 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Connectivity-Aware Text Line Segmentation in Historical Documents
Aug 26, 2025A foundational task for the digital analysis of documents is text line segmentation. However, automating this process with deep learning models is challenging because it requires large, annotated datasets that are often unavailable for historical documents. Additionally, the annotation process is a labor- and cost-intensive task that requires expert knowledge, which makes few-shot learning a promising direction for reducing data requirements. In this work, we demonstrate that small and simple architectures, coupled with a topology-aware loss function, are more accurate and data-efficient than more complex alternatives. We pair a lightweight UNet++ with a connectivity-aware loss, initially developed for neuron morphology, which explicitly penalizes structural errors like line fragmentation and unintended line merges. To increase our limited data, we train on small patches extracted from a mere three annotated pages per manuscript. Our methodology significantly improves upon the current state-of-the-art on the U-DIADS-TL dataset, with a 200% increase in Recognition Accuracy and a 75% increase in Line Intersection over Union. Our method also achieves an F-Measure score on par with or even exceeding that of the competition winner of the DIVA-HisDB baseline detection task, all while requiring only three annotated pages, exemplifying the efficacy of our approach. Our implementation is publicly available at: https://github.com/RafaelSterzinger/acpr_few_shot_hist.
DATTA: Domain-Adversarial Test-Time Adaptation for Cross-Domain WiFi-Based Human Activity Recognition
Nov 20, 2024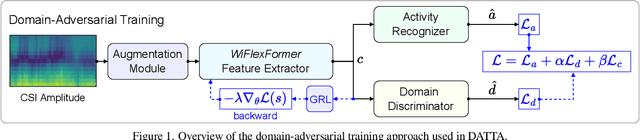

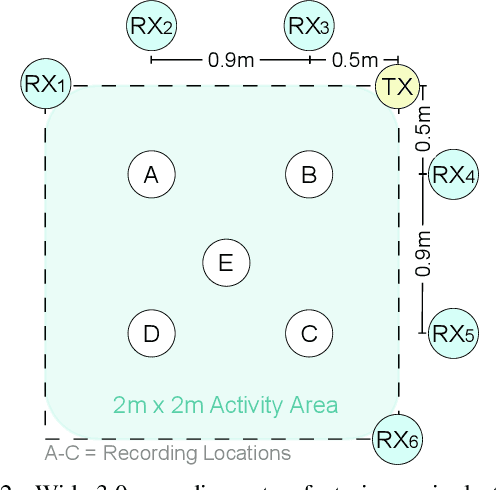
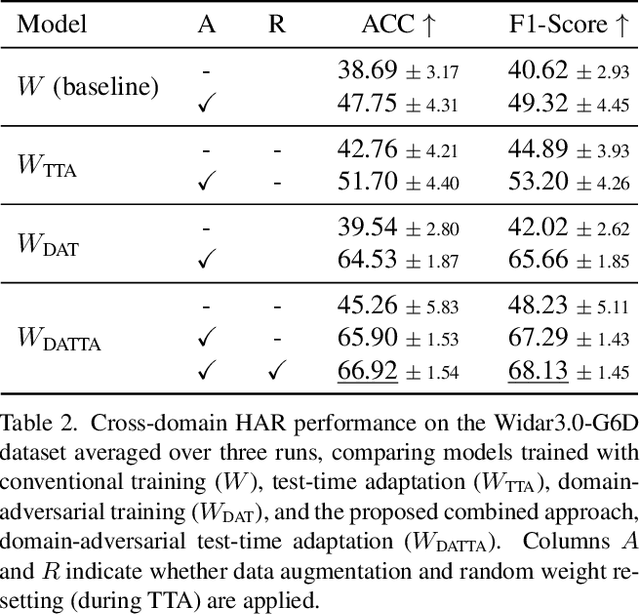
Cross-domain generalization is an open problem in WiFi-based sensing due to variations in environments, devices, and subjects, causing domain shifts in channel state information. To address this, we propose Domain-Adversarial Test-Time Adaptation (DATTA), a novel framework combining domain-adversarial training (DAT), test-time adaptation (TTA), and weight resetting to facilitate adaptation to unseen target domains and to prevent catastrophic forgetting. DATTA is integrated into a lightweight, flexible architecture optimized for speed. We conduct a comprehensive evaluation of DATTA, including an ablation study on all key components using publicly available data, and verify its suitability for real-time applications such as human activity recognition. When combining a SotA video-based variant of TTA with WiFi-based DAT and comparing it to DATTA, our method achieves an 8.1% higher F1-Score. The PyTorch implementation of DATTA is publicly available at: https://github.com/StrohmayerJ/DATTA.
