 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinicalLab: Aligning Agents for Multi-Departmental Clinical Diagnostics in the Real World
Jun 19, 2024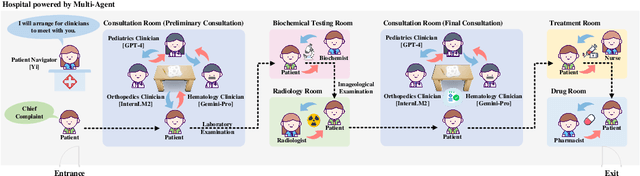

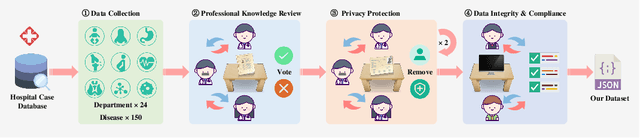
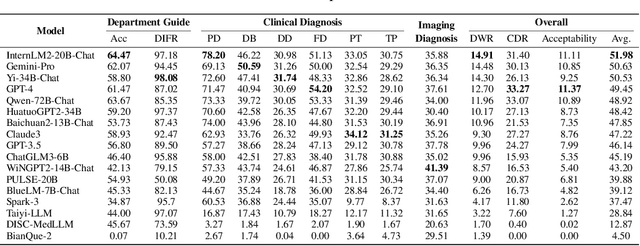
LLMs have achieved significant performance progress in various NLP applications. However, LLMs still struggle to meet the strict requirements for accuracy and reliability in the medical field and face many challenges in clinical applications. Existing clinical diagnostic evaluation benchmarks for evaluating medical agents powered by LLMs have severe limitations. Firstly, most existing medical evaluation benchmarks face the risk of data leakage or contamination. Secondly, existing benchmarks often neglect the characteristics of multiple departments and specializations in modern medical practice. Thirdly, existing evaluation methods are limited to multiple-choice questions, which do not align with the real-world diagnostic scenarios. Lastly, existing evaluation methods lack comprehensive evaluations of end-to-end real clinical scenarios. These limitations in benchmarks in turn obstruct advancements of LLMs and agents for medicine. To address these limitations, we introduce ClinicalLab, a comprehensive clinical diagnosis agent alignment suite. ClinicalLab includes ClinicalBench, an end-to-end multi-departmental clinical diagnostic evaluation benchmark for evaluating medical agents and LLMs. ClinicalBench is based on real cases that cover 24 departments and 150 diseases. ClinicalLab also includes four novel metrics (ClinicalMetrics) for evaluating the effectiveness of LLMs in clinical diagnostic tasks. We evaluate 17 LLMs and find that their performance varies significantly across different departments. Based on these findings, in ClinicalLab, we propose ClinicalAgent, an end-to-end clinical agent that aligns with real-world clinical diagnostic practices. We systematically investigate the performance and applicable scenarios of variants of ClinicalAgent on ClinicalBench. Our findings demonstrate the importance of aligning with modern medical practices in designing medical agents.
CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Nov 14, 2023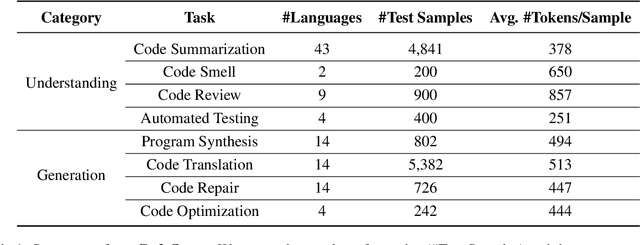
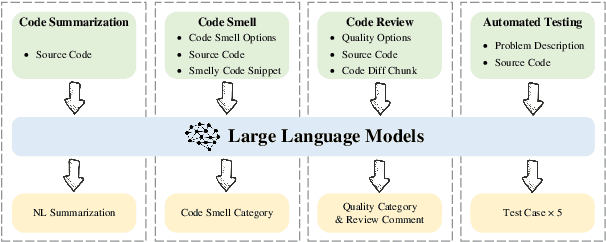

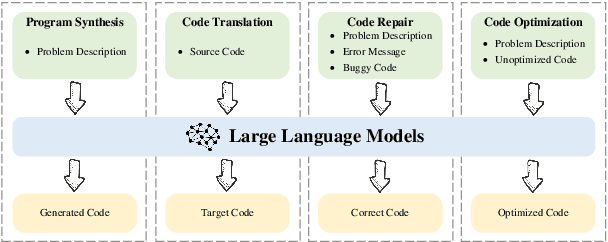
Large Language Models (LLMs) have demonstrated remarkable performance on coding related tasks, particularly on assisting humans in programming and facilitating programming automation. However, existing benchmarks for evaluating the code understanding and generation capacities of LLMs suffer from severe limitations. First, most benchmarks are deficient as they focus on a narrow range of popular programming languages and specific tasks, whereas the real-world software development scenarios show dire need to implement systems with multilingual programming environments to satisfy diverse requirements. Practical programming practices also strongly expect multi-task settings for testing coding capabilities of LLMs comprehensively and robustly. Second, most benchmarks also fail to consider the actual executability and the consistency of execution results of the generated code. To bridge these gaps between existing benchmarks and expectations from practical applications, we introduce CodeScope, an execution-based, multilingual, multi-task, multi-dimensional evaluation benchmark for comprehensively gauging LLM capabilities on coding tasks. CodeScope covers 43 programming languages and 8 coding tasks. It evaluates the coding performance of LLMs from three dimensions (perspectives): difficulty, efficiency, and length. To facilitate execution-based evaluations of code generation, we develop MultiCodeEngine, an automated code execution engine that supports 14 programming languages. Finally, we systematically evaluate and analyze 8 mainstream LLMs on CodeScope tasks and demonstrate the superior breadth and challenges of CodeScope for evaluating LLMs on code understanding and generation tasks compared to other benchmarks. The CodeScope benchmark and datasets are publicly available at https://github.com/WeixiangYAN/CodeScope.