 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFold-CP: A Context Parallelism Framework for Biomolecular Modeling
Mar 16, 2026Understanding cellular machinery requires atomic-scale reconstruction of large biomolecular assemblies. However, predicting the structures of these systems has been constrained by hardware memory requirements of models like AlphaFold 3, imposing a practical ceiling of a few thousand residues that can be processed on a single GPU. Here we present NVIDIA BioNeMo Fold-CP, a context parallelism framework that overcomes this barrier by distributing the inference and training pipelines of co-folding models across multiple GPUs. We use the Boltz models as open source reference architectures and implement custom multidimensional primitives that efficiently parallelize both the dense triangular updates and the irregular, data-dependent pattern of window-batched local attention. Our approach achieves efficient memory scaling; for an N-token input distributed across P GPUs, per-device memory scales as $O(N^2/P)$, enabling the structure prediction of assemblies exceeding 30,000 residues on 64 NVIDIA B300 GPUs. We demonstrate the scientific utility of this approach through successful developer use cases: Fold-CP enabled the scoring of over 90% of Comprehensive Resource of Mammalian protein complexes (CORUM) database, as well as folding of disease-relevant PI4KA lipid kinase complex bound to an intrinsically disordered region without cropping. By providing a scalable pathway for modeling massive systems with full global context, Fold-CP represents a significant step toward the realization of a virtual cell.
BioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
Partial Product Aware Machine Learning on DNA-Encoded Libraries
May 16, 2022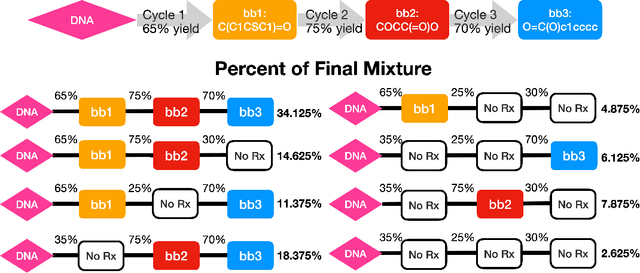
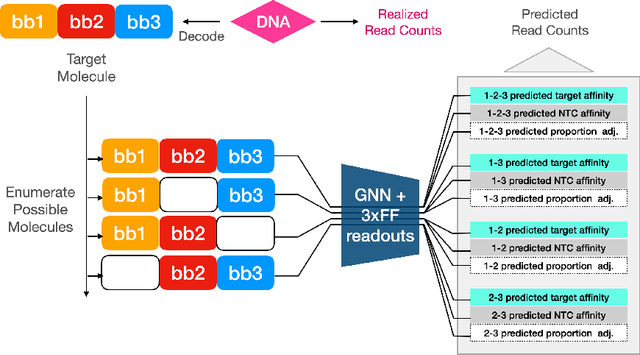
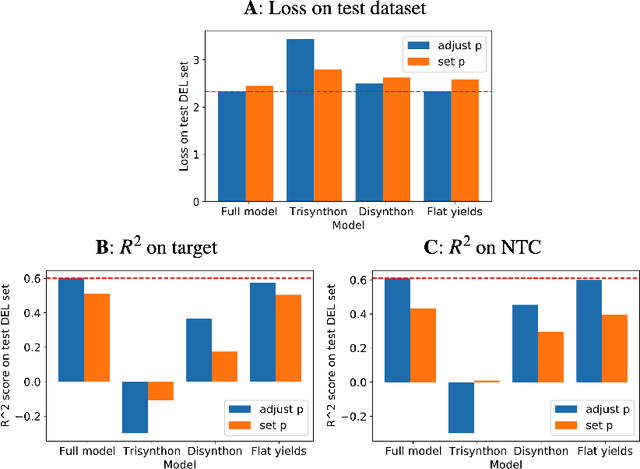
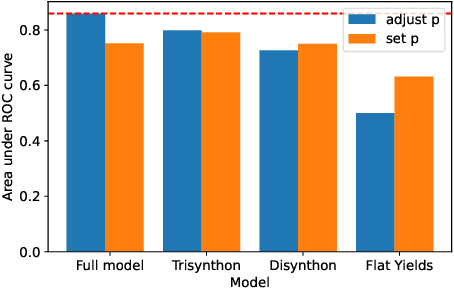
DNA encoded libraries (DELs) are used for rapid large-scale screening of small molecules against a protein target. These combinatorial libraries are built through several cycles of chemistry and DNA ligation, producing large sets of DNA-tagged molecules. Training machine learning models on DEL data has been shown to be effective at predicting molecules of interest dissimilar from those in the original DEL. Machine learning chemical property prediction approaches rely on the assumption that the property of interest is linked to a single chemical structure. In the context of DNA-encoded libraries, this is equivalent to assuming that every chemical reaction fully yields the desired product. However, in practice, multi-step chemical synthesis sometimes generates partial molecules. Each unique DNA tag in a DEL therefore corresponds to a set of possible molecules. Here, we leverage reaction yield data to enumerate the set of possible molecules corresponding to a given DNA tag. This paper demonstrates that training a custom GNN on this richer dataset improves accuracy and generalization performance.