 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Egocentric 3D Hand Pose Estimation in Unseen Domains
Jan 10, 2026We present V-HPOT, a novel approach for improving the cross-domain performance of 3D hand pose estimation from egocentric images across diverse, unseen domains. State-of-the-art methods demonstrate strong performance when trained and tested within the same domain. However, they struggle to generalise to new environments due to limited training data and depth perception -- overfitting to specific camera intrinsics. Our method addresses this by estimating keypoint z-coordinates in a virtual camera space, normalised by focal length and image size, enabling camera-agnostic depth prediction. We further leverage this invariance to camera intrinsics to propose a self-supervised test-time optimisation strategy that refines the model's depth perception during inference. This is achieved by applying a 3D consistency loss between predicted and in-space scale-transformed hand poses, allowing the model to adapt to target domain characteristics without requiring ground truth annotations. V-HPOT significantly improves 3D hand pose estimation performance in cross-domain scenarios, achieving a 71% reduction in mean pose error on the H2O dataset and a 41% reduction on the AssemblyHands dataset. Compared to state-of-the-art methods, V-HPOT outperforms all single-stage approaches across all datasets and competes closely with two-stage methods, despite needing approximately x3.5 to x14 less data.
DATTA: Domain-Adversarial Test-Time Adaptation for Cross-Domain WiFi-Based Human Activity Recognition
Nov 20, 2024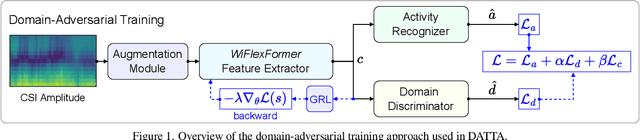

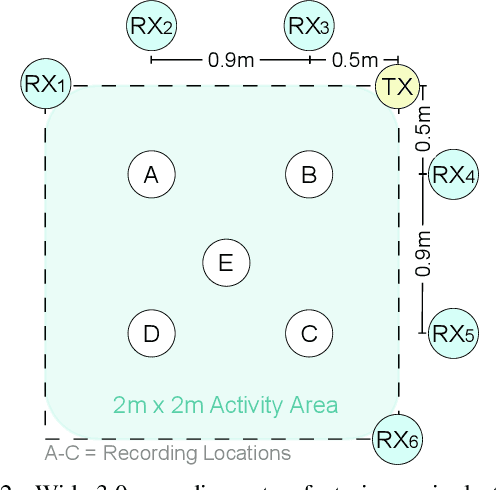
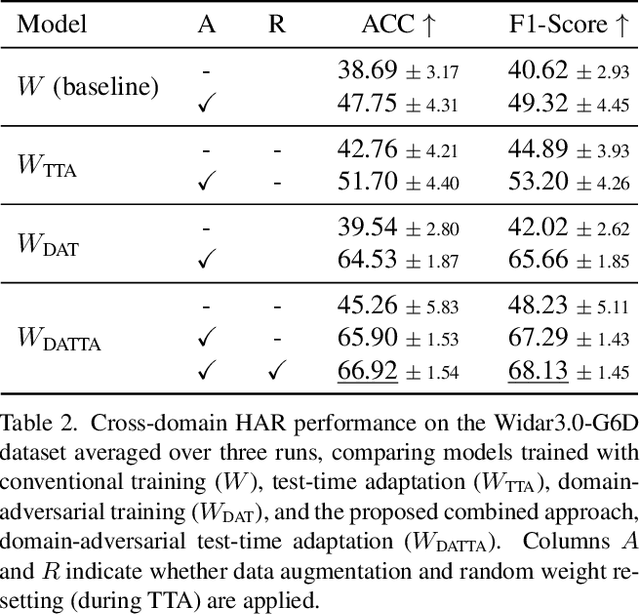
Cross-domain generalization is an open problem in WiFi-based sensing due to variations in environments, devices, and subjects, causing domain shifts in channel state information. To address this, we propose Domain-Adversarial Test-Time Adaptation (DATTA), a novel framework combining domain-adversarial training (DAT), test-time adaptation (TTA), and weight resetting to facilitate adaptation to unseen target domains and to prevent catastrophic forgetting. DATTA is integrated into a lightweight, flexible architecture optimized for speed. We conduct a comprehensive evaluation of DATTA, including an ablation study on all key components using publicly available data, and verify its suitability for real-time applications such as human activity recognition. When combining a SotA video-based variant of TTA with WiFi-based DAT and comparing it to DATTA, our method achieves an 8.1% higher F1-Score. The PyTorch implementation of DATTA is publicly available at: https://github.com/StrohmayerJ/DATTA.