Fusing Forces: Deep-Human-Guided Refinement of Segmentation Masks
Aug 06, 2024Etruscan mirrors constitute a significant category in Etruscan art, characterized by elaborate figurative illustrations featured on their backside. A laborious and costly aspect of their analysis and documentation is the task of manually tracing these illustrations. In previous work, a methodology has been proposed to automate this process, involving photometric-stereo scanning in combination with deep neural networks. While achieving quantitative performance akin to an expert annotator, some results still lack qualitative precision and, thus, require annotators for inspection and potential correction, maintaining resource intensity. In response, we propose a deep neural network trained to interactively refine existing annotations based on human guidance. Our human-in-the-loop approach streamlines annotation, achieving equal quality with up to 75% less manual input required. Moreover, during the refinement process, the relative improvement of our methodology over pure manual labeling reaches peak values of up to 26%, attaining drastically better quality quicker. By being tailored to the complex task of segmenting intricate lines, specifically distinguishing it from previous methods, our approach offers drastic improvements in efficacy, transferable to a broad spectrum of applications beyond Etruscan mirrors.
Drawing the Line: Deep Segmentation for Extracting Art from Ancient Etruscan Mirrors
Apr 24, 2024Etruscan mirrors constitute a significant category within Etruscan art and, therefore, undergo systematic examinations to obtain insights into ancient times. A crucial aspect of their analysis involves the labor-intensive task of manually tracing engravings from the backside. Additionally, this task is inherently challenging due to the damage these mirrors have sustained, introducing subjectivity into the process. We address these challenges by automating the process through photometric-stereo scanning in conjunction with deep segmentation networks which, however, requires effective usage of the limited data at hand. We accomplish this by incorporating predictions on a per-patch level, and various data augmentations, as well as exploring self-supervised learning. Compared to our baseline, we improve predictive performance w.r.t. the pseudo-F-Measure by around 16%. When assessing performance on complete mirrors against a human baseline, our approach yields quantitative similar performance to a human annotator and significantly outperforms existing binarization methods. With our proposed methodology, we streamline the annotation process, enhance its objectivity, and reduce overall workload, offering a valuable contribution to the examination of these historical artifacts and other non-traditional documents.
