 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Influence of Text Quantity on Writer Retrieval
Jun 09, 2025This paper investigates the task of writer retrieval, which identifies documents authored by the same individual within a dataset based on handwriting similarities. While existing datasets and methodologies primarily focus on page level retrieval, we explore the impact of text quantity on writer retrieval performance by evaluating line- and word level retrieval. We examine three state-of-the-art writer retrieval systems, including both handcrafted and deep learning-based approaches, and analyze their performance using varying amounts of text. Our experiments on the CVL and IAM dataset demonstrate that while performance decreases by 20-30% when only one line of text is used as query and gallery, retrieval accuracy remains above 90% of full-page performance when at least four lines are included. We further show that text-dependent retrieval can maintain strong performance in low-text scenarios. Our findings also highlight the limitations of handcrafted features in low-text scenarios, with deep learning-based methods like NetVLAD outperforming traditional VLAD encoding.
SAGHOG: Self-Supervised Autoencoder for Generating HOG Features for Writer Retrieval
Apr 26, 2024This paper introduces SAGHOG, a self-supervised pretraining strategy for writer retrieval using HOG features of the binarized input image. Our preprocessing involves the application of the Segment Anything technique to extract handwriting from various datasets, ending up with about 24k documents, followed by training a vision transformer on reconstructing masked patches of the handwriting. SAGHOG is then finetuned by appending NetRVLAD as an encoding layer to the pretrained encoder. Evaluation of our approach on three historical datasets, Historical-WI, HisFrag20, and GRK-Papyri, demonstrates the effectiveness of SAGHOG for writer retrieval. Additionally, we provide ablation studies on our architecture and evaluate un- and supervised finetuning. Notably, on HisFrag20, SAGHOG outperforms related work with a mAP of 57.2 % - a margin of 11.6 % to the current state of the art, showcasing its robustness on challenging data, and is competitive on even small datasets, e.g. GRK-Papyri, where we achieve a Top-1 accuracy of 58.0%.
Unsupervised Writer Retrieval using NetRVLAD and Graph Similarity Reranking
May 09, 2023This paper presents an unsupervised approach for writer retrieval based on clustering SIFT descriptors detected at keypoint locations resulting in pseudo-cluster labels. With those cluster labels, a residual network followed by our proposed NetRVLAD, an encoding layer with reduced complexity compared to NetVLAD, is trained on 32x32 patches at keypoint locations. Additionally, we suggest a graph-based reranking algorithm called SGR to exploit similarities of the page embeddings to boost the retrieval performance. Our approach is evaluated on two historical datasets (Historical-WI and HisIR19). We include an evaluation of different backbones and NetRVLAD. It competes with related work on historical datasets without using explicit encodings. We set a new State-of-the-art on both datasets by applying our reranking scheme and show that our approach achieves comparable performance on a modern dataset as well.
Comparing Machine Learning Approaches for Table Recognition in Historical Register Books
Jun 14, 2019

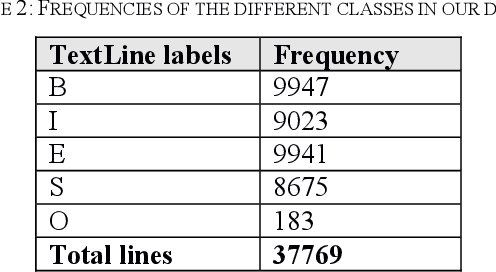
We present in this paper experiments on Table Recognition in hand-written registry books. We first explain how the problem of row and column detection is modeled, and then compare two Machine Learning approaches (Conditional Random Field and Graph Convolutional Network) for detecting these table elements. Evaluation was conducted on death records provided by the Archive of the Diocese of Passau. Both methods show similar results, a 89 F1 score, a quality which allows for Information Extraction. Software and dataset are open source/data.
READ-BAD: A New Dataset and Evaluation Scheme for Baseline Detection in Archival Documents
Dec 11, 2017

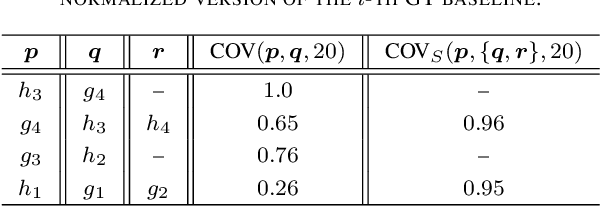

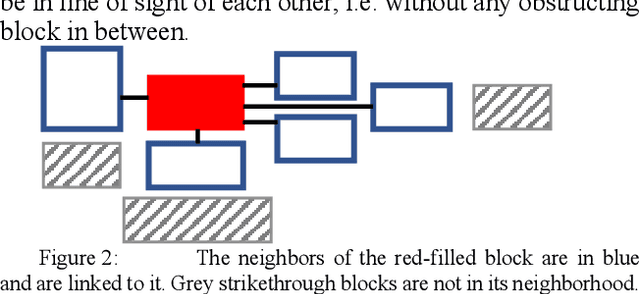
Text line detection is crucial for any application associated with Automatic Text Recognition or Keyword Spotting. Modern algorithms perform good on well-established datasets since they either comprise clean data or simple/homogeneous page layouts. We have collected and annotated 2036 archival document images from different locations and time periods. The dataset contains varying page layouts and degradations that challenge text line segmentation methods. Well established text line segmentation evaluation schemes such as the Detection Rate or Recognition Accuracy demand for binarized data that is annotated on a pixel level. Producing ground truth by these means is laborious and not needed to determine a method's quality. In this paper we propose a new evaluation scheme that is based on baselines. The proposed scheme has no need for binarization and it can handle skewed as well as rotated text lines. The ICDAR 2017 Competition on Baseline Detection and the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts used this evaluation scheme. Finally, we present results achieved by a recently published text line detection algorithm.