 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalous Sound Detection as a Simple Binary Classification Problem with Careful Selection of Proxy Outlier Examples
Nov 05, 2020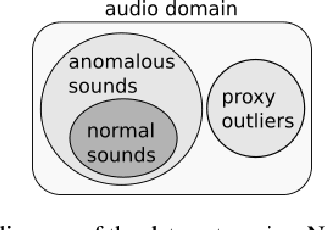
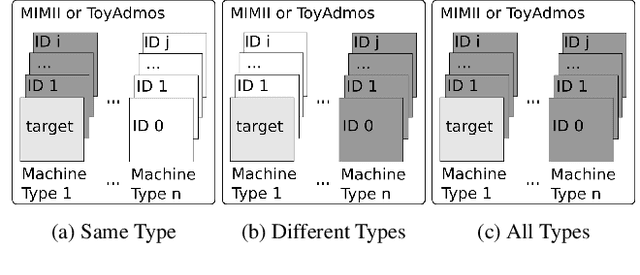
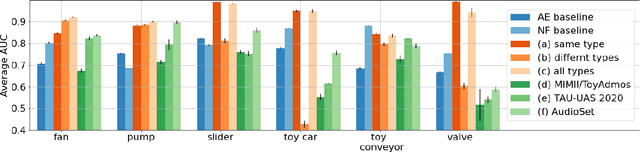
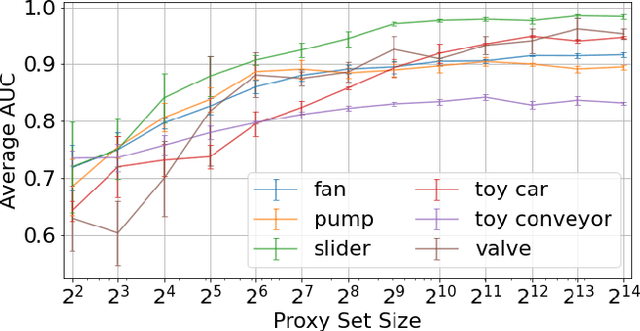
Unsupervised anomalous sound detection is concerned with identifying sounds that deviate from what is defined as 'normal', without explicitly specifying the types of anomalies. A significant obstacle is the diversity and rareness of outliers, which typically prevent us from collecting a representative set of anomalous sounds. As a consequence, most anomaly detection methods use unsupervised rather than supervised machine learning methods. Nevertheless, we will show that anomalous sound detection can be effectively framed as a supervised classification problem if the set of anomalous samples is carefully substituted with what we call proxy outliers. Candidates for proxy outliers are available in abundance as they potentially include all recordings that are neither normal nor abnormal sounds. We experiment with the machine condition monitoring data set of the 2020's DCASE Challenge and find proxy outliers with matching recording conditions and high similarity to the target sounds particularly informative. If no data with similar sounds and matching recording conditions is available, data sets with a larger diversity in these two dimensions are preferable. Our models based on supervised training with proxy outliers achieved rank three in Task 2 of the DCASE2020 Challenge.
audioLIME: Listenable Explanations Using Source Separation
Sep 07, 2020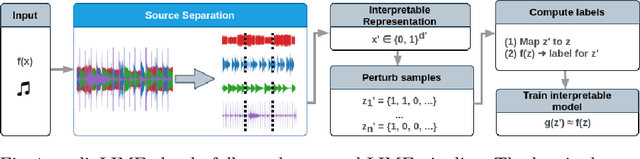
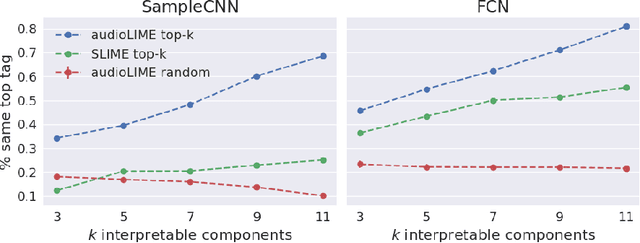
Deep neural networks (DNNs) are successfully applied in a wide variety of music information retrieval (MIR) tasks but their predictions are usually not interpretable. We propose audioLIME, a method based on Local Interpretable Model-agnostic Explanations (LIME) extended by a musical definition of locality. The perturbations used in LIME are created by switching on/off components extracted by source separation which makes our explanations listenable. We validate audioLIME on two different music tagging systems and show that it produces sensible explanations in situations where a competing method cannot.
