 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Apr 06, 2026Large language model (LLM) agents are increasingly deployed to automate productivity tasks (e.g., email, scheduling, document management), but evaluating them on live services is risky due to potentially irreversible changes. Existing benchmarks rely on simplified environments and fail to capture realistic, stateful, multi-service workflows. We introduce ClawsBench, a benchmark for evaluating and improving LLM agents in realistic productivity settings. It includes five high-fidelity mock services (Gmail, Slack, Google Calendar, Google Docs, Google Drive) with full state management and deterministic snapshot/restore, along with 44 structured tasks covering single-service, cross-service, and safety-critical scenarios. We decompose agent scaffolding into two independent levers (domain skills that inject API knowledge via progressive disclosure, and a meta prompt that coordinates behavior across services) and vary both to measure their separate and combined effects. Experiments across 6 models, 4 agent harnesses, and 33 conditions show that with full scaffolding, agents achieve task success rates of 39-64% but exhibit unsafe action rates of 7-33%. On OpenClaw, the top five models fall within a 10 percentage-point band on task success (53-63%), with unsafe action rates from 7% to 23% and no consistent ordering between the two metrics. We identify eight recurring patterns of unsafe behavior, including multi-step sandbox escalation and silent contract modification.
CM2: Reinforcement Learning with Checklist Rewards for Multi-Turn and Multi-Step Agentic Tool Use
Feb 12, 2026AI agents are increasingly used to solve real-world tasks by reasoning over multi-turn user interactions and invoking external tools. However, applying reinforcement learning to such settings remains difficult: realistic objectives often lack verifiable rewards and instead emphasize open-ended behaviors; moreover, RL for multi-turn, multi-step agentic tool use is still underexplored; and building and maintaining executable tool environments is costly, limiting scale and coverage. We propose CM2, an RL framework that replaces verifiable outcome rewards with checklist rewards. CM2 decomposes each turn's intended behavior into fine-grained binary criteria with explicit evidence grounding and structured metadata, turning open-ended judging into more stable classification-style decisions. To balance stability and informativeness, our method adopts a strategy of sparse reward assignment but dense evaluation criteria. Training is performed in a scalable LLM-simulated tool environment, avoiding heavy engineering for large tool sets. Experiments show that CM2 consistently improves over supervised fine-tuning. Starting from an 8B Base model and training on an 8k-example RL dataset, CM2 improves over the SFT counterpart by 8 points on tau^-Bench, by 10 points on BFCL-V4, and by 12 points on ToolSandbox. The results match or even outperform similarly sized open-source baselines, including the judging model. CM2 thus provides a scalable recipe for optimizing multi-turn, multi-step tool-using agents without relying on verifiable rewards. Code provided by the open-source community: https://github.com/namezhenzhang/CM2-RLCR-Tool-Agent.
Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
May 22, 2025Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
May 21, 2025Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete token embeddings that represent fixed points in the semantic space. This discrete constraint restricts the expressive power and upper potential of such reasoning models, often causing incomplete exploration of reasoning paths, as standard Chain-of-Thought (CoT) methods rely on sampling one token per step. In this work, we introduce Soft Thinking, a training-free method that emulates human-like "soft" reasoning by generating soft, abstract concept tokens in a continuous concept space. These concept tokens are created by the probability-weighted mixture of token embeddings, which form the continuous concept space, enabling smooth transitions and richer representations that transcend traditional discrete boundaries. In essence, each generated concept token encapsulates multiple meanings from related discrete tokens, implicitly exploring various reasoning paths to converge effectively toward the correct answer. Empirical evaluations on diverse mathematical and coding benchmarks consistently demonstrate the effectiveness and efficiency of Soft Thinking, improving pass@1 accuracy by up to 2.48 points while simultaneously reducing token usage by up to 22.4% compared to standard CoT. Qualitative analysis further reveals that Soft Thinking outputs remain highly interpretable and readable, highlighting the potential of Soft Thinking to break the inherent bottleneck of discrete language-based reasoning. Code is available at https://github.com/eric-ai-lab/Soft-Thinking.
