 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning about Reasoning: BAPO Bounds on Chain-of-Thought Token Complexity in LLMs
Feb 02, 2026Inference-time scaling via chain-of-thought (CoT) reasoning is a major driver of state-of-the-art LLM performance, but it comes with substantial latency and compute costs. We address a fundamental theoretical question: how many reasoning tokens are required to solve a problem as input size grows? By extending the bounded attention prefix oracle (BAPO) model--an abstraction of LLMs that quantifies the information flow required to solve a task--we prove lower bounds on the CoT tokens required for three canonical BAPO-hard tasks: binary majority, triplet matching, and graph reachability. We show that each requires $Ω(n)$ reasoning tokens when the input size is $n$. We complement these results with matching or near-matching upper bounds via explicit constructions. Finally, our experiments with frontier reasoning models show approximately linear reasoning token scaling on these tasks and failures when constrained to smaller reasoning budgets, consistent with our theoretical lower bounds. Together, our results identify fundamental bottlenecks in inference-time compute through CoT and offer a principled tool for analyzing optimal reasoning length.
A Course Correction in Steerability Evaluation: Revealing Miscalibration and Side Effects in LLMs
May 27, 2025Despite advances in large language models (LLMs) on reasoning and instruction-following benchmarks, it remains unclear whether they can reliably produce outputs aligned with a broad variety of user goals, a concept we refer to as steerability. The abundance of methods proposed to modify LLM behavior makes it unclear whether current LLMs are already steerable, or require further intervention. In particular, LLMs may exhibit (i) poor coverage, where rare user goals are underrepresented; (ii) miscalibration, where models overshoot requests; and (iii) side effects, where changes to one dimension of text inadvertently affect others. To systematically evaluate these failures, we introduce a framework based on a multi-dimensional goal space that models user goals and LLM outputs as vectors with dimensions corresponding to text attributes (e.g., reading difficulty). Applied to a text-rewriting task, we find that current LLMs struggle with steerability, as side effects are persistent. Interventions to improve steerability, such as prompt engineering, best-of-$N$ sampling, and reinforcement learning fine-tuning, have varying effectiveness, yet side effects remain problematic. Our findings suggest that even strong LLMs struggle with steerability, and existing alignment strategies may be insufficient. We open-source our steerability evaluation framework at https://github.com/MLD3/steerability.
Lost in Transmission: When and Why LLMs Fail to Reason Globally
May 13, 2025Despite their many successes, transformer-based large language models (LLMs) continue to struggle with tasks that require complex reasoning over large parts of their input. We argue that these failures arise due to capacity limits on the accurate flow of information within LLMs. To formalize this issue, we introduce the bounded attention prefix oracle (BAPO) model, a new computational framework that models bandwidth constraints on attention heads, the mechanism for internal communication in LLMs. We show that several important reasoning problems like graph reachability require high communication bandwidth for BAPOs to solve; we call these problems BAPO-hard. Our experiments corroborate our theoretical predictions: GPT-4, Claude, and Gemini succeed on BAPO-easy tasks and fail even on relatively small BAPO-hard tasks. BAPOs also reveal another benefit of chain of thought (CoT): we prove that breaking down a task using CoT can turn any BAPO-hard problem into a BAPO-easy one. Our results offer principled explanations for key LLM failures and suggest directions for architectures and inference methods that mitigate bandwidth limits.
On Overcoming Miscalibrated Conversational Priors in LLM-based Chatbots
Jun 01, 2024