WiFlexFormer: Efficient WiFi-Based Person-Centric Sensing
Nov 06, 2024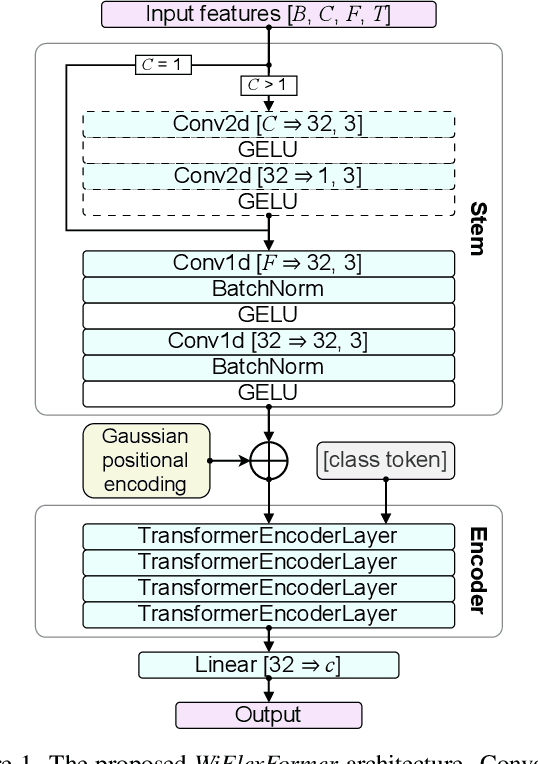
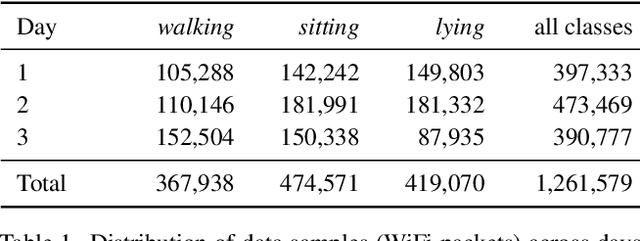
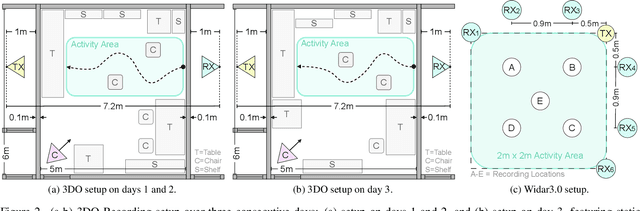
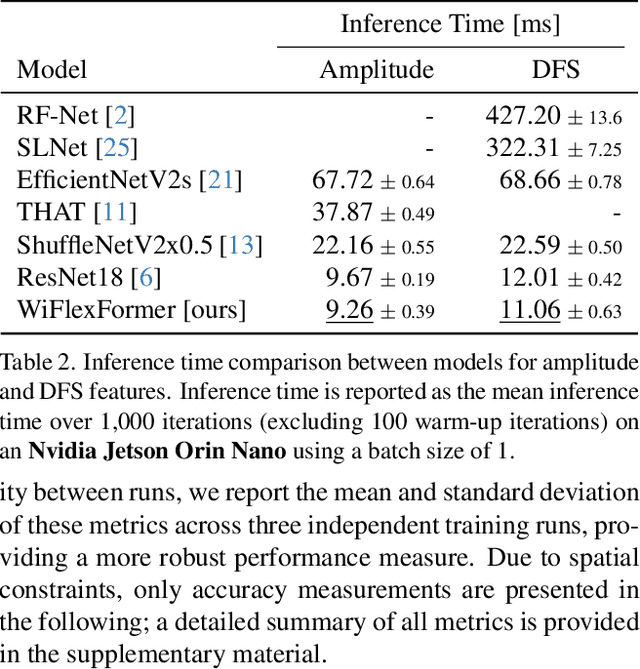
We propose WiFlexFormer, a highly efficient Transformer-based architecture designed for WiFi Channel State Information (CSI)-based person-centric sensing. We benchmark WiFlexFormer against state-of-the-art vision and specialized architectures for processing radio frequency data and demonstrate that it achieves comparable Human Activity Recognition (HAR) performance while offering a significantly lower parameter count and faster inference times. With an inference time of just 10 ms on an Nvidia Jetson Orin Nano, WiFlexFormer is optimized for real-time inference. Additionally, its low parameter count contributes to improved cross-domain generalization, where it often outperforms larger models. Our comprehensive evaluation shows that WiFlexFormer is a potential solution for efficient, scalable WiFi-based sensing applications. The PyTorch implementation of WiFlexFormer is publicly available at: https://github.com/StrohmayerJ/WiFlexFormer.