Towards Musically Meaningful Explanations Using Source Separation
Sep 04, 2020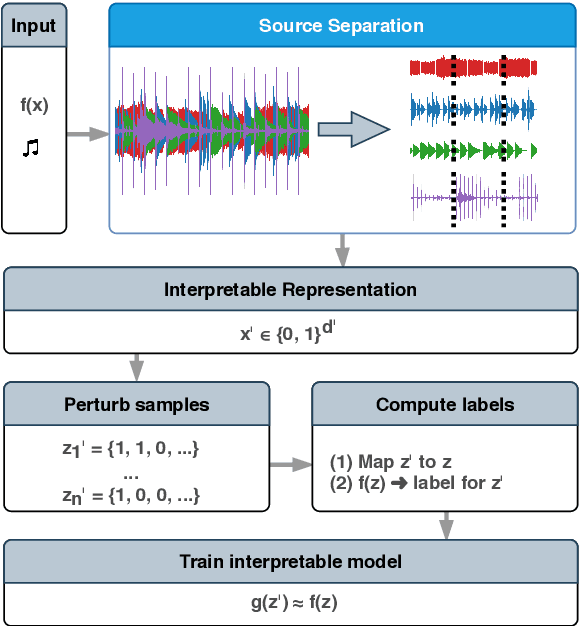

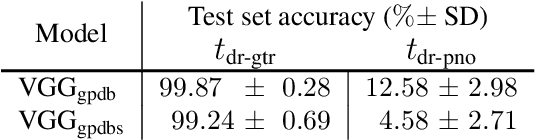
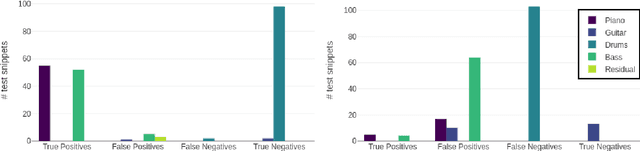
Deep neural networks (DNNs) are successfully applied in a wide variety of music information retrieval (MIR) tasks. Such models are usually considered "black boxes", meaning that their predictions are not interpretable. Prior work on explainable models in MIR has generally used image processing tools to produce explanations for DNN predictions, but these are not necessarily musically meaningful, or can be listened to (which, arguably, is important in music). We propose audioLIME, a method based on Local Interpretable Model-agnostic Explanation (LIME), extended by a musical definition of locality. LIME learns locally linear models on perturbations of an example that we want to explain. Instead of extracting components of the spectrogram using image segmentation as part of the LIME pipeline, we propose using source separation. The perturbations are created by switching on/off sources which makes our explanations listenable. We first validate audioLIME on a classifier that was deliberately trained to confuse the true target with a spurious signal, and show that this can easily be detected using our method. We then show that it passes a sanity check that many available explanation methods fail. Finally, we demonstrate the general applicability of our (model-agnostic) method on a third-party music tagger.
Receptive-Field Regularized CNNs for Music Classification and Tagging
Jul 27, 2020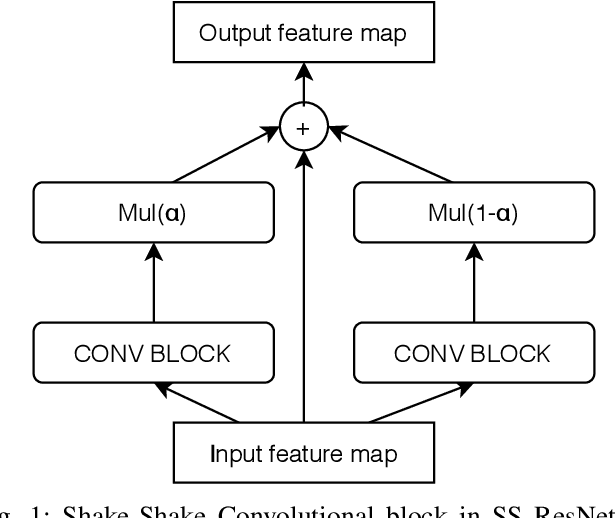
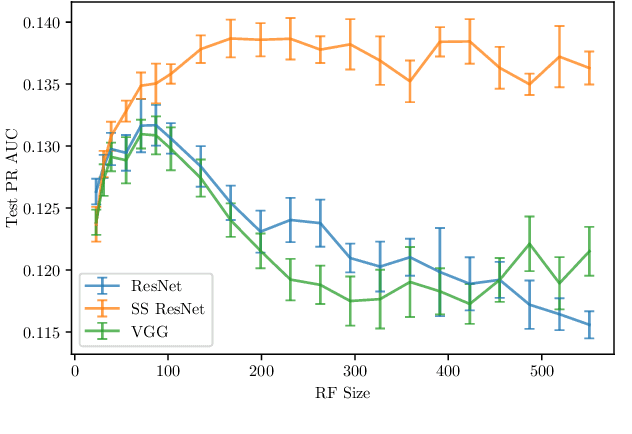
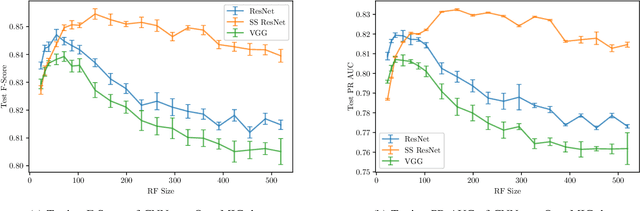
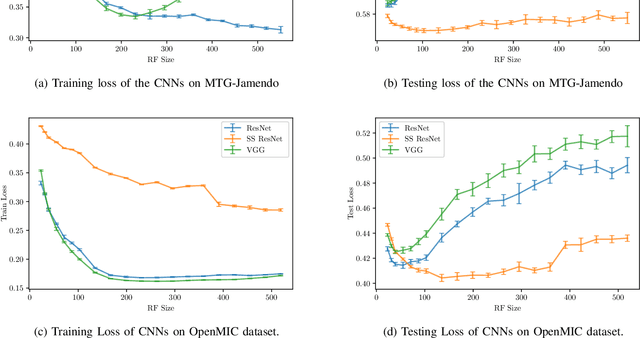
