 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmformer: Harmonic Networks Meet Transformers for Continuous Roto-Translation Equivariance
Nov 06, 2024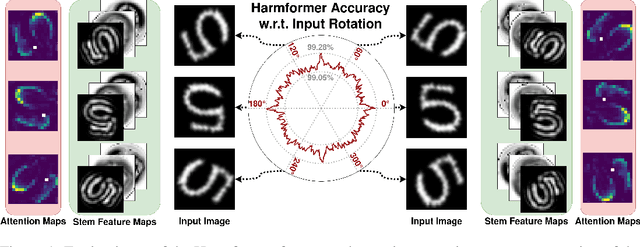

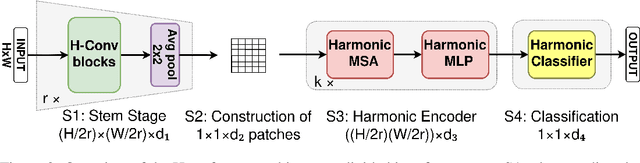
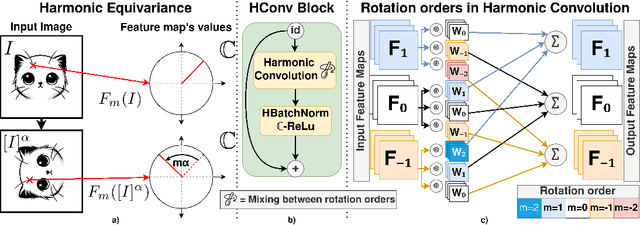
CNNs exhibit inherent equivariance to image translation, leading to efficient parameter and data usage, faster learning, and improved robustness. The concept of translation equivariant networks has been successfully extended to rotation transformation using group convolution for discrete rotation groups and harmonic functions for the continuous rotation group encompassing $360^\circ$. We explore the compatibility of the SA mechanism with full rotation equivariance, in contrast to previous studies that focused on discrete rotation. We introduce the Harmformer, a harmonic transformer with a convolutional stem that achieves equivariance for both translation and continuous rotation. Accompanied by an end-to-end equivariance proof, the Harmformer not only outperforms previous equivariant transformers, but also demonstrates inherent stability under any continuous rotation, even without seeing rotated samples during training.
Material Fingerprinting: Identifying and Predicting Perceptual Attributes of Material Appearance
Oct 17, 2024



The world is abundant with diverse materials, each possessing unique surface appearances that play a crucial role in our daily perception and understanding of their properties. Despite advancements in technology enabling the capture and realistic reproduction of material appearances for visualization and quality control, the interoperability of material property information across various measurement representations and software platforms remains a complex challenge. A key to overcoming this challenge lies in the automatic identification of materials' perceptual features, enabling intuitive differentiation of properties stored in disparate material data representations. We reasoned that for many practical purposes, a compact representation of the perceptual appearance is more useful than an exhaustive physical description.This paper introduces a novel approach to material identification by encoding perceptual features obtained from dynamic visual stimuli. We conducted a psychophysical experiment to select and validate 16 particularly significant perceptual attributes obtained from videos of 347 materials. We then gathered attribute ratings from over twenty participants for each material, creating a 'material fingerprint' that encodes the unique perceptual properties of each material. Finally, we trained a multi-layer perceptron model to predict the relationship between statistical and deep learning image features and their corresponding perceptual properties. We demonstrate the model's performance in material retrieval and filtering according to individual attributes. This model represents a significant step towards simplifying the sharing and understanding of material properties in diverse digital environments regardless of their digital representation, enhancing both the accuracy and efficiency of material identification.
ECSIC: Epipolar Cross Attention for Stereo Image Compression
Jul 18, 2023