FISHing in Uncertainty: Synthetic Contrastive Learning for Genetic Aberration Detection
Nov 01, 2024Detecting genetic aberrations is crucial in cancer diagnosis, typically through fluorescence in situ hybridization (FISH). However, existing FISH image classification methods face challenges due to signal variability, the need for costly manual annotations and fail to adequately address the intrinsic uncertainty. We introduce a novel approach that leverages synthetic images to eliminate the requirement for manual annotations and utilizes a joint contrastive and classification objective for training to account for inter-class variation effectively. We demonstrate the superior generalization capabilities and uncertainty calibration of our method, which is trained on synthetic data, by testing it on a manually annotated dataset of real-world FISH images. Our model offers superior calibration in terms of classification accuracy and uncertainty quantification with a classification accuracy of 96.7% among the 50% most certain cases. The presented end-to-end method reduces the demands on personnel and time and improves the diagnostic workflow due to its accuracy and adaptability. All code and data is publicly accessible at: https://github.com/SimonBon/FISHing
REST-HANDS: Rehabilitation with Egocentric Vision Using Smartglasses for Treatment of Hands after Surviving Stroke
Sep 30, 2024Stroke represents the third cause of death and disability worldwide, and is recognised as a significant global health problem. A major challenge for stroke survivors is persistent hand dysfunction, which severely affects the ability to perform daily activities and the overall quality of life. In order to regain their functional hand ability, stroke survivors need rehabilitation therapy. However, traditional rehabilitation requires continuous medical support, creating dependency on an overburdened healthcare system. In this paper, we explore the use of egocentric recordings from commercially available smart glasses, specifically RayBan Stories, for remote hand rehabilitation. Our approach includes offline experiments to evaluate the potential of smart glasses for automatic exercise recognition, exercise form evaluation and repetition counting. We present REST-HANDS, the first dataset of egocentric hand exercise videos. Using state-of-the-art methods, we establish benchmarks with high accuracy rates for exercise recognition (98.55%), form evaluation (86.98%), and repetition counting (mean absolute error of 1.33). Our study demonstrates the feasibility of using egocentric video from smart glasses for remote rehabilitation, paving the way for further research.
SPiKE: 3D Human Pose from Point Cloud Sequences
Sep 03, 2024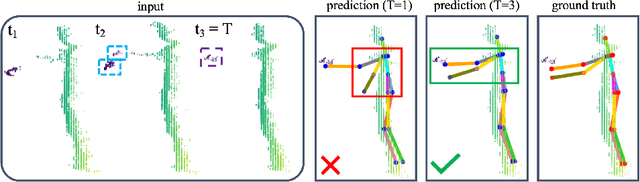
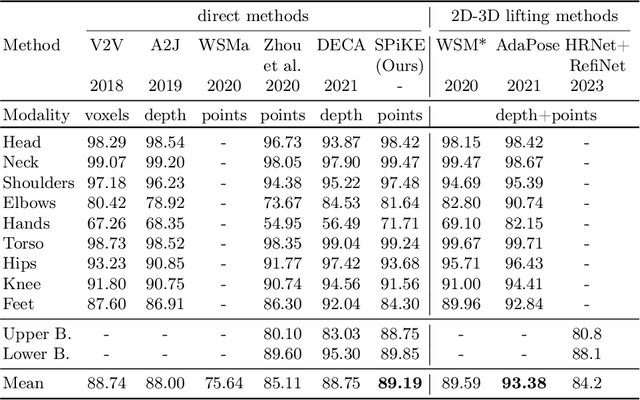
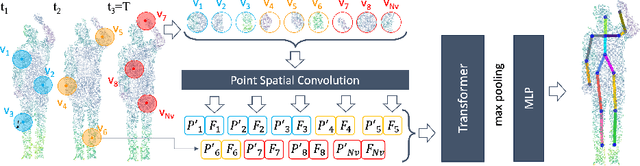
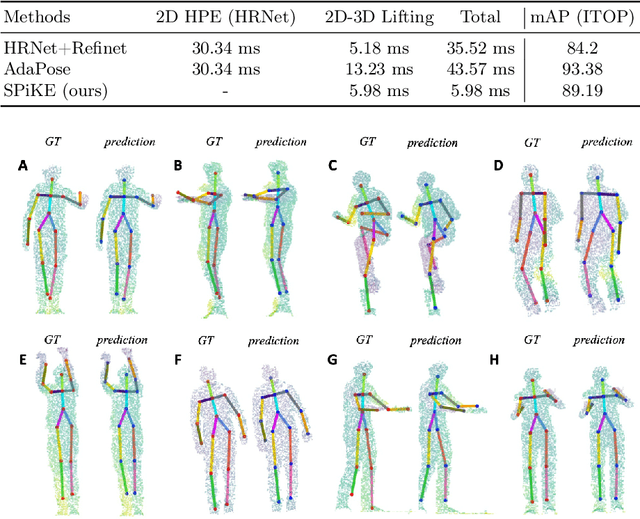
3D Human Pose Estimation (HPE) is the task of locating keypoints of the human body in 3D space from 2D or 3D representations such as RGB images, depth maps or point clouds. Current HPE methods from depth and point clouds predominantly rely on single-frame estimation and do not exploit temporal information from sequences. This paper presents SPiKE, a novel approach to 3D HPE using point cloud sequences. Unlike existing methods that process frames of a sequence independently, SPiKE leverages temporal context by adopting a Transformer architecture to encode spatio-temporal relationships between points across the sequence. By partitioning the point cloud into local volumes and using spatial feature extraction via point spatial convolution, SPiKE ensures efficient processing by the Transformer while preserving spatial integrity per timestamp. Experiments on the ITOP benchmark for 3D HPE show that SPiKE reaches 89.19% mAP, achieving state-of-the-art performance with significantly lower inference times. Extensive ablations further validate the effectiveness of sequence exploitation and our algorithmic choices. Code and models are available at: https://github.com/iballester/SPiKE