Convolutional Neural Networks (CNNs) have been successfully used in various Music Information Retrieval (MIR) tasks, both as end-to-end models and as feature extractors for more complex systems. However, the MIR field is still dominated by the classical VGG-based CNN architecture variants, often in combination with more complex modules such as attention, and/or techniques such as pre-training on large datasets. Deeper models such as ResNet -- which surpassed VGG by a large margin in other domains -- are rarely used in MIR. One of the main reasons for this, as we will show, is the lack of generalization of deeper CNNs in the music domain. In this paper, we present a principled way to make deep architectures like ResNet competitive for music-related tasks, based on well-designed regularization strategies. In particular, we analyze the recently introduced Receptive-Field Regularization and Shake-Shake, and show that they significantly improve the generalization of deep CNNs on music-related tasks, and that the resulting deep CNNs can outperform current more complex models such as CNNs augmented with pre-training and attention. We demonstrate this on two different MIR tasks and two corresponding datasets, thus offering our deep regularized CNNs as a new baseline for these datasets, which can also be used as a feature-extracting module in future, more complex approaches.
On Data Augmentation and Adversarial Risk: An Empirical Analysis
Jul 06, 2020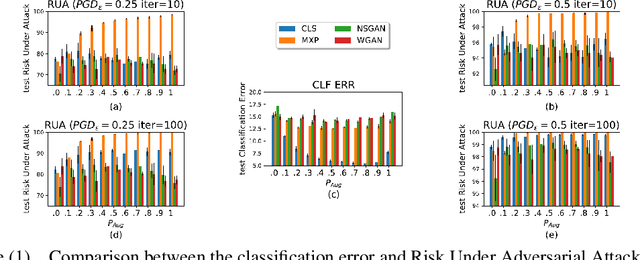
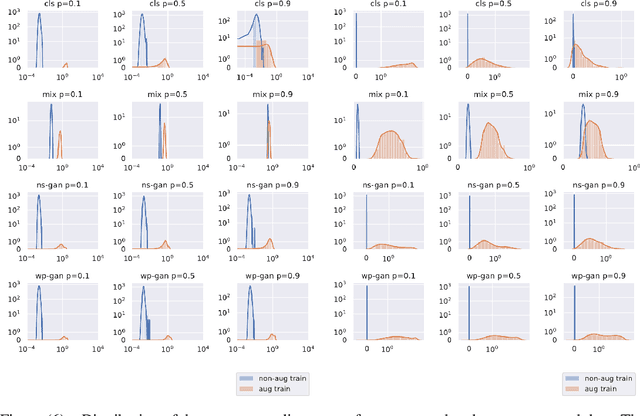
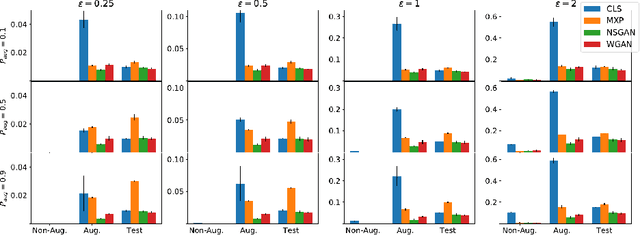
Data augmentation techniques have become standard practice in deep learning, as it has been shown to greatly improve the generalisation abilities of models. These techniques rely on different ideas such as invariance-preserving transformations (e.g, expert-defined augmentation), statistical heuristics (e.g, Mixup), and learning the