 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Contextualized Topic Models with Zero-shot Learning
Paper and Code
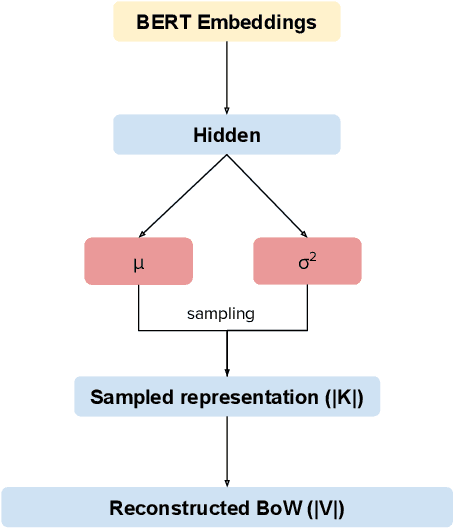
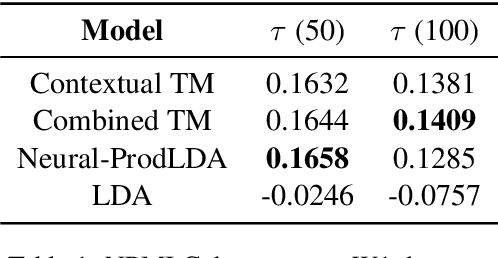
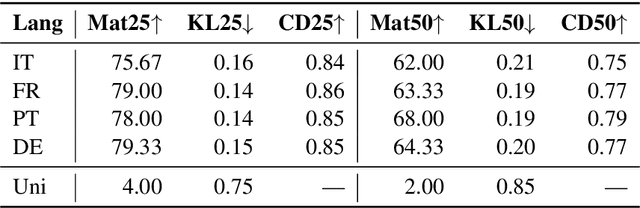
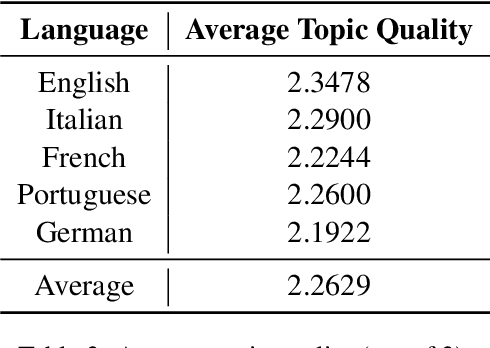
Many data sets in a domain (reviews, forums, news, etc.) exist in parallel languages. They all cover the same content, but the linguistic differences make it impossible to use traditional, bag-of-word-based topic models. Models have to be either single-language or suffer from a huge, but extremely sparse vocabulary. Both issues can be addressed by transfer learning. In this paper, we introduce a zero-shot cross-lingual topic model, i.e., our model learns topics on one language (here, English), and predicts them for documents in other languages. By using the text of the same document in different languages, we can evaluate the quality of the predictions. Our results show that topics are coherent and stable across languages, which suggests exciting future research directions.