 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Connectivity-Aware Text Line Segmentation in Historical Documents
Aug 26, 2025A foundational task for the digital analysis of documents is text line segmentation. However, automating this process with deep learning models is challenging because it requires large, annotated datasets that are often unavailable for historical documents. Additionally, the annotation process is a labor- and cost-intensive task that requires expert knowledge, which makes few-shot learning a promising direction for reducing data requirements. In this work, we demonstrate that small and simple architectures, coupled with a topology-aware loss function, are more accurate and data-efficient than more complex alternatives. We pair a lightweight UNet++ with a connectivity-aware loss, initially developed for neuron morphology, which explicitly penalizes structural errors like line fragmentation and unintended line merges. To increase our limited data, we train on small patches extracted from a mere three annotated pages per manuscript. Our methodology significantly improves upon the current state-of-the-art on the U-DIADS-TL dataset, with a 200% increase in Recognition Accuracy and a 75% increase in Line Intersection over Union. Our method also achieves an F-Measure score on par with or even exceeding that of the competition winner of the DIVA-HisDB baseline detection task, all while requiring only three annotated pages, exemplifying the efficacy of our approach. Our implementation is publicly available at: https://github.com/RafaelSterzinger/acpr_few_shot_hist.
Enhancing Historical Image Retrieval with Compositional Cues
Mar 21, 2024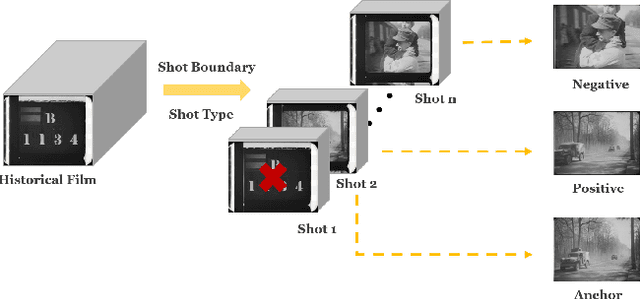

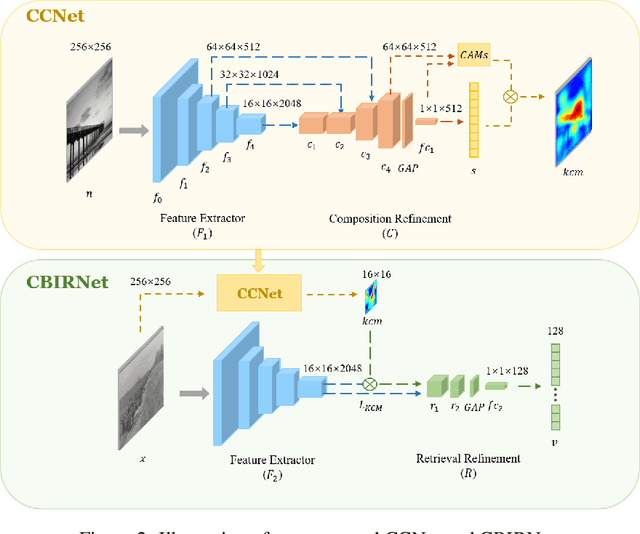
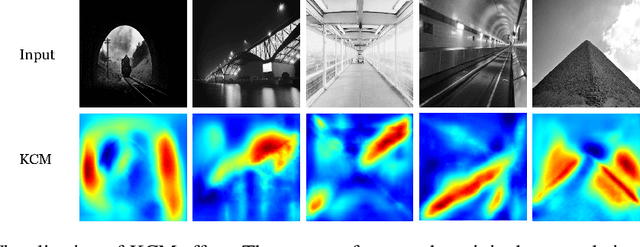
In analyzing vast amounts of digitally stored historical image data, existing content-based retrieval methods often overlook significant non-semantic information, limiting their effectiveness for flexible exploration across varied themes. To broaden the applicability of image retrieval methods for diverse purposes and uncover more general patterns, we innovatively introduce a crucial factor from computational aesthetics, namely image composition, into this topic. By explicitly integrating composition-related information extracted by CNN into the designed retrieval model, our method considers both the image's composition rules and semantic information. Qualitative and quantitative experiments demonstrate that the image retrieval network guided by composition information outperforms those relying solely on content information, facilitating the identification of images in databases closer to the target image in human perception. Please visit https://github.com/linty5/CCBIR to try our codes.
CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Nov 14, 2023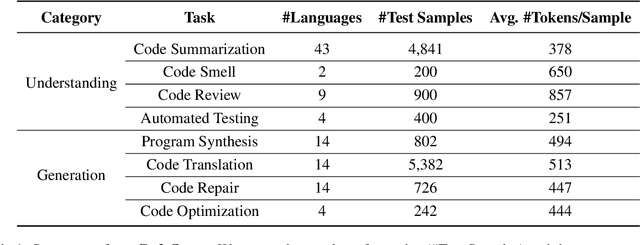
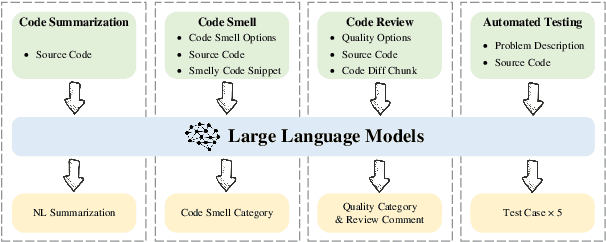

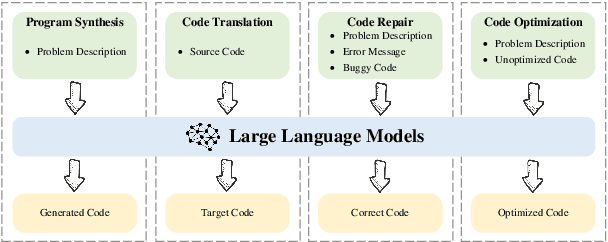
Large Language Models (LLMs) have demonstrated remarkable performance on coding related tasks, particularly on assisting humans in programming and facilitating programming automation. However, existing benchmarks for evaluating the code understanding and generation capacities of LLMs suffer from severe limitations. First, most benchmarks are deficient as they focus on a narrow range of popular programming languages and specific tasks, whereas the real-world software development scenarios show dire need to implement systems with multilingual programming environments to satisfy diverse requirements. Practical programming practices also strongly expect multi-task settings for testing coding capabilities of LLMs comprehensively and robustly. Second, most benchmarks also fail to consider the actual executability and the consistency of execution results of the generated code. To bridge these gaps between existing benchmarks and expectations from practical applications, we introduce CodeScope, an execution-based, multilingual, multi-task, multi-dimensional evaluation benchmark for comprehensively gauging LLM capabilities on coding tasks. CodeScope covers 43 programming languages and 8 coding tasks. It evaluates the coding performance of LLMs from three dimensions (perspectives): difficulty, efficiency, and length. To facilitate execution-based evaluations of code generation, we develop MultiCodeEngine, an automated code execution engine that supports 14 programming languages. Finally, we systematically evaluate and analyze 8 mainstream LLMs on CodeScope tasks and demonstrate the superior breadth and challenges of CodeScope for evaluating LLMs on code understanding and generation tasks compared to other benchmarks. The CodeScope benchmark and datasets are publicly available at https://github.com/WeixiangYAN/CodeScope.
Hierarchical Regression Network for Spectral Reconstruction from RGB Images
May 10, 2020
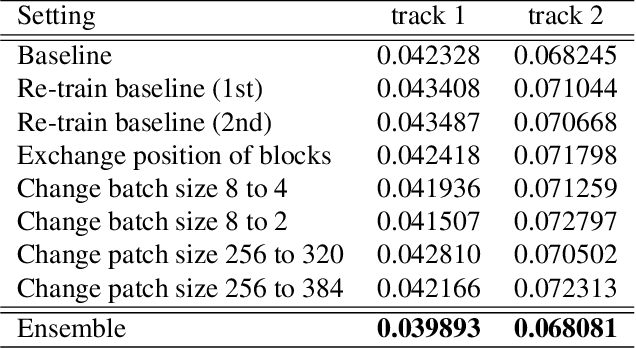
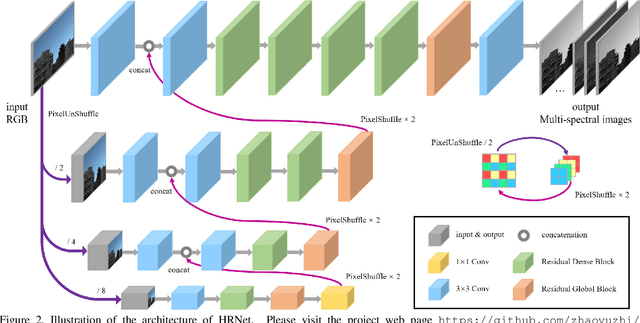
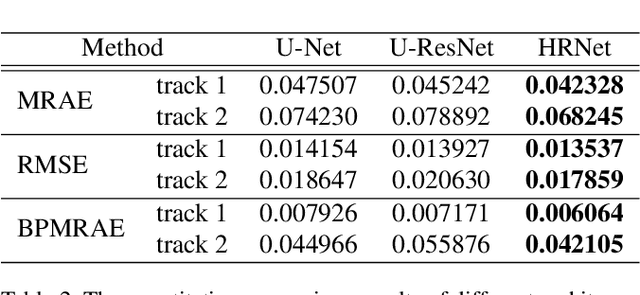
Capturing visual image with a hyperspectral camera has been successfully applied to many areas due to its narrow-band imaging technology. Hyperspectral reconstruction from RGB images denotes a reverse process of hyperspectral imaging by discovering an inverse response function. Current works mainly map RGB images directly to corresponding spectrum but do not consider context information explicitly. Moreover, the use of encoder-decoder pair in current algorithms leads to loss of information. To address these problems, we propose a 4-level Hierarchical Regression Network (HRNet) with PixelShuffle layer as inter-level interaction. Furthermore, we adopt a residual dense block to remove artifacts of real world RGB images and a residual global block to build attention mechanism for enlarging perceptive field. We evaluate proposed HRNet with other architectures and techniques by participating in NTIRE 2020 Challenge on Spectral Reconstruction from RGB Images. The HRNet is the winning method of track 2 - real world images and ranks 3rd on track 1 - clean images. Please visit the project web page https://github.com/zhaoyuzhi/Hierarchical-Regression-Network-for-Spectral-Reconstruction-from-RGB-Images to try our codes and pre-trained models.