 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Connectivity-Aware Text Line Segmentation in Historical Documents
Aug 26, 2025A foundational task for the digital analysis of documents is text line segmentation. However, automating this process with deep learning models is challenging because it requires large, annotated datasets that are often unavailable for historical documents. Additionally, the annotation process is a labor- and cost-intensive task that requires expert knowledge, which makes few-shot learning a promising direction for reducing data requirements. In this work, we demonstrate that small and simple architectures, coupled with a topology-aware loss function, are more accurate and data-efficient than more complex alternatives. We pair a lightweight UNet++ with a connectivity-aware loss, initially developed for neuron morphology, which explicitly penalizes structural errors like line fragmentation and unintended line merges. To increase our limited data, we train on small patches extracted from a mere three annotated pages per manuscript. Our methodology significantly improves upon the current state-of-the-art on the U-DIADS-TL dataset, with a 200% increase in Recognition Accuracy and a 75% increase in Line Intersection over Union. Our method also achieves an F-Measure score on par with or even exceeding that of the competition winner of the DIVA-HisDB baseline detection task, all while requiring only three annotated pages, exemplifying the efficacy of our approach. Our implementation is publicly available at: https://github.com/RafaelSterzinger/acpr_few_shot_hist.
Towards the Influence of Text Quantity on Writer Retrieval
Jun 09, 2025This paper investigates the task of writer retrieval, which identifies documents authored by the same individual within a dataset based on handwriting similarities. While existing datasets and methodologies primarily focus on page level retrieval, we explore the impact of text quantity on writer retrieval performance by evaluating line- and word level retrieval. We examine three state-of-the-art writer retrieval systems, including both handcrafted and deep learning-based approaches, and analyze their performance using varying amounts of text. Our experiments on the CVL and IAM dataset demonstrate that while performance decreases by 20-30% when only one line of text is used as query and gallery, retrieval accuracy remains above 90% of full-page performance when at least four lines are included. We further show that text-dependent retrieval can maintain strong performance in low-text scenarios. Our findings also highlight the limitations of handcrafted features in low-text scenarios, with deep learning-based methods like NetVLAD outperforming traditional VLAD encoding.
Fusing Forces: Deep-Human-Guided Refinement of Segmentation Masks
Aug 06, 2024Etruscan mirrors constitute a significant category in Etruscan art, characterized by elaborate figurative illustrations featured on their backside. A laborious and costly aspect of their analysis and documentation is the task of manually tracing these illustrations. In previous work, a methodology has been proposed to automate this process, involving photometric-stereo scanning in combination with deep neural networks. While achieving quantitative performance akin to an expert annotator, some results still lack qualitative precision and, thus, require annotators for inspection and potential correction, maintaining resource intensity. In response, we propose a deep neural network trained to interactively refine existing annotations based on human guidance. Our human-in-the-loop approach streamlines annotation, achieving equal quality with up to 75% less manual input required. Moreover, during the refinement process, the relative improvement of our methodology over pure manual labeling reaches peak values of up to 26%, attaining drastically better quality quicker. By being tailored to the complex task of segmenting intricate lines, specifically distinguishing it from previous methods, our approach offers drastic improvements in efficacy, transferable to a broad spectrum of applications beyond Etruscan mirrors.
KaiRacters: Character-level-based Writer Retrieval for Greek Papyri
Jul 10, 2024



This paper presents a character-based approach for enhancing writer retrieval performance in the context of Greek papyri. Our contribution lies in introducing character-level annotations for frequently used characters, in our case the trigram kai and four additional letters (epsilon, kappa, mu, omega), in Greek texts. We use a state-of-the-art writer retrieval approach based on NetVLAD and compare a character-level-based feature aggregation method against the current default baseline of using small patches located at SIFT keypoint locations for building the page descriptors. We demonstrate that by using only about 15 characters per page, we are able to boost the performance up to 4% mAP (a relative improvement of 11%) on the GRK-120 dataset. Additionally, our qualitative analysis offers insights into the similarity scores of SIFT patches and specific characters. We publish the dataset with character-level annotations, including a quality label and our binarized images for further research.
SAGHOG: Self-Supervised Autoencoder for Generating HOG Features for Writer Retrieval
Apr 26, 2024This paper introduces SAGHOG, a self-supervised pretraining strategy for writer retrieval using HOG features of the binarized input image. Our preprocessing involves the application of the Segment Anything technique to extract handwriting from various datasets, ending up with about 24k documents, followed by training a vision transformer on reconstructing masked patches of the handwriting. SAGHOG is then finetuned by appending NetRVLAD as an encoding layer to the pretrained encoder. Evaluation of our approach on three historical datasets, Historical-WI, HisFrag20, and GRK-Papyri, demonstrates the effectiveness of SAGHOG for writer retrieval. Additionally, we provide ablation studies on our architecture and evaluate un- and supervised finetuning. Notably, on HisFrag20, SAGHOG outperforms related work with a mAP of 57.2 % - a margin of 11.6 % to the current state of the art, showcasing its robustness on challenging data, and is competitive on even small datasets, e.g. GRK-Papyri, where we achieve a Top-1 accuracy of 58.0%.
Drawing the Line: Deep Segmentation for Extracting Art from Ancient Etruscan Mirrors
Apr 24, 2024Etruscan mirrors constitute a significant category within Etruscan art and, therefore, undergo systematic examinations to obtain insights into ancient times. A crucial aspect of their analysis involves the labor-intensive task of manually tracing engravings from the backside. Additionally, this task is inherently challenging due to the damage these mirrors have sustained, introducing subjectivity into the process. We address these challenges by automating the process through photometric-stereo scanning in conjunction with deep segmentation networks which, however, requires effective usage of the limited data at hand. We accomplish this by incorporating predictions on a per-patch level, and various data augmentations, as well as exploring self-supervised learning. Compared to our baseline, we improve predictive performance w.r.t. the pseudo-F-Measure by around 16%. When assessing performance on complete mirrors against a human baseline, our approach yields quantitative similar performance to a human annotator and significantly outperforms existing binarization methods. With our proposed methodology, we streamline the annotation process, enhance its objectivity, and reduce overall workload, offering a valuable contribution to the examination of these historical artifacts and other non-traditional documents.
Enhancing Historical Image Retrieval with Compositional Cues
Mar 21, 2024

