 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification
Paper and Code
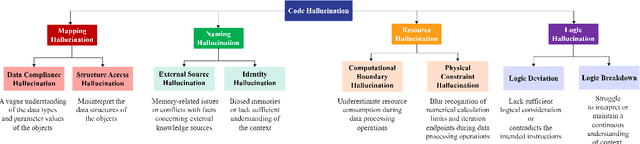


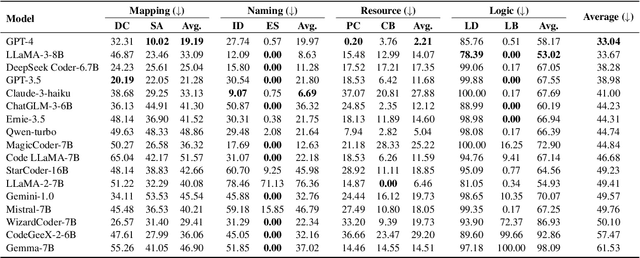
Large Language Models (LLMs) have made significant advancements in the field of code generation, offering unprecedented support for automated programming and assisting developers. However, LLMs sometimes generate code that appears plausible but fails to meet the expected requirements or executes incorrectly. This phenomenon of hallucinations in the coding field has not been explored. To advance the community's understanding and research on code hallucinations in LLMs, we propose a definition method for these hallucinations based on execution verification and introduce the concept of code hallucinations for the first time. We categorize code hallucinations into four main types: mapping, naming, resource, and logic hallucinations, each further divided into different subcategories to better understand and address the unique challenges faced by LLMs during code generation. To systematically evaluate code hallucinations, we propose a dynamic detection algorithm for code hallucinations and construct the CodeHalu benchmark, which includes 8,883 samples from 699 tasks, to actively detect hallucination phenomena in LLMs during programming. We tested 16 popular LLMs on this benchmark to evaluate the frequency and nature of their hallucinations during code generation. The findings reveal significant variations in the accuracy and reliability of LLMs in generating code, highlighting the urgent need to improve models and training methods to ensure the functional correctness and safety of automatically generated code. This study not only classifies and quantifies code hallucinations but also provides insights for future improvements in LLM-based code generation research. The CodeHalu benchmark and code are publicly available at https://github.com/yuchen814/CodeHalu.