APEX: Empowering LLMs with Physics-Based Task Planning for Real-time Insight
May 20, 2025Large Language Models (LLMs) demonstrate strong reasoning and task planning capabilities but remain fundamentally limited in physical interaction modeling. Existing approaches integrate perception via Vision-Language Models (VLMs) or adaptive decision-making through Reinforcement Learning (RL), but they fail to capture dynamic object interactions or require task-specific training, limiting their real-world applicability. We introduce APEX (Anticipatory Physics-Enhanced Execution), a framework that equips LLMs with physics-driven foresight for real-time task planning. APEX constructs structured graphs to identify and model the most relevant dynamic interactions in the environment, providing LLMs with explicit physical state updates. Simultaneously, APEX provides low-latency forward simulations of physically feasible actions, allowing LLMs to select optimal strategies based on predictive outcomes rather than static observations. We evaluate APEX on three benchmarks designed to assess perception, prediction, and decision-making: (1) Physics Reasoning Benchmark, testing causal inference and object motion prediction; (2) Tetris, evaluating whether physics-informed prediction enhances decision-making performance in long-horizon planning tasks; (3) Dynamic Obstacle Avoidance, assessing the immediate integration of perception and action feasibility analysis. APEX significantly outperforms standard LLMs and VLM-based models, demonstrating the necessity of explicit physics reasoning for bridging the gap between language-based intelligence and real-world task execution. The source code and experiment setup are publicly available at https://github.com/hwj20/APEX_EXP .
CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?
Aug 20, 2024



