitly modeled on this research by a contextual hybrid session-based recommendation approach using Recurrent Neural Networks. The task addressed by this research is session-based news recommendation, i.e., next-click prediction using only information available in the current user session. A method is proposed for a realistic temporal offline evaluation of such task, replaying the stream of user clicks and fresh articles being continuously published in a news portal. Experiments performed with two large datasets have shown the effectiveness of the CHAMELEON for news recommendation on many quality factors such as accuracy, item coverage, novelty, and reduced item cold-start problem, when compared to other traditional and state-of-the-art session-based recommendation algorithms.
Contextual Hybrid Session-based News Recommendation with Recurrent Neural Networks
Apr 15, 2019

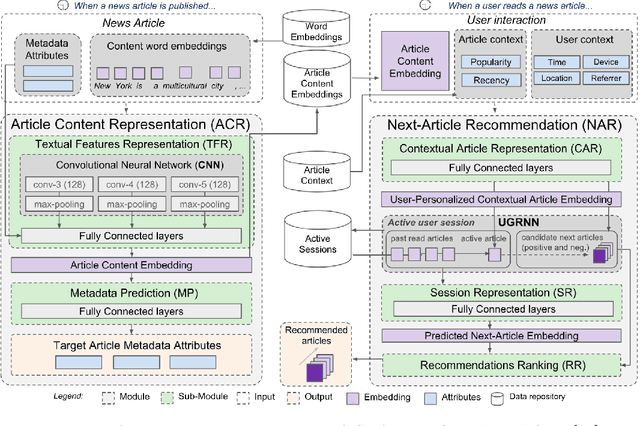
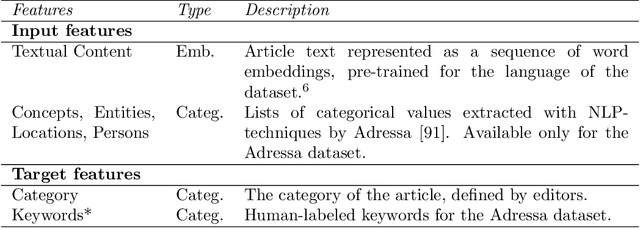
Recommender systems help users deal with information overload by providing tailored item suggestions to them. The recommendation of news is often considered to be challenging, since the relevance of an article for a user can depend on a variety of factors, including the user's short-term reading interests, the reader's context, or the recency or popularity of an article. Previous work has shown that the use of Recurrent Neural Networks is promising for the next-in-session prediction task, but has certain limitations when only recorded item click sequences are used as input. In this work, we present a hybrid, deep learning based approach for session-based news recommendation that is able to leverage a variety of information types. We evaluated our approach on two public datasets, using a temporal evaluation protocol that simulates the dynamics of a news portal in a realistic way. Our results confirm the benefits of considering additional types of information, including article popularity and recency, in the proposed way, resulting in significantly higher recommendation accuracy and catalog coverage than other session-based algorithms. Additional experiments show that the proposed parameterizable loss function used in our method also allows us to balance two usually conflicting quality factors, accuracy and novelty. Keywords: News Recommender Systems, Session-based Recommendation, Artificial Neural Networks, Context-awareness, Hybridization