Closing the Gap in Human Behavior Analysis: A Pipeline for Synthesizing Trimodal Data
Feb 02, 2024

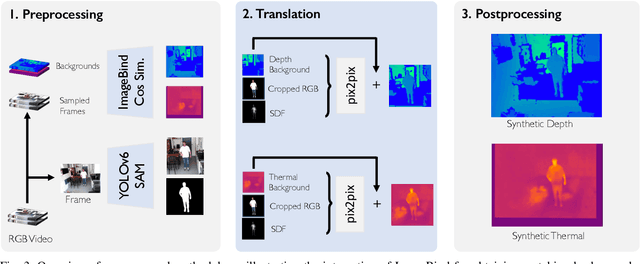
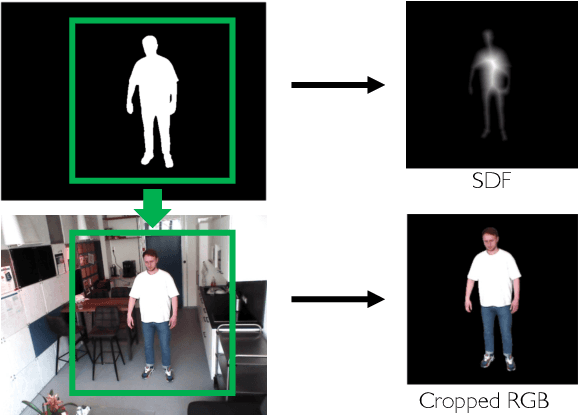
In pervasive machine learning, especially in Human Behavior Analysis (HBA), RGB has been the primary modality due to its accessibility and richness of information. However, linked with its benefits are challenges, including sensitivity to lighting conditions and privacy concerns. One possibility to overcome these vulnerabilities is to resort to different modalities. For instance, thermal is particularly adept at accentuating human forms, while depth adds crucial contextual layers. Despite their known benefits, only a few HBA-specific datasets that integrate these modalities exist. To address this shortage, our research introduces a novel generative technique for creating trimodal, i.e., RGB, thermal, and depth, human-focused datasets. This technique capitalizes on human segmentation masks derived from RGB images, combined with thermal and depth backgrounds that are sourced automatically. With these two ingredients, we synthesize depth and thermal counterparts from existing RGB data utilizing conditional image-to-image translation. By employing this approach, we generate trimodal data that can be leveraged to train models for settings with limited data, bad lightning conditions, or privacy-sensitive areas.
Through-Wall Imaging based on WiFi Channel State Information
Jan 30, 2024
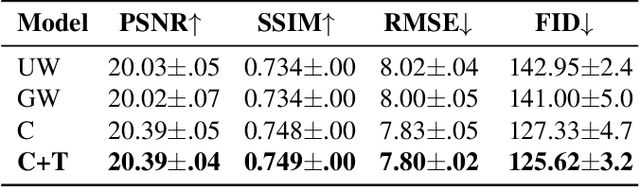
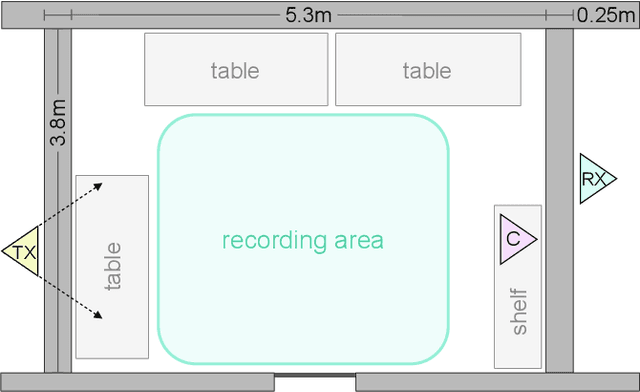
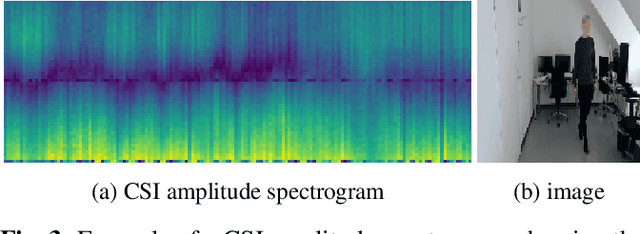
This work presents a seminal approach for synthesizing images from WiFi Channel State Information (CSI) in through-wall scenarios. Leveraging the strengths of WiFi, such as cost-effectiveness, illumination invariance, and wall-penetrating capabilities, our approach enables visual monitoring of indoor environments beyond room boundaries and without the need for cameras. More generally, it improves the interpretability of WiFi CSI by unlocking the option to perform image-based downstream tasks, e.g., visual activity recognition. In order to achieve this crossmodal translation from WiFi CSI to images, we rely on a multimodal Variational Autoencoder (VAE) adapted to our problem specifics. We extensively evaluate our proposed methodology through an ablation study on architecture configuration and a quantitative/qualitative assessment of reconstructed images. Our results demonstrate the viability of our method and highlight its potential for practical applications.