 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Domain Gap in Biomedical Imaging by In-Context Control Samples
Apr 22, 2026The central problem in biomedical imaging are batch effects: systematic technical variations unrelated to the biological signal of interest. These batch effects critically undermine experimental reproducibility and are the primary cause of failure of deep learning systems on new experimental batches, preventing their practical use in the real world. Despite years of research, no method has succeeded in closing this performance gap for deep learning models. We propose Control-Stabilized Adaptive Risk Minimization via Batch Normalization (CS-ARM-BN), a meta-learning adaptation method that exploits negative control samples. Such unperturbed reference images are present in every experimental batch by design and serve as stable context for adaptation. We validate our novel method on Mechanism-of-Action (MoA) classification, a crucial task for drug discovery, on the large-scale JUMP-CP dataset. The accuracy of standard ResNets drops from 0.939 $\pm$ 0.005, on the training domain, to 0.862 $\pm$ 0.060 on data from new experimental batches. Foundation models, even after Typical Variation Normalization, fail to close this gap. We are the first to show that meta-learning approaches close the domain gap by achieving 0.935 $\pm$ 0.018. If the new experimental batches exhibit strong domain shifts, such as being generated in a different lab, meta-learning approaches can be stabilized with control samples, which are always available in biomedical experiments. Our work shows that batch effects in bioimaging data can be effectively neutralized through principled in-context adaptation, which also makes them practically usable and efficient.
Stabilizing Test-Time Adaptation of High-Dimensional Simulation Surrogates via D-Optimal Statistics
Feb 17, 2026Machine learning surrogates are increasingly used in engineering to accelerate costly simulations, yet distribution shifts between training and deployment often cause severe performance degradation (e.g., unseen geometries or configurations). Test-Time Adaptation (TTA) can mitigate such shifts, but existing methods are largely developed for lower-dimensional classification with structured outputs and visually aligned input-output relationships, making them unstable for the high-dimensional, unstructured and regression problems common in simulation. We address this challenge by proposing a TTA framework based on storing maximally informative (D-optimal) statistics, which jointly enables stable adaptation and principled parameter selection at test time. When applied to pretrained simulation surrogates, our method yields up to 7% out-of-distribution improvements at negligible computational cost. To the best of our knowledge, this is the first systematic demonstration of effective TTA for high-dimensional simulation regression and generative design optimization, validated on the SIMSHIFT and EngiBench benchmarks.
The Offline-Frontier Shift: Diagnosing Distributional Limits in Generative Multi-Objective Optimization
Feb 11, 2026Offline multi-objective optimization (MOO) aims to recover Pareto-optimal designs given a finite, static dataset. Recent generative approaches, including diffusion models, show strong performance under hypervolume, yet their behavior under other established MOO metrics is less understood. We show that generative methods systematically underperform evolutionary alternatives with respect to other metrics, such as generational distance. We relate this failure mode to the offline-frontier shift, i.e., the displacement of the offline dataset from the Pareto front, which acts as a fundamental limitation in offline MOO. We argue that overcoming this limitation requires out-of-distribution sampling in objective space (via an integral probability metric) and empirically observe that generative methods remain conservatively close to the offline objective distribution. Our results position offline MOO as a distribution-shift--limited problem and provide a diagnostic lens for understanding when and why generative optimization methods fail.
AP-OOD: Attention Pooling for Out-of-Distribution Detection
Feb 05, 2026Out-of-distribution (OOD) detection, which maps high-dimensional data into a scalar OOD score, is critical for the reliable deployment of machine learning models. A key challenge in recent research is how to effectively leverage and aggregate token embeddings from language models to obtain the OOD score. In this work, we propose AP-OOD, a novel OOD detection method for natural language that goes beyond simple average-based aggregation by exploiting token-level information. AP-OOD is a semi-supervised approach that flexibly interpolates between unsupervised and supervised settings, enabling the use of limited auxiliary outlier data. Empirically, AP-OOD sets a new state of the art in OOD detection for text: in the unsupervised setting, it reduces the FPR95 (false positive rate at 95% true positives) from 27.84% to 4.67% on XSUM summarization, and from 77.08% to 70.37% on WMT15 En-Fr translation.
SIMSHIFT: A Benchmark for Adapting Neural Surrogates to Distribution Shifts
Jun 13, 2025Neural surrogates for Partial Differential Equations (PDEs) often suffer significant performance degradation when evaluated on unseen problem configurations, such as novel material types or structural dimensions. Meanwhile, Domain Adaptation (DA) techniques have been widely used in vision and language processing to generalize from limited information about unseen configurations. In this work, we address this gap through two focused contributions. First, we introduce SIMSHIFT, a novel benchmark dataset and evaluation suite composed of four industrial simulation tasks: hot rolling, sheet metal forming, electric motor design and heatsink design. Second, we extend established domain adaptation methods to state of the art neural surrogates and systematically evaluate them. These approaches use parametric descriptions and ground truth simulations from multiple source configurations, together with only parametric descriptions from target configurations. The goal is to accurately predict target simulations without access to ground truth simulation data. Extensive experiments on SIMSHIFT highlight the challenges of out of distribution neural surrogate modeling, demonstrate the potential of DA in simulation, and reveal open problems in achieving robust neural surrogates under distribution shifts in industrially relevant scenarios. Our codebase is available at https://github.com/psetinek/simshift
Binary Losses for Density Ratio Estimation
Jul 01, 2024Estimating the ratio of two probability densities from finitely many observations of the densities, is a central problem in machine learning and statistics. A large class of methods constructs estimators from binary classifiers which distinguish observations from the two densities. However, the error of these constructions depends on the choice of the binary loss function, raising the question of which loss function to choose based on desired error properties. In this work, we start from prescribed error measures in a class of Bregman divergences and characterize all loss functions that lead to density ratio estimators with a small error. Our characterization provides a simple recipe for constructing loss functions with certain properties, such as loss functions that prioritize an accurate estimation of large values. This contrasts with classical loss functions, such as the logistic loss or boosting loss, which prioritize accurate estimation of small values. We provide numerical illustrations with kernel methods and test their performance in applications of parameter selection for deep domain adaptation.
