Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-level Explanations in Music Emotion Recognition
Paper and Code
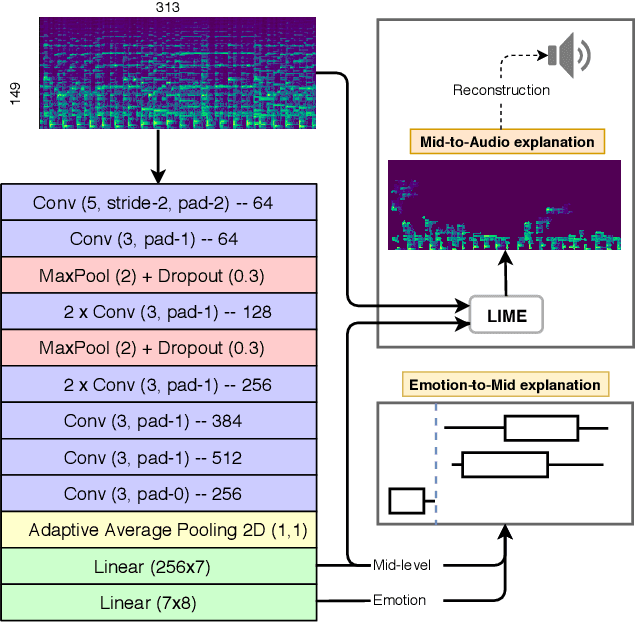
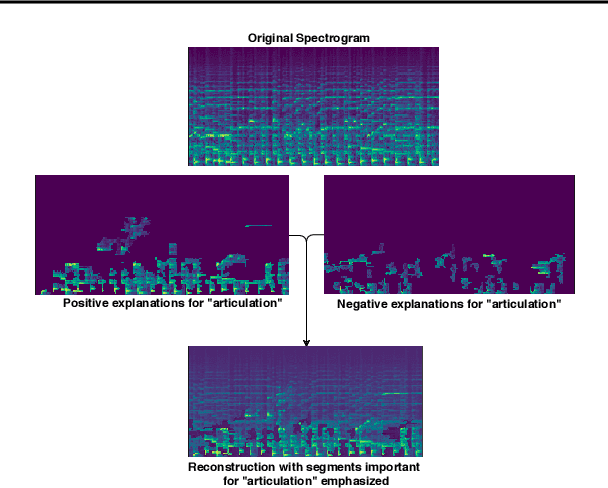
Current ML models for music emotion recognition, while generally working quite well, do not give meaningful or intuitive explanations for their predictions. In this work, we propose a 2-step procedure to arrive at spectrogram-level explanations that connect certain aspects of the audio to interpretable mid-level perceptual features, and these to the actual emotion prediction. That makes it possible to focus on specific musical reasons for a prediction (in terms of perceptual features), and to trace these back to patterns in the audio that can be interpreted visually and acoustically.
* ML4MD Workshop of the 36th International Conference on Machine
Learning
View paper on