SHARP: Segmentation of Hands and Arms by Range using Pseudo-Depth for Enhanced Egocentric 3D Hand Pose Estimation and Action Recognition
Aug 19, 2024



Hand pose represents key information for action recognition in the egocentric perspective, where the user is interacting with objects. We propose to improve egocentric 3D hand pose estimation based on RGB frames only by using pseudo-depth images. Incorporating state-of-the-art single RGB image depth estimation techniques, we generate pseudo-depth representations of the frames and use distance knowledge to segment irrelevant parts of the scene. The resulting depth maps are then used as segmentation masks for the RGB frames. Experimental results on H2O Dataset confirm the high accuracy of the estimated pose with our method in an action recognition task. The 3D hand pose, together with information from object detection, is processed by a transformer-based action recognition network, resulting in an accuracy of 91.73%, outperforming all state-of-the-art methods. Estimations of 3D hand pose result in competitive performance with existing methods with a mean pose error of 28.66 mm. This method opens up new possibilities for employing distance information in egocentric 3D hand pose estimation without relying on depth sensors.
In My Perspective, In My Hands: Accurate Egocentric 2D Hand Pose and Action Recognition
Apr 14, 2024



Action recognition is essential for egocentric video understanding, allowing automatic and continuous monitoring of Activities of Daily Living (ADLs) without user effort. Existing literature focuses on 3D hand pose input, which requires computationally intensive depth estimation networks or wearing an uncomfortable depth sensor. In contrast, there has been insufficient research in understanding 2D hand pose for egocentric action recognition, despite the availability of user-friendly smart glasses in the market capable of capturing a single RGB image. Our study aims to fill this research gap by exploring the field of 2D hand pose estimation for egocentric action recognition, making two contributions. Firstly, we introduce two novel approaches for 2D hand pose estimation, namely EffHandNet for single-hand estimation and EffHandEgoNet, tailored for an egocentric perspective, capturing interactions between hands and objects. Both methods outperform state-of-the-art models on H2O and FPHA public benchmarks. Secondly, we present a robust action recognition architecture from 2D hand and object poses. This method incorporates EffHandEgoNet, and a transformer-based action recognition method. Evaluated on H2O and FPHA datasets, our architecture has a faster inference time and achieves an accuracy of 91.32% and 94.43%, respectively, surpassing state of the art, including 3D-based methods. Our work demonstrates that using 2D skeletal data is a robust approach for egocentric action understanding. Extensive evaluation and ablation studies show the impact of the hand pose estimation approach, and how each input affects the overall performance.