data distribution (e.g, GANs). However, in the adversarial settings it remains unclear under what conditions such data augmentation methods reduce or even worsen the misclassification risk. In this paper, we therefore analyse the effect of different data augmentation techniques on the adversarial risk by three measures: (a) the well-known risk under adversarial attacks, (b) a new measure of prediction-change stress based on the Laplacian operator, and (c) the influence of training examples on prediction. The results of our empirical analysis disprove the hypothesis that an improvement in the classification performance induced by a data augmentation is always accompanied by an improvement in the risk under adversarial attack. Further, our results reveal that the augmented data has more influence than the non-augmented data, on the resulting models. Taken together, our results suggest that general-purpose data augmentations that do not take into the account the characteristics of the data and the task, must be applied with care.
Emotion and Theme Recognition in Music with Frequency-Aware RF-Regularized CNNs
Oct 28, 2019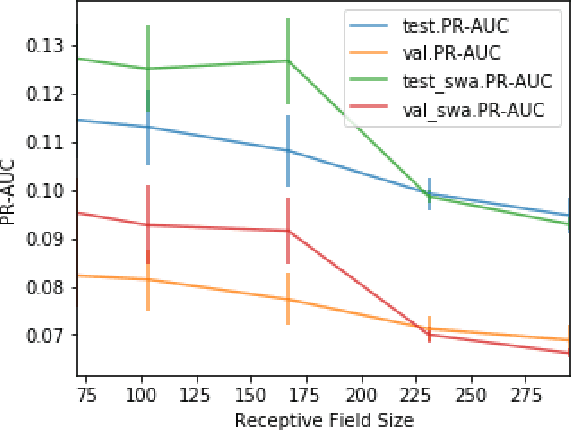
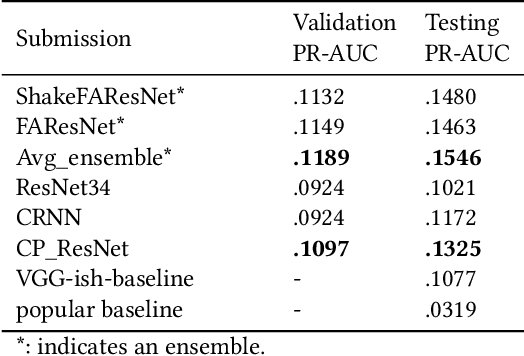
We present CP-JKU submission to MediaEval 2019; a Receptive Field-(RF)-regularized and Frequency-Aware CNN approach for tagging music with emotion/mood labels. We perform an investigation regarding the impact of the RF of the CNNs on their performance on this dataset. We observe that ResNets with smaller receptive fields -- originally adapted for acoustic scene classification -- also perform well in the emotion tagging task. We improve the performance of such architectures using techniques such as Frequency Awareness and Shake-Shake regularization, which were used in previous work on general acoustic recognition tasks.
