 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGIR 2021 E-Commerce Workshop Data Challenge
Apr 27, 2021

The 2021 SIGIR workshop on eCommerce is hosting the Coveo Data Challenge for "In-session prediction for purchase intent and recommendations". The challenge addresses the growing need for reliable predictions within the boundaries of a shopping session, as customer intentions can be different depending on the occasion. The need for efficient procedures for personalization is even clearer if we consider the e-commerce landscape more broadly: outside of giant digital retailers, the constraints of the problem are stricter, due to smaller user bases and the realization that most users are not frequently returning customers. We release a new session-based dataset including more than 30M fine-grained browsing events (product detail, add, purchase), enriched by linguistic behavior (queries made by shoppers, with items clicked and items not clicked after the query) and catalog meta-data (images, text, pricing information). On this dataset, we ask participants to showcase innovative solutions for two open problems: a recommendation task (where a model is shown some events at the start of a session, and it is asked to predict future product interactions); an intent prediction task, where a model is shown a session containing an add-to-cart event, and it is asked to predict whether the item will be bought before the end of the session.
Efficient Learning of Ensembles with QuadBoost
Nov 20, 2015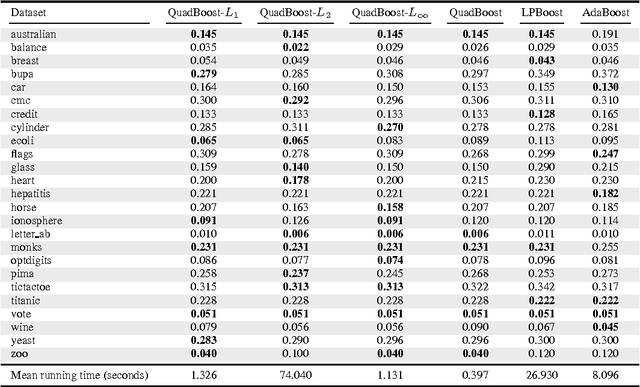
We first present a general risk bound for ensembles that depends on the Lp norm of the weighted combination of voters which can be selected from a continuous set. We then propose a boosting method, called QuadBoost, which is strongly supported by the general risk bound and has very simple rules for assigning the voters' weights. Moreover, QuadBoost exhibits a rate of decrease of its empirical error which is slightly faster than the one achieved by AdaBoost. The experimental results confirm the expectation of the theory that QuadBoost is a very efficient method for learning ensembles.
Risk Bounds for the Majority Vote: From a PAC-Bayesian Analysis to a Learning Algorithm
Jul 28, 2015
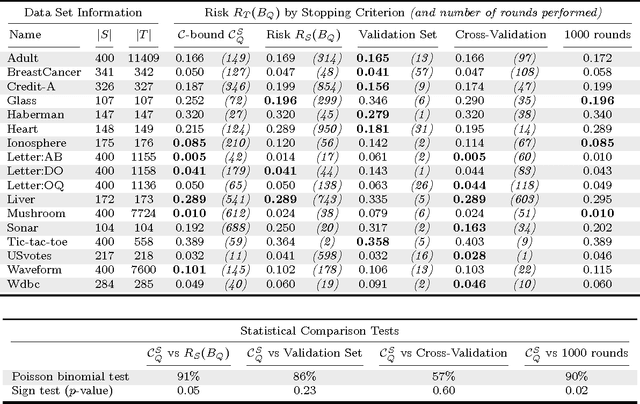


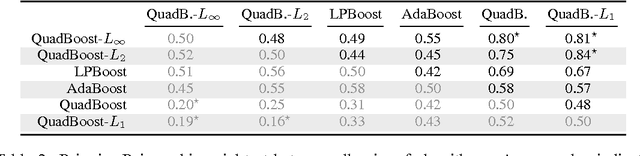
We propose an extensive analysis of the behavior of majority votes in binary classification. In particular, we introduce a risk bound for majority votes, called the C-bound, that takes into account the average quality of the voters and their average disagreement. We also propose an extensive PAC-Bayesian analysis that shows how the C-bound can be estimated from various observations contained in the training data. The analysis intends to be self-contained and can be used as introductory material to PAC-Bayesian statistical learning theory. It starts from a general PAC-Bayesian perspective and ends with uncommon PAC-Bayesian bounds. Some of these bounds contain no Kullback-Leibler divergence and others allow kernel functions to be used as voters (via the sample compression setting). Finally, out of the analysis, we propose the MinCq learning algorithm that basically minimizes the C-bound. MinCq reduces to a simple quadratic program. Aside from being theoretically grounded, MinCq achieves state-of-the-art performance, as shown in our extensive empirical comparison with both AdaBoost and the Support Vector Machine.
* Published in JMLR http://jmlr.org/papers/v16/germain15a.html
On the Generalization of the C-Bound to Structured Output Ensemble Methods
Jun 15, 2015
This paper generalizes an important result from the PAC-Bayesian literature for binary classification to the case of ensemble methods for structured outputs. We prove a generic version of the \Cbound, an upper bound over the risk of models expressed as a weighted majority vote that is based on the first and second statistical moments of the vote's margin. This bound may advantageously $(i)$ be applied on more complex outputs such as multiclass labels and multilabel, and $(ii)$ allow to consider margin relaxations. These results open the way to develop new ensemble methods for structured output prediction with PAC-Bayesian guarantees.
On Generalizing the C-Bound to the Multiclass and Multi-label Settings
Jan 13, 2015
The C-bound, introduced in Lacasse et al., gives a tight upper bound on the risk of a binary majority vote classifier. In this work, we present a first step towards extending this work to more complex outputs, by providing generalizations of the C-bound to the multiclass and multi-label settings.