Overcoming Saturation in Density Ratio Estimation by Iterated Regularization
Feb 21, 2024



Estimating the ratio of two probability densities from finitely many samples, is a central task in machine learning and statistics. In this work, we show that a large class of kernel methods for density ratio estimation suffers from error saturation, which prevents algorithms from achieving fast error convergence rates on highly regular learning problems. To resolve saturation, we introduce iterated regularization in density ratio estimation to achieve fast error rates. Our methods outperform its non-iteratively regularized versions on benchmarks for density ratio estimation as well as on large-scale evaluations for importance-weighted ensembling of deep unsupervised domain adaptation models.
SymbolicAI: A framework for logic-based approaches combining generative models and solvers
Feb 05, 2024We introduce SymbolicAI, a versatile and modular framework employing a logic-based approach to concept learning and flow management in generative processes. SymbolicAI enables the seamless integration of generative models with a diverse range of solvers by treating large language models (LLMs) as semantic parsers that execute tasks based on both natural and formal language instructions, thus bridging the gap between symbolic reasoning and generative AI. We leverage probabilistic programming principles to tackle complex tasks, and utilize differentiable and classical programming paradigms with their respective strengths. The framework introduces a set of polymorphic, compositional, and self-referential operations for data stream manipulation, aligning LLM outputs with user objectives. As a result, we can transition between the capabilities of various foundation models endowed with zero- and few-shot learning capabilities and specialized, fine-tuned models or solvers proficient in addressing specific problems. In turn, the framework facilitates the creation and evaluation of explainable computational graphs. We conclude by introducing a quality measure and its empirical score for evaluating these computational graphs, and propose a benchmark that compares various state-of-the-art LLMs across a set of complex workflows. We refer to the empirical score as the "Vector Embedding for Relational Trajectory Evaluation through Cross-similarity", or VERTEX score for short. The framework codebase and benchmark are linked below.
On regularized Radon-Nikodym differentiation
Aug 15, 2023


We discuss the problem of estimating Radon-Nikodym derivatives. This problem appears in various applications, such as covariate shift adaptation, likelihood-ratio testing, mutual information estimation, and conditional probability estimation. To address the above problem, we employ the general regularization scheme in reproducing kernel Hilbert spaces. The convergence rate of the corresponding regularized algorithm is established by taking into account both the smoothness of the derivative and the capacity of the space in which it is estimated. This is done in terms of general source conditions and the regularized Christoffel functions. We also find that the reconstruction of Radon-Nikodym derivatives at any particular point can be done with high order of accuracy. Our theoretical results are illustrated by numerical simulations.
Adaptive learning of density ratios in RKHS
Jul 30, 2023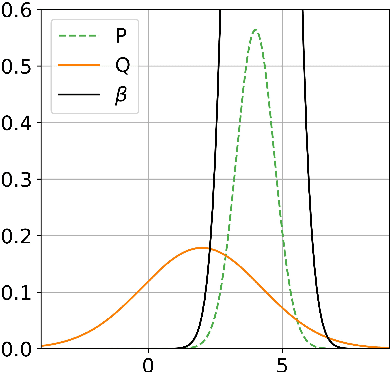
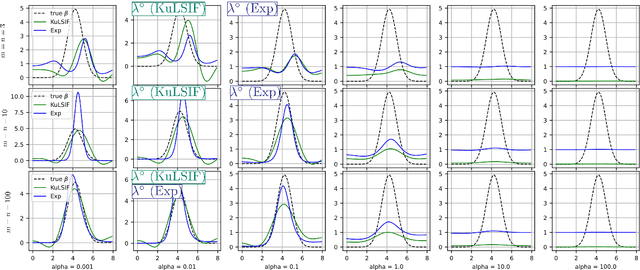
Estimating the ratio of two probability densities from finitely many observations of the densities is a central problem in machine learning and statistics with applications in two-sample testing, divergence estimation, generative modeling, covariate shift adaptation, conditional density estimation, and novelty detection. In this work, we analyze a large class of density ratio estimation methods that minimize a regularized Bregman divergence between the true density ratio and a model in a reproducing kernel Hilbert space (RKHS). We derive new finite-sample error bounds, and we propose a Lepskii type parameter choice principle that minimizes the bounds without knowledge of the regularity of the density ratio. In the special case of quadratic loss, our method adaptively achieves a minimax optimal error rate. A numerical illustration is provided.