Towards Explainable Music Emotion Recognition: The Route via Mid-level Features
Jul 08, 2019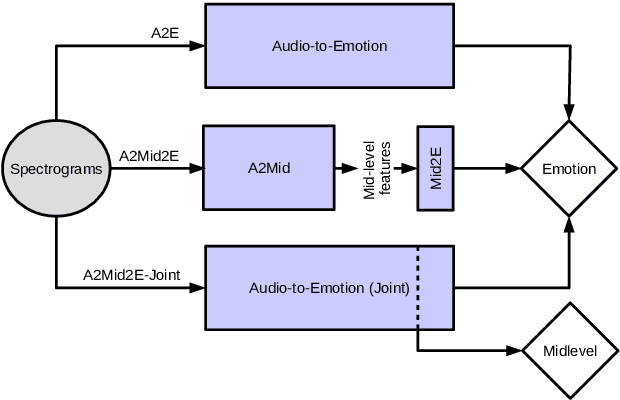

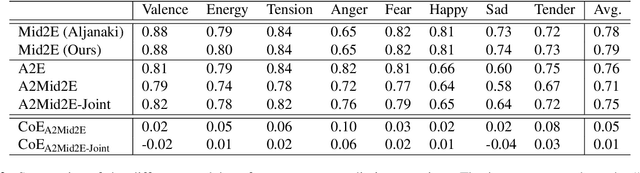
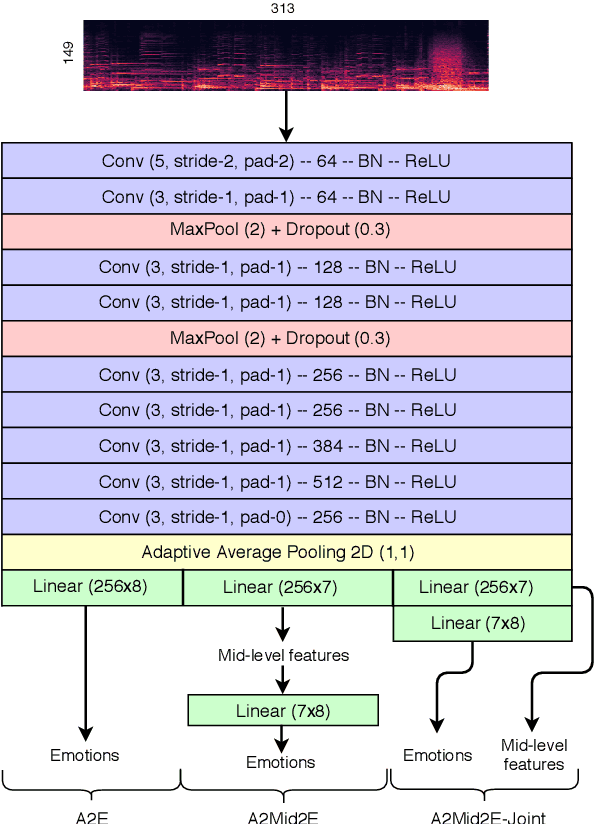
Emotional aspects play an important part in our interaction with music. However, modelling these aspects in MIR systems have been notoriously challenging since emotion is an inherently abstract and subjective experience, thus making it difficult to quantify or predict in the first place, and to make sense of the predictions in the next. In an attempt to create a model that can give a musically meaningful and intuitive explanation for its predictions, we propose a VGG-style deep neural network that learns to predict emotional characteristics of a musical piece together with (and based on) human-interpretable, mid-level perceptual features. We compare this to predicting emotion directly with an identical network that does not take into account the mid-level features and observe that the loss in predictive performance of going through the mid-level features is surprisingly low, on average. The design of our network allows us to visualize the effects of perceptual features on individual emotion predictions, and we argue that the small loss in performance in going through the mid-level features is justified by the gain in explainability of the predictions.