In this paper, we present ECSIC, a novel learned method for stereo image compression. Our proposed method compresses the left and right images in a joint manner by exploiting the mutual information between the images of the stereo image pair using a novel stereo cross attention (SCA) module and two stereo context modules. The SCA module performs cross-attention restricted to the corresponding epipolar lines of the two images and processes them in parallel. The stereo context modules improve the entropy estimation of the second encoded image by using the first image as a context. We conduct an extensive ablation study demonstrating the effectiveness of the proposed modules and a comprehensive quantitative and qualitative comparison with existing methods. ECSIC achieves state-of-the-art performance among stereo image compression models on the two popular stereo image datasets Cityscapes and InStereo2k while allowing for fast encoding and decoding, making it highly practical for real-time applications.
Sub-frame Appearance and 6D Pose Estimation of Fast Moving Objects
Nov 25, 2019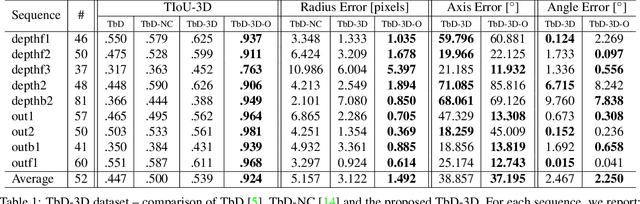



We propose a novel method that tracks fast moving objects, mainly non-uniform spherical, in full 6 degrees of freedom, estimating simultaneously their 3D motion trajectory, 3D pose and object appearance changes with a time step that is a fraction of the video frame exposure time. The sub-frame object localization and appearance estimation allows realistic temporal super-resolution and precise shape estimation. The method, called TbD-3D (Tracking by Deblatting in 3D) relies on a novel reconstruction algorithm which solves a piece-wise deblurring and matting problem. The 3D rotation is estimated by minimizing the reprojection error. As a second contribution, we present a new challenging dataset with fast moving objects that change their appearance and distance to the camera. High speed camera recordings with zero lag between frame exposures were used to generate videos with different frame rates annotated with ground-truth trajectory and pose.
Non-Causal Tracking by Deblatting
Sep 15, 2019
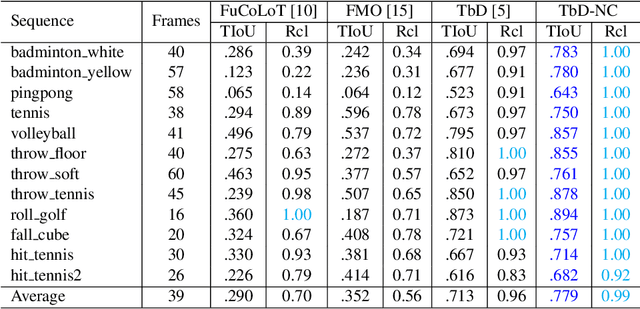


Tracking by Deblatting stands for solving an inverse problem of deblurring and image matting for tracking motion-blurred objects. We propose non-causal Tracking by Deblatting which estimates continuous, complete and accurate object trajectories. Energy minimization by dynamic programming is used to detect abrupt changes of motion, called bounces. High-order polynomials are fitted to segments, which are parts of the trajectory separated by bounces. The output is a continuous trajectory function which assigns location for every real-valued time stamp from zero to the number of frames. Additionally, we show that from the trajectory function precise physical calculations are possible, such as radius, gravity or sub-frame object velocity. Velocity estimation is compared to the high-speed camera measurements and radars. Results show high performance of the proposed method in terms of Trajectory-IoU, recall and velocity estimation.
Intra-frame Object Tracking by Deblatting
May 09, 2019
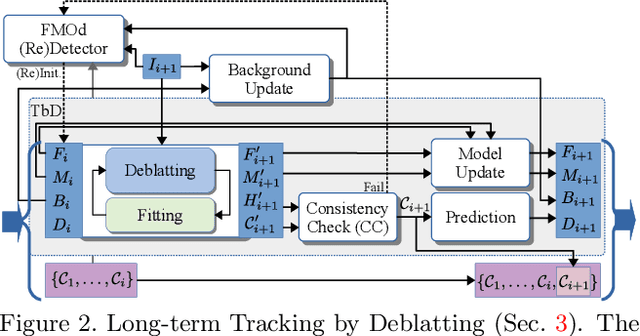
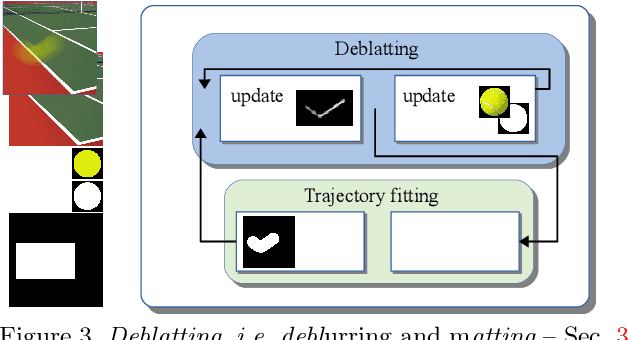
Objects moving at high speed along complex trajectories often appear in videos, especially videos of sports. Such objects elapse non-negligible distance during exposure time of a single frame and therefore their position in the frame is not well defined. They appear as semi-transparent streaks due to the motion blur and cannot be reliably tracked by standard trackers. We propose a novel approach called Tracking by Deblatting based on the observation that motion blur is directly related to the intra-frame trajectory of an object. Blur is estimated by solving two intertwined inverse problems, blind deblurring and image matting, which we call deblatting. The trajectory is then estimated by fitting a piecewise quadratic curve, which models physically justifiable trajectories. As a result, tracked objects are precisely localized with higher temporal resolution than by conventional trackers. The proposed TbD tracker was evaluated on a newly created dataset of videos with ground truth obtained by a high-speed camera using a novel Trajectory-IoU metric that generalizes the traditional Intersection over Union and measures the accuracy of the intra-frame trajectory. The proposed method outperforms baseline both in recall and trajectory accuracy.
The World of Fast Moving Objects
Nov 23, 2016