Closing the Gap in Human Behavior Analysis: A Pipeline for Synthesizing Trimodal Data
Feb 02, 2024

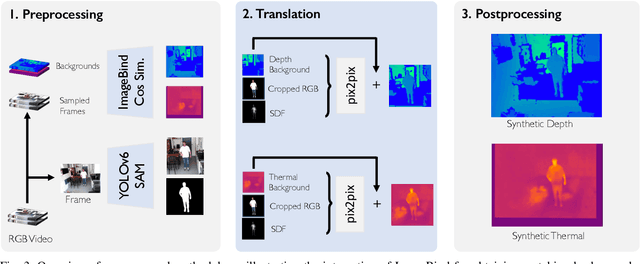
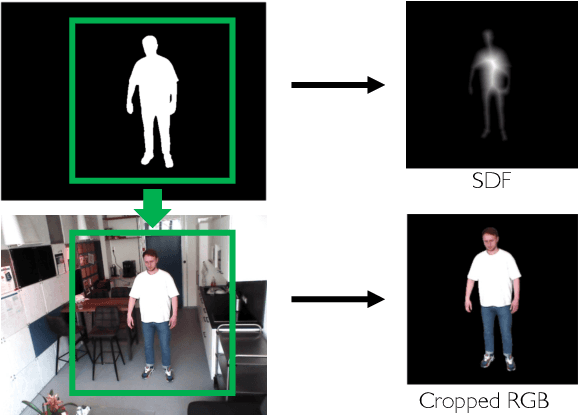
In pervasive machine learning, especially in Human Behavior Analysis (HBA), RGB has been the primary modality due to its accessibility and richness of information. However, linked with its benefits are challenges, including sensitivity to lighting conditions and privacy concerns. One possibility to overcome these vulnerabilities is to resort to different modalities. For instance, thermal is particularly adept at accentuating human forms, while depth adds crucial contextual layers. Despite their known benefits, only a few HBA-specific datasets that integrate these modalities exist. To address this shortage, our research introduces a novel generative technique for creating trimodal, i.e., RGB, thermal, and depth, human-focused datasets. This technique capitalizes on human segmentation masks derived from RGB images, combined with thermal and depth backgrounds that are sourced automatically. With these two ingredients, we synthesize depth and thermal counterparts from existing RGB data utilizing conditional image-to-image translation. By employing this approach, we generate trimodal data that can be leveraged to train models for settings with limited data, bad lightning conditions, or privacy-sensitive areas.
Through-Wall Imaging based on WiFi Channel State Information
Jan 30, 2024
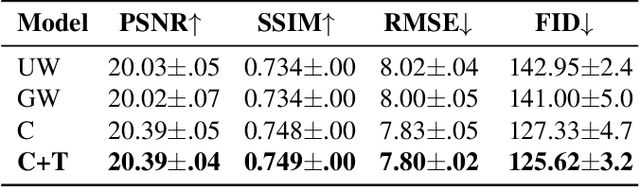
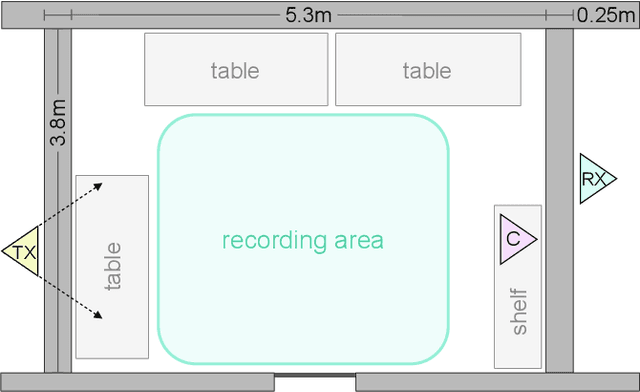
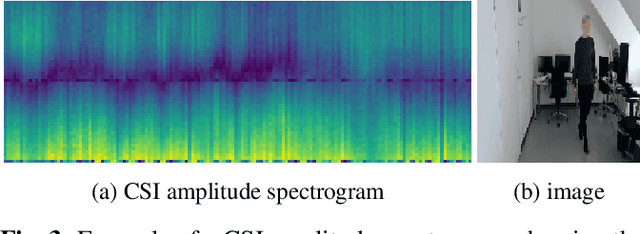
This work presents a seminal approach for synthesizing images from WiFi Channel State Information (CSI) in through-wall scenarios. Leveraging the strengths of WiFi, such as cost-effectiveness, illumination invariance, and wall-penetrating capabilities, our approach enables visual monitoring of indoor environments beyond room boundaries and without the need for cameras. More generally, it improves the interpretability of WiFi CSI by unlocking the option to perform image-based downstream tasks, e.g., visual activity recognition. In order to achieve this crossmodal translation from WiFi CSI to images, we rely on a multimodal Variational Autoencoder (VAE) adapted to our problem specifics. We extensively evaluate our proposed methodology through an ablation study on architecture configuration and a quantitative/qualitative assessment of reconstructed images. Our results demonstrate the viability of our method and highlight its potential for practical applications.