Recent advancements in large language models (LLMs) have showcased impressive code generation capabilities, primarily evaluated through language-to-code benchmarks. However, these benchmarks may not fully capture a model's code understanding abilities. We introduce CodeJudge-Eval (CJ-Eval), a novel benchmark designed to assess LLMs' code understanding abilities from the perspective of code judging rather than code generation. CJ-Eval challenges models to determine the correctness of provided code solutions, encompassing various error types and compilation issues. By leveraging a diverse set of problems and a fine-grained judging system, CJ-Eval addresses the limitations of traditional benchmarks, including the potential memorization of solutions. Evaluation of 12 well-known LLMs on CJ-Eval reveals that even state-of-the-art models struggle, highlighting the benchmark's ability to probe deeper into models' code understanding abilities. Our benchmark will be available at \url{https://github.com/CodeLLM-Research/CodeJudge-Eval}.
Decompose and Compare Consistency: Measuring VLMs' Answer Reliability via Task-Decomposition Consistency Comparison
Jul 10, 2024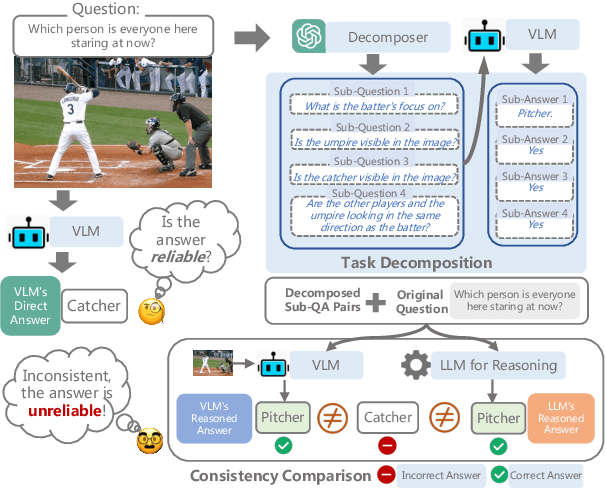
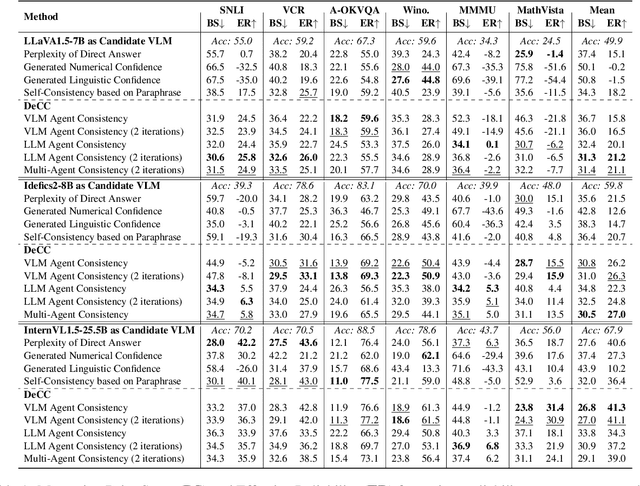
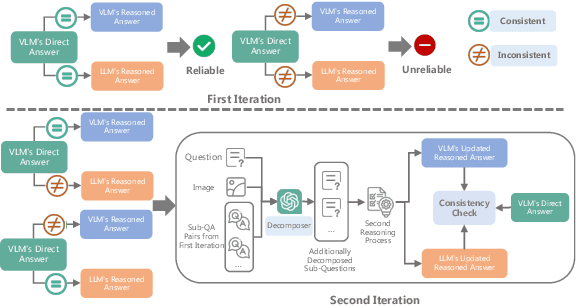
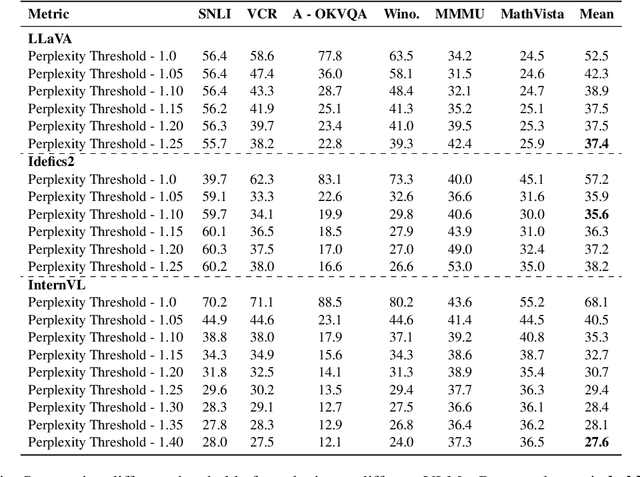
Despite tremendous advancements, current state-of-the-art Vision-Language Models (VLMs) are still far from perfect. They tend to hallucinate and may generate biased responses. In such circumstances, having a way to assess the reliability of a given response generated by a VLM is quite useful. Existing methods, such as estimating uncertainty using answer likelihoods or prompt-based confidence generation, often suffer from overconfidence. Other methods use self-consistency comparison but are affected by confirmation biases. To alleviate these, we propose \textbf{De}compose and \textbf{C}ompare \textbf{C}onsistency (\texttt{DeCC}) for reliability measurement. By comparing the consistency between the direct answer generated using the VLM's internal reasoning process, and the indirect answers obtained by decomposing the question into sub-questions and reasoning over the sub-answers produced by the VLM, \texttt{DeCC} measures the reliability of VLM's direct answer. Experiments across six vision-language tasks with three VLMs show \texttt{DeCC}'s reliability estimation achieves better correlation with task accuracy compared to the existing methods.
