 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Scene Modeling: Narrowing the Gap Between Supervised and Self-Supervised Learning in 3D Scene Understanding
Apr 09, 2025Self-supervised learning has transformed 2D computer vision by enabling models trained on large, unannotated datasets to provide versatile off-the-shelf features that perform similarly to models trained with labels. However, in 3D scene understanding, self-supervised methods are typically only used as a weight initialization step for task-specific fine-tuning, limiting their utility for general-purpose feature extraction. This paper addresses this shortcoming by proposing a robust evaluation protocol specifically designed to assess the quality of self-supervised features for 3D scene understanding. Our protocol uses multi-resolution feature sampling of hierarchical models to create rich point-level representations that capture the semantic capabilities of the model and, hence, are suitable for evaluation with linear probing and nearest-neighbor methods. Furthermore, we introduce the first self-supervised model that performs similarly to supervised models when only off-the-shelf features are used in a linear probing setup. In particular, our model is trained natively in 3D with a novel self-supervised approach based on a Masked Scene Modeling objective, which reconstructs deep features of masked patches in a bottom-up manner and is specifically tailored to hierarchical 3D models. Our experiments not only demonstrate that our method achieves competitive performance to supervised models, but also surpasses existing self-supervised approaches by a large margin. The model and training code can be found at our Github repository (https://github.com/phermosilla/msm).
Fusing Forces: Deep-Human-Guided Refinement of Segmentation Masks
Aug 06, 2024Etruscan mirrors constitute a significant category in Etruscan art, characterized by elaborate figurative illustrations featured on their backside. A laborious and costly aspect of their analysis and documentation is the task of manually tracing these illustrations. In previous work, a methodology has been proposed to automate this process, involving photometric-stereo scanning in combination with deep neural networks. While achieving quantitative performance akin to an expert annotator, some results still lack qualitative precision and, thus, require annotators for inspection and potential correction, maintaining resource intensity. In response, we propose a deep neural network trained to interactively refine existing annotations based on human guidance. Our human-in-the-loop approach streamlines annotation, achieving equal quality with up to 75% less manual input required. Moreover, during the refinement process, the relative improvement of our methodology over pure manual labeling reaches peak values of up to 26%, attaining drastically better quality quicker. By being tailored to the complex task of segmenting intricate lines, specifically distinguishing it from previous methods, our approach offers drastic improvements in efficacy, transferable to a broad spectrum of applications beyond Etruscan mirrors.
Closing the Gap in Human Behavior Analysis: A Pipeline for Synthesizing Trimodal Data
Feb 02, 2024

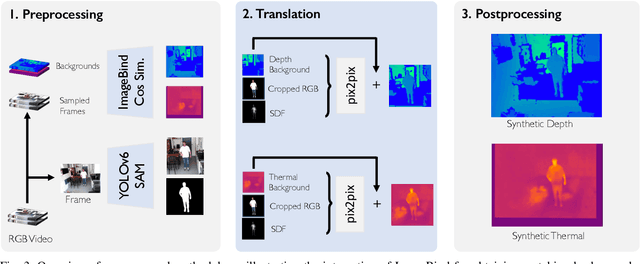
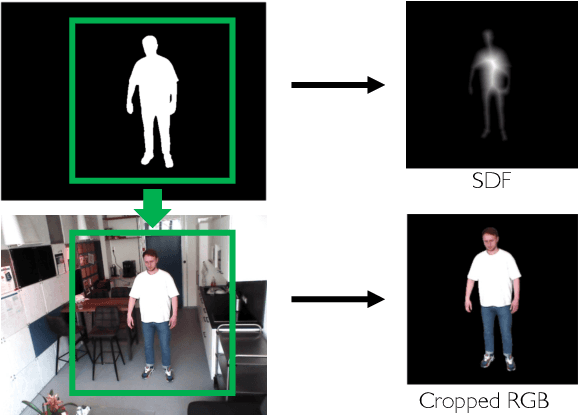
In pervasive machine learning, especially in Human Behavior Analysis (HBA), RGB has been the primary modality due to its accessibility and richness of information. However, linked with its benefits are challenges, including sensitivity to lighting conditions and privacy concerns. One possibility to overcome these vulnerabilities is to resort to different modalities. For instance, thermal is particularly adept at accentuating human forms, while depth adds crucial contextual layers. Despite their known benefits, only a few HBA-specific datasets that integrate these modalities exist. To address this shortage, our research introduces a novel generative technique for creating trimodal, i.e., RGB, thermal, and depth, human-focused datasets. This technique capitalizes on human segmentation masks derived from RGB images, combined with thermal and depth backgrounds that are sourced automatically. With these two ingredients, we synthesize depth and thermal counterparts from existing RGB data utilizing conditional image-to-image translation. By employing this approach, we generate trimodal data that can be leveraged to train models for settings with limited data, bad lightning conditions, or privacy-sensitive areas.
Through-Wall Imaging based on WiFi Channel State Information
Jan 30, 2024
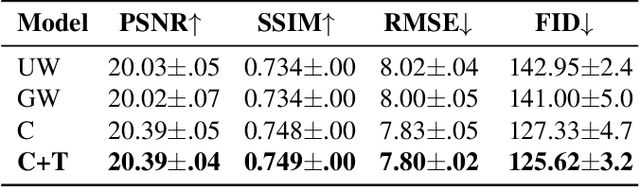
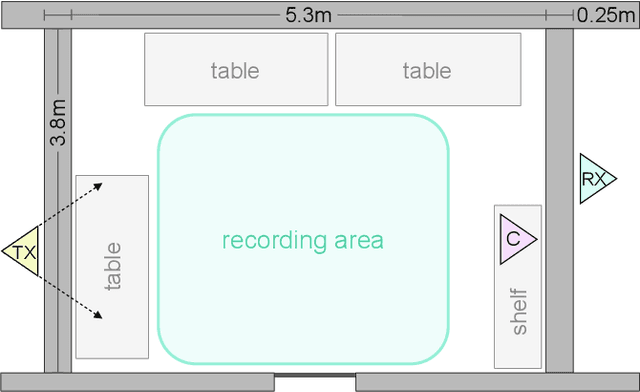
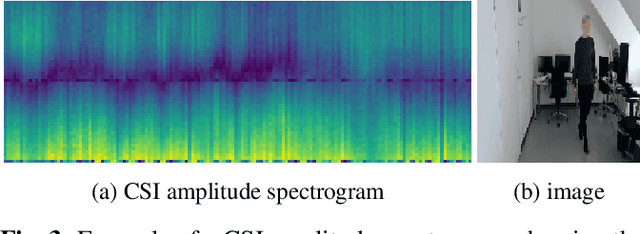
This work presents a seminal approach for synthesizing images from WiFi Channel State Information (CSI) in through-wall scenarios. Leveraging the strengths of WiFi, such as cost-effectiveness, illumination invariance, and wall-penetrating capabilities, our approach enables visual monitoring of indoor environments beyond room boundaries and without the need for cameras. More generally, it improves the interpretability of WiFi CSI by unlocking the option to perform image-based downstream tasks, e.g., visual activity recognition. In order to achieve this crossmodal translation from WiFi CSI to images, we rely on a multimodal Variational Autoencoder (VAE) adapted to our problem specifics. We extensively evaluate our proposed methodology through an ablation study on architecture configuration and a quantitative/qualitative assessment of reconstructed images. Our results demonstrate the viability of our method and highlight its potential for practical applications.