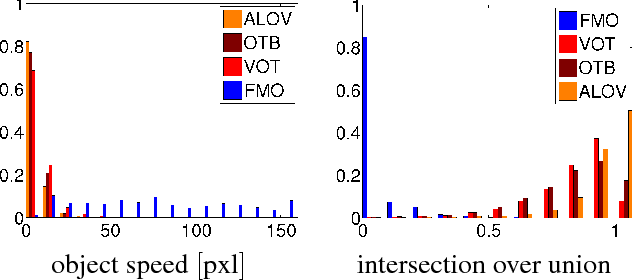
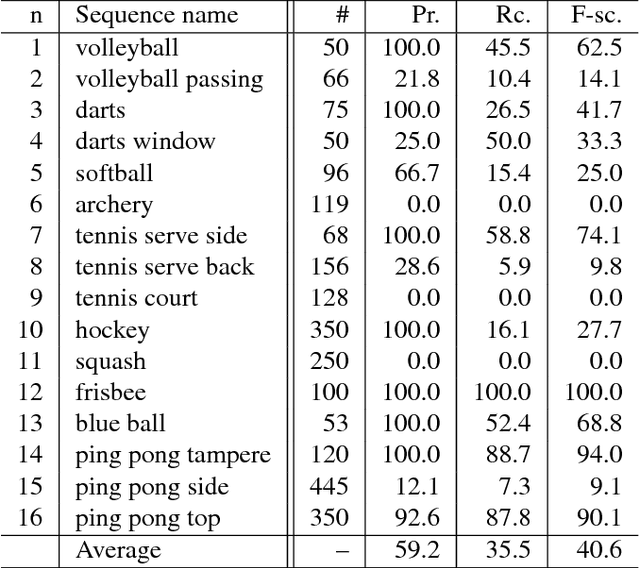
The notion of a Fast Moving Object (FMO), i.e. an object that moves over a distance exceeding its size within the exposure time, is introduced. FMOs may, and typically do, rotate with high angular speed. FMOs are very common in sports videos, but are not rare elsewhere. In a single frame, such objects are often barely visible and appear as semi-transparent streaks. A method for the detection and tracking of FMOs is proposed. The method consists of three distinct algorithms, which form an efficient localization pipeline that operates successfully in a broad range of conditions. We show that it is possible to recover the appearance of the object and its axis of rotation, despite its blurred appearance. The proposed method is evaluated on a new annotated dataset. The results show that existing trackers are inadequate for the problem of FMO localization and a new approach is required. Two applications of localization, temporal super-resolution and highlighting, are presented.