 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning by Dimensionality Reduction in Gradient Space
Jun 07, 2022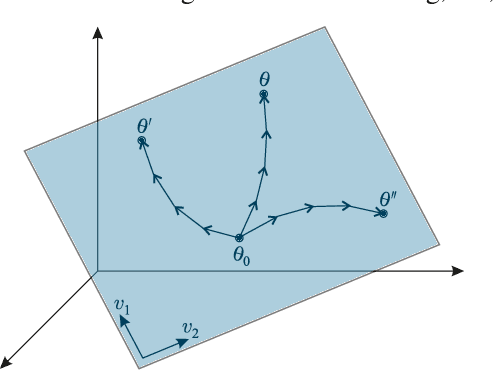
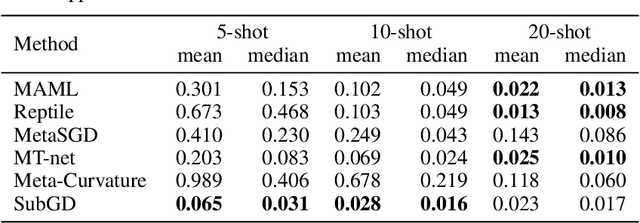
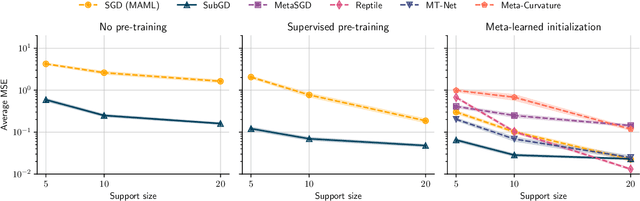
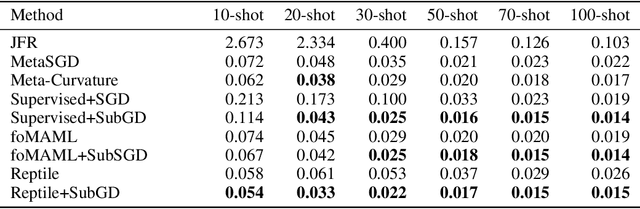
We introduce SubGD, a novel few-shot learning method which is based on the recent finding that stochastic gradient descent updates tend to live in a low-dimensional parameter subspace. In experimental and theoretical analyses, we show that models confined to a suitable predefined subspace generalize well for few-shot learning. A suitable subspace fulfills three criteria across the given tasks: it (a) allows to reduce the training error by gradient flow, (b) leads to models that generalize well, and (c) can be identified by stochastic gradient descent. SubGD identifies these subspaces from an eigendecomposition of the auto-correlation matrix of update directions across different tasks. Demonstrably, we can identify low-dimensional suitable subspaces for few-shot learning of dynamical systems, which have varying properties described by one or few parameters of the analytical system description. Such systems are ubiquitous among real-world applications in science and engineering. We experimentally corroborate the advantages of SubGD on three distinct dynamical systems problem settings, significantly outperforming popular few-shot learning methods both in terms of sample efficiency and performance.
READ-BAD: A New Dataset and Evaluation Scheme for Baseline Detection in Archival Documents
Dec 11, 2017


Text line detection is crucial for any application associated with Automatic Text Recognition or Keyword Spotting. Modern algorithms perform good on well-established datasets since they either comprise clean data or simple/homogeneous page layouts. We have collected and annotated 2036 archival document images from different locations and time periods. The dataset contains varying page layouts and degradations that challenge text line segmentation methods. Well established text line segmentation evaluation schemes such as the Detection Rate or Recognition Accuracy demand for binarized data that is annotated on a pixel level. Producing ground truth by these means is laborious and not needed to determine a method's quality. In this paper we propose a new evaluation scheme that is based on baselines. The proposed scheme has no need for binarization and it can handle skewed as well as rotated text lines. The ICDAR 2017 Competition on Baseline Detection and the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts used this evaluation scheme. Finally, we present results achieved by a recently published text line detection algorithm.
Unsupervised Feature Learning for Writer Identification and Writer Retrieval
Aug 18, 2017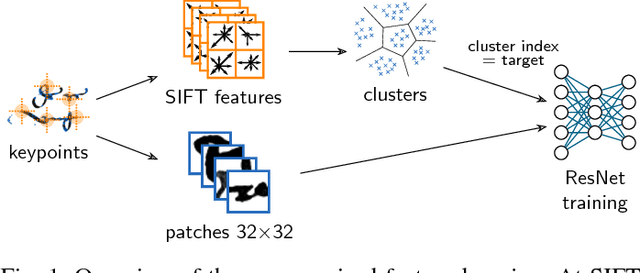

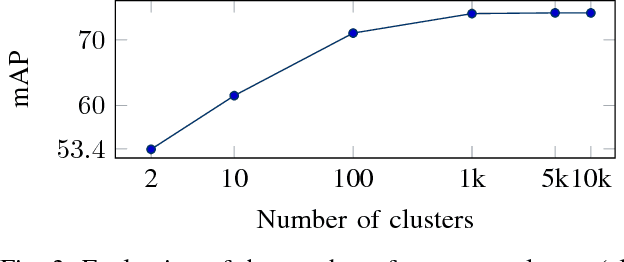

Deep Convolutional Neural Networks (CNN) have shown great success in supervised classification tasks such as character classification or dating. Deep learning methods typically need a lot of annotated training data, which is not available in many scenarios. In these cases, traditional methods are often better than or equivalent to deep learning methods. In this paper, we propose a simple, yet effective, way to learn CNN activation features in an unsupervised manner. Therefore, we train a deep residual network using surrogate classes. The surrogate classes are created by clustering the training dataset, where each cluster index represents one surrogate class. The activations from the penultimate CNN layer serve as features for subsequent classification tasks. We evaluate the feature representations on two publicly available datasets. The focus lies on the ICDAR17 competition dataset on historical document writer identification (Historical-WI). We show that the activation features trained without supervision are superior to descriptors of state-of-the-art writer identification methods. Additionally, we achieve comparable results in the case of handwriting classification using the ICFHR16 competition dataset on historical Latin script types (CLaMM16).