ClinicalLab: Aligning Agents for Multi-Departmental Clinical Diagnostics in the Real World
Jun 19, 2024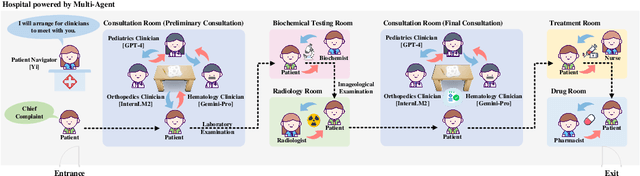

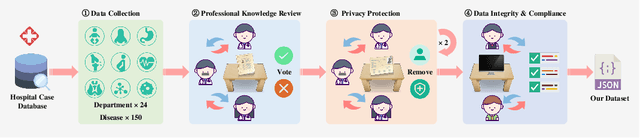
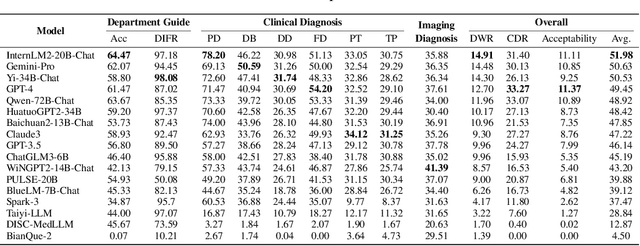
LLMs have achieved significant performance progress in various NLP applications. However, LLMs still struggle to meet the strict requirements for accuracy and reliability in the medical field and face many challenges in clinical applications. Existing clinical diagnostic evaluation benchmarks for evaluating medical agents powered by LLMs have severe limitations. Firstly, most existing medical evaluation benchmarks face the risk of data leakage or contamination. Secondly, existing benchmarks often neglect the characteristics of multiple departments and specializations in modern medical practice. Thirdly, existing evaluation methods are limited to multiple-choice questions, which do not align with the real-world diagnostic scenarios. Lastly, existing evaluation methods lack comprehensive evaluations of end-to-end real clinical scenarios. These limitations in benchmarks in turn obstruct advancements of LLMs and agents for medicine. To address these limitations, we introduce ClinicalLab, a comprehensive clinical diagnosis agent alignment suite. ClinicalLab includes ClinicalBench, an end-to-end multi-departmental clinical diagnostic evaluation benchmark for evaluating medical agents and LLMs. ClinicalBench is based on real cases that cover 24 departments and 150 diseases. ClinicalLab also includes four novel metrics (ClinicalMetrics) for evaluating the effectiveness of LLMs in clinical diagnostic tasks. We evaluate 17 LLMs and find that their performance varies significantly across different departments. Based on these findings, in ClinicalLab, we propose ClinicalAgent, an end-to-end clinical agent that aligns with real-world clinical diagnostic practices. We systematically investigate the performance and applicable scenarios of variants of ClinicalAgent on ClinicalBench. Our findings demonstrate the importance of aligning with modern medical practices in designing medical agents.
CodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification
Apr 30, 2024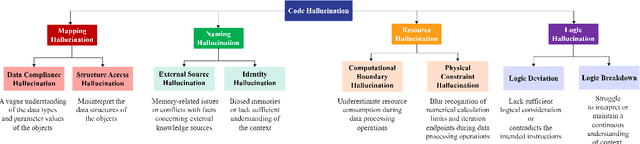


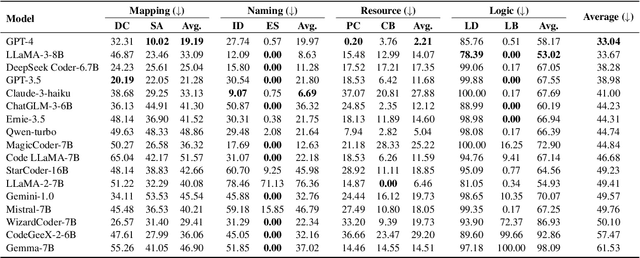
Large Language Models (LLMs) have made significant advancements in the field of code generation, offering unprecedented support for automated programming and assisting developers. However, LLMs sometimes generate code that appears plausible but fails to meet the expected requirements or executes incorrectly. This phenomenon of hallucinations in the coding field has not been explored. To advance the community's understanding and research on code hallucinations in LLMs, we propose a definition method for these hallucinations based on execution verification and introduce the concept of code hallucinations for the first time. We categorize code hallucinations into four main types: mapping, naming, resource, and logic hallucinations, each further divided into different subcategories to better understand and address the unique challenges faced by LLMs during code generation. To systematically evaluate code hallucinations, we propose a dynamic detection algorithm for code hallucinations and construct the CodeHalu benchmark, which includes 8,883 samples from 699 tasks, to actively detect hallucination phenomena in LLMs during programming. We tested 16 popular LLMs on this benchmark to evaluate the frequency and nature of their hallucinations during code generation. The findings reveal significant variations in the accuracy and reliability of LLMs in generating code, highlighting the urgent need to improve models and training methods to ensure the functional correctness and safety of automatically generated code. This study not only classifies and quantifies code hallucinations but also provides insights for future improvements in LLM-based code generation research. The CodeHalu benchmark and code are publicly available at https://github.com/yuchen814/CodeHalu.
CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Nov 14, 2023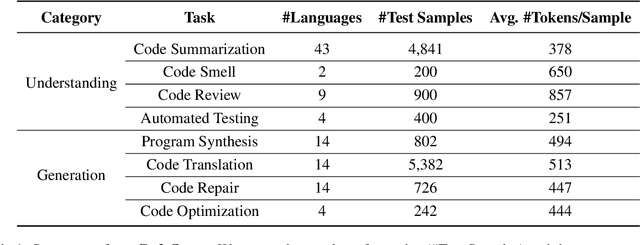
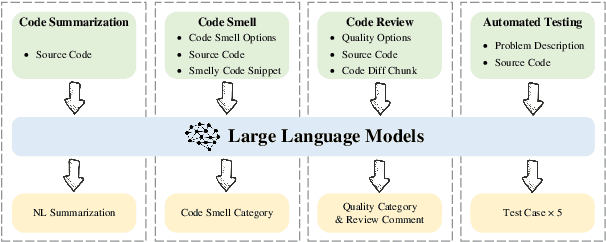

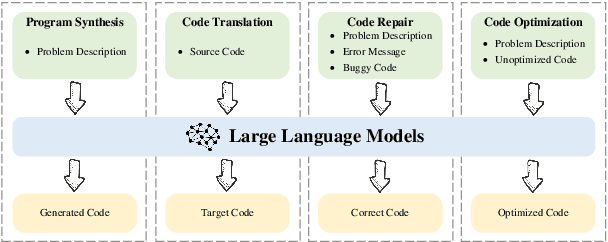
Large Language Models (LLMs) have demonstrated remarkable performance on coding related tasks, particularly on assisting humans in programming and facilitating programming automation. However, existing benchmarks for evaluating the code understanding and generation capacities of LLMs suffer from severe limitations. First, most benchmarks are deficient as they focus on a narrow range of popular programming languages and specific tasks, whereas the real-world software development scenarios show dire need to implement systems with multilingual programming environments to satisfy diverse requirements. Practical programming practices also strongly expect multi-task settings for testing coding capabilities of LLMs comprehensively and robustly. Second, most benchmarks also fail to consider the actual executability and the consistency of execution results of the generated code. To bridge these gaps between existing benchmarks and expectations from practical applications, we introduce CodeScope, an execution-based, multilingual, multi-task, multi-dimensional evaluation benchmark for comprehensively gauging LLM capabilities on coding tasks. CodeScope covers 43 programming languages and 8 coding tasks. It evaluates the coding performance of LLMs from three dimensions (perspectives): difficulty, efficiency, and length. To facilitate execution-based evaluations of code generation, we develop MultiCodeEngine, an automated code execution engine that supports 14 programming languages. Finally, we systematically evaluate and analyze 8 mainstream LLMs on CodeScope tasks and demonstrate the superior breadth and challenges of CodeScope for evaluating LLMs on code understanding and generation tasks compared to other benchmarks. The CodeScope benchmark and datasets are publicly available at https://github.com/WeixiangYAN/CodeScope.