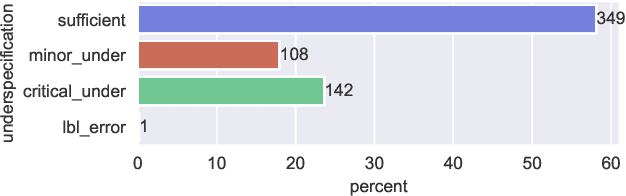

We explore the use of Large Language Model (LLM-based) chatbots to power recommender systems. We observe that the chatbots respond poorly when they encounter under-specified requests (e.g., they make incorrect assumptions, hedge with a long response, or refuse to answer). We conjecture that such miscalibrated response tendencies (i.e., conversational priors) can be attributed to LLM fine-tuning using annotators -- single-turn annotations may not capture multi-turn conversation utility, and the annotators' preferences may not even be representative of users interacting with a recommender system. We first analyze public LLM chat logs to conclude that query under-specification is common. Next, we study synthetic recommendation problems with configurable latent item utilities and frame them as Partially Observed Decision Processes (PODP). We find that pre-trained LLMs can be sub-optimal for PODPs and derive better policies that clarify under-specified queries when appropriate. Then, we re-calibrate LLMs by prompting them with learned control messages to approximate the improved policy. Finally, we show empirically that our lightweight learning approach effectively uses logged conversation data to re-calibrate the response strategies of LLM-based chatbots for recommendation tasks.
Prompts As Programs: A Structure-Aware Approach to Efficient Compile-Time Prompt Optimization
Apr 02, 2024Large language models (LLMs) can now handle longer and more complex inputs, which facilitate the use of more elaborate prompts. However, prompts often require some tuning to improve performance for deployment. Recent work has proposed automatic prompt optimization methods, but as prompt complexity and LLM strength increase, many prompt optimization techniques are no longer sufficient and a new approach is needed to optimize {\em meta prompt programs}. To address this, we introduce SAMMO, a framework for {\em compile-time} optimizations of metaprompt programs, which represent prompts as structured objects that allows for a rich set of transformations that can be searched over during optimization. We show that SAMMO generalizes previous methods and improves the performance of complex prompts on (1) instruction tuning, (2) RAG pipeline tuning, and (3) prompt compression, across several different LLMs. We make all code available open-source at https://github.com/microsoft/sammo .
When Newer is Not Better: Does Deep Learning Really Benefit Recommendation From Implicit Feedback?
May 02, 2023In recent years, neural models have been repeatedly touted to exhibit state-of-the-art performance in recommendation. Nevertheless, multiple recent studies have revealed that the reported state-of-the-art results of many neural recommendation models cannot be reliably replicated. A primary reason is that existing evaluations are performed under various inconsistent protocols. Correspondingly, these replicability issues make it difficult to understand how much benefit we can actually gain from these neural models. It then becomes clear that a fair and comprehensive performance comparison between traditional and neural models is needed. Motivated by these issues, we perform a large-scale, systematic study to compare recent neural recommendation models against traditional ones in top-n recommendation from implicit data. We propose a set of evaluation strategies for measuring memorization performance, generalization performance, and subgroup-specific performance of recommendation models. We conduct extensive experiments with 13 popular recommendation models (including two neural models and 11 traditional ones as baselines) on nine commonly used datasets. Our experiments demonstrate that even with extensive hyper-parameter searches, neural models do not dominate traditional models in all aspects, e.g., they fare worse in terms of average HitRate. We further find that there are areas where neural models seem to outperform non-neural models, for example, in recommendation diversity and robustness between different subgroups of users and items. Our work illuminates the relative advantages and disadvantages of neural models in recommendation and is therefore an important step towards building better recommender systems.
Situating Recommender Systems in Practice: Towards Inductive Learning and Incremental Updates
Nov 11, 2022With information systems becoming larger scale, recommendation systems are a topic of growing interest in machine learning research and industry. Even though progress on improving model design has been rapid in research, we argue that many advances fail to translate into practice because of two limiting assumptions. First, most approaches focus on a transductive learning setting which cannot handle unseen users or items and second, many existing methods are developed for static settings that cannot incorporate new data as it becomes available. We argue that these are largely impractical assumptions on real-world platforms where new user interactions happen in real time. In this survey paper, we formalize both concepts and contextualize recommender systems work from the last six years. We then discuss why and how future work should move towards inductive learning and incremental updates for recommendation model design and evaluation. In addition, we present best practices and fundamental open challenges for future research.
Where Do We Go From Here? Guidelines For Offline Recommender Evaluation
Nov 02, 2022Various studies in recent years have pointed out large issues in the offline evaluation of recommender systems, making it difficult to assess whether true progress has been made. However, there has been little research into what set of practices should serve as a starting point during experimentation. In this paper, we examine four larger issues in recommender system research regarding uncertainty estimation, generalization, hyperparameter optimization and dataset pre-processing in more detail to arrive at a set of guidelines. We present a TrainRec, a lightweight and flexible toolkit for offline training and evaluation of recommender systems that implements these guidelines. Different from other frameworks, TrainRec is a toolkit that focuses on experimentation alone, offering flexible modules that can be can be used together or in isolation. Finally, we demonstrate TrainRec's usefulness by evaluating a diverse set of twelve baselines across ten datasets. Our results show that (i) many results on smaller datasets are likely not statistically significant, (ii) there are at least three baselines that perform well on most datasets and should be considered in future experiments, and (iii) improved uncertainty quantification (via nested CV and statistical testing) rules out some reported differences between linear and neural methods. Given these results, we advocate that future research should standardize evaluation using our suggested guidelines.
EvalRS: a Rounded Evaluation of Recommender Systems
Jul 12, 2022
Much of the complexity of Recommender Systems (RSs) comes from the fact that they are used as part of more complex applications and affect user experience through a varied range of user interfaces. However, research focused almost exclusively on the ability of RSs to produce accurate item rankings while giving little attention to the evaluation of RS behavior in real-world scenarios. Such narrow focus has limited the capacity of RSs to have a lasting impact in the real world and makes them vulnerable to undesired behavior, such as reinforcing data biases. We propose EvalRS as a new type of challenge, in order to foster this discussion among practitioners and build in the open new methodologies for testing RSs "in the wild".
Lightweight Compositional Embeddings for Incremental Streaming Recommendation
Feb 04, 2022



Most work in graph-based recommender systems considers a {\em static} setting where all information about test nodes (i.e., users and items) is available upfront at training time. However, this static setting makes little sense for many real-world applications where data comes in continuously as a stream of new edges and nodes, and one has to update model predictions incrementally to reflect the latest state. To fully capitalize on the newly available data in the stream, recent graph-based recommendation models would need to be repeatedly retrained, which is infeasible in practice. In this paper, we study the graph-based streaming recommendation setting and propose a compositional recommendation model -- Lightweight Compositional Embedding (LCE) -- that supports incremental updates under low computational cost. Instead of learning explicit embeddings for the full set of nodes, LCE learns explicit embeddings for only a subset of nodes and represents the other nodes {\em implicitly}, through a composition function based on their interactions in the graph. This provides an effective, yet efficient, means to leverage streaming graph data when one node type (e.g., items) is more amenable to static representation. We conduct an extensive empirical study to compare LCE to a set of competitive baselines on three large-scale user-item recommendation datasets with interactions under a streaming setting. The results demonstrate the superior performance of LCE, showing that it achieves nearly skyline performance with significantly fewer parameters than alternative graph-based models.