Two-level Explanations in Music Emotion Recognition
May 28, 2019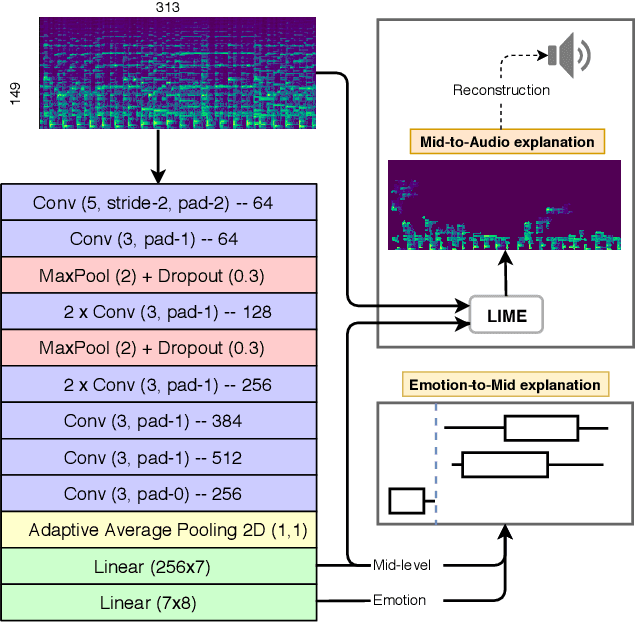
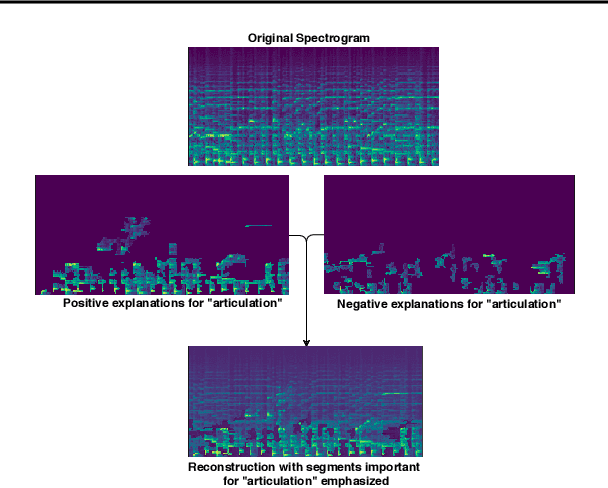
Current ML models for music emotion recognition, while generally working quite well, do not give meaningful or intuitive explanations for their predictions. In this work, we propose a 2-step procedure to arrive at spectrogram-level explanations that connect certain aspects of the audio to interpretable mid-level perceptual features, and these to the actual emotion prediction. That makes it possible to focus on specific musical reasons for a prediction (in terms of perceptual features), and to trace these back to patterns in the audio that can be interpreted visually and acoustically.
An Evolutionary Stochastic-Local-Search Framework for One-Dimensional Cutting-Stock Problems
Jul 27, 2017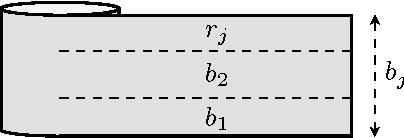

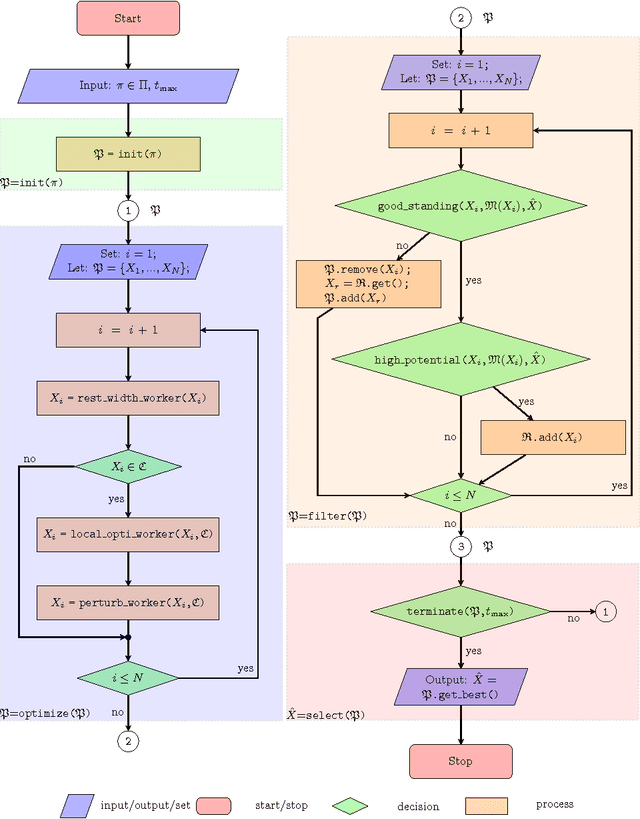

We introduce an evolutionary stochastic-local-search (SLS) algorithm for addressing a generalized version of the so-called 1/V/D/R cutting-stock problem. Cutting-stock problems are encountered often in industrial environments and the ability to address them efficiently usually results in large economic benefits. Traditionally linear-programming-based techniques have been utilized to address such problems, however their flexibility might be limited when nonlinear constraints and objective functions are introduced. To this end, this paper proposes an evolutionary SLS algorithm for addressing one-dimensional cutting-stock problems. The contribution lies in the introduction of a flexible structural framework of the optimization that may accommodate a large family of diversification strategies including a novel parallel pattern appropriate for SLS algorithms (not necessarily restricted to cutting-stock problems). We finally demonstrate through experiments in a real-world manufacturing problem the benefit in cost reduction of the considered diversification strategies.