 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawing the Line: Deep Segmentation for Extracting Art from Ancient Etruscan Mirrors
Apr 24, 2024Etruscan mirrors constitute a significant category within Etruscan art and, therefore, undergo systematic examinations to obtain insights into ancient times. A crucial aspect of their analysis involves the labor-intensive task of manually tracing engravings from the backside. Additionally, this task is inherently challenging due to the damage these mirrors have sustained, introducing subjectivity into the process. We address these challenges by automating the process through photometric-stereo scanning in conjunction with deep segmentation networks which, however, requires effective usage of the limited data at hand. We accomplish this by incorporating predictions on a per-patch level, and various data augmentations, as well as exploring self-supervised learning. Compared to our baseline, we improve predictive performance w.r.t. the pseudo-F-Measure by around 16%. When assessing performance on complete mirrors against a human baseline, our approach yields quantitative similar performance to a human annotator and significantly outperforms existing binarization methods. With our proposed methodology, we streamline the annotation process, enhance its objectivity, and reduce overall workload, offering a valuable contribution to the examination of these historical artifacts and other non-traditional documents.
Subjective Assessments of Legibility in Ancient Manuscript Images -- The SALAMI Dataset
Feb 19, 2021

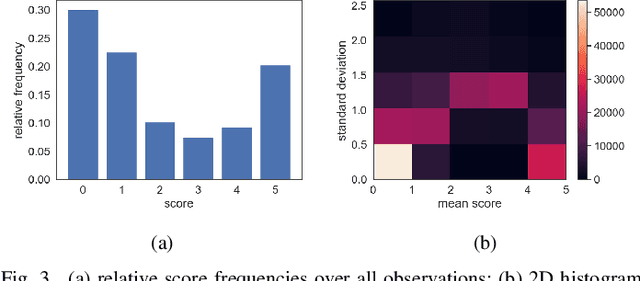
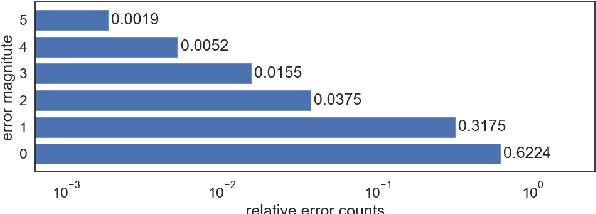
The research field concerned with the digital restoration of degraded written heritage lacks a quantitative metric for evaluating its results, which prevents the comparison of relevant methods on large datasets. Thus, we introduce a novel dataset of Subjective Assessments of Legibility in Ancient Manuscript Images (SALAMI) to serve as a ground truth for the development of quantitative evaluation metrics in the field of digital text restoration. This dataset consists of 250 images of 50 manuscript regions with corresponding spatial maps of mean legibility and uncertainty, which are based on a study conducted with 20 experts of philology and paleography. As this study is the first of its kind, the validity and reliability of its design and the results obtained are motivated statistically: we report a high intra- and inter-rater agreement and show that the bulk of variation in the scores is introduced by the images regions observed and not by controlled or uncontrolled properties of participants and test environments, thus concluding that the legibility scores measured are valid attributes of the underlying images.