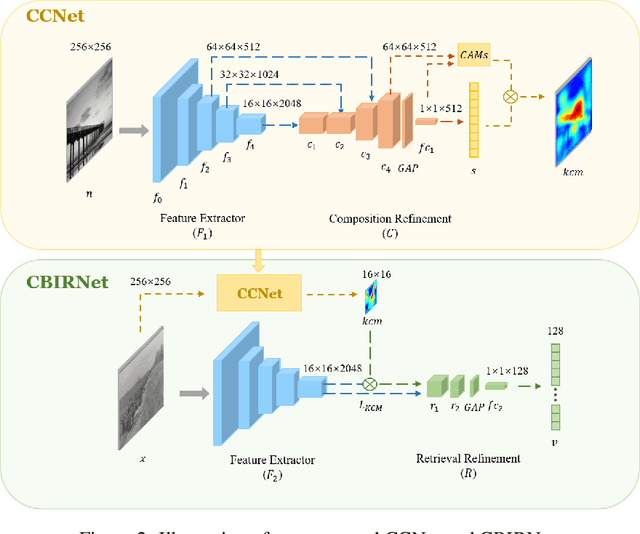
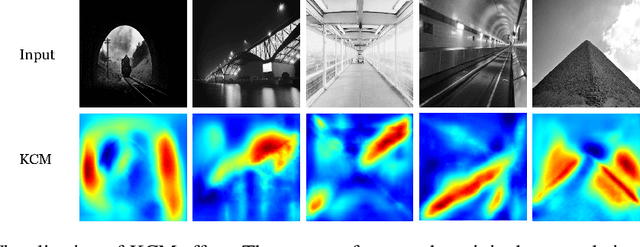
In analyzing vast amounts of digitally stored historical image data, existing content-based retrieval methods often overlook significant non-semantic information, limiting their effectiveness for flexible exploration across varied themes. To broaden the applicability of image retrieval methods for diverse purposes and uncover more general patterns, we innovatively introduce a crucial factor from computational aesthetics, namely image composition, into this topic. By explicitly integrating composition-related information extracted by CNN into the designed retrieval model, our method considers both the image's composition rules and semantic information. Qualitative and quantitative experiments demonstrate that the image retrieval network guided by composition information outperforms those relying solely on content information, facilitating the identification of images in databases closer to the target image in human perception. Please visit https://github.com/linty5/CCBIR to try our codes.
ECSIC: Epipolar Cross Attention for Stereo Image Compression
Jul 18, 2023



In this paper, we present ECSIC, a novel learned method for stereo image compression. Our proposed method compresses the left and right images in a joint manner by exploiting the mutual information between the images of the stereo image pair using a novel stereo cross attention (SCA) module and two stereo context modules. The SCA module performs cross-attention restricted to the corresponding epipolar lines of the two images and processes them in parallel. The stereo context modules improve the entropy estimation of the second encoded image by using the first image as a context. We conduct an extensive ablation study demonstrating the effectiveness of the proposed modules and a comprehensive quantitative and qualitative comparison with existing methods. ECSIC achieves state-of-the-art performance among stereo image compression models on the two popular stereo image datasets Cityscapes and InStereo2k while allowing for fast encoding and decoding, making it highly practical for real-time applications.
Feature Mixing for Writer Retrieval and Identification on Papyri Fragments
Jun 22, 2023This paper proposes a deep-learning-based approach to writer retrieval and identification for papyri, with a focus on identifying fragments associated with a specific writer and those corresponding to the same image. We present a novel neural network architecture that combines a residual backbone with a feature mixing stage to improve retrieval performance, and the final descriptor is derived from a projection layer. The methodology is evaluated on two benchmarks: PapyRow, where we achieve a mAP of 26.6 % and 24.9 % on writer and page retrieval, and HisFragIR20, showing state-of-the-art performance (44.0 % and 29.3 % mAP). Furthermore, our network has an accuracy of 28.7 % for writer identification. Additionally, we conduct experiments on the influence of two binarization techniques on fragments and show that binarizing does not enhance performance. Our code and models are available to the community.
Unsupervised Writer Retrieval using NetRVLAD and Graph Similarity Reranking
May 09, 2023This paper presents an unsupervised approach for writer retrieval based on clustering SIFT descriptors detected at keypoint locations resulting in pseudo-cluster labels. With those cluster labels, a residual network followed by our proposed NetRVLAD, an encoding layer with reduced complexity compared to NetVLAD, is trained on 32x32 patches at keypoint locations. Additionally, we suggest a graph-based reranking algorithm called SGR to exploit similarities of the page embeddings to boost the retrieval performance. Our approach is evaluated on two historical datasets (Historical-WI and HisIR19). We include an evaluation of different backbones and NetRVLAD. It competes with related work on historical datasets without using explicit encodings. We set a new State-of-the-art on both datasets by applying our reranking scheme and show that our approach achieves comparable performance on a modern dataset as well.