 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVEBATCH: Accelerating Model Training Through Gradient-Diversity Aware Batch Size Adaptation
Sep 19, 2025The goal of this paper is to accelerate the training of machine learning models, a critical challenge since the training of large-scale deep neural models can be computationally expensive. Stochastic gradient descent (SGD) and its variants are widely used to train deep neural networks. In contrast to traditional approaches that focus on tuning the learning rate, we propose a novel adaptive batch size SGD algorithm, DiveBatch, that dynamically adjusts the batch size. Adapting the batch size is challenging: using large batch sizes is more efficient due to parallel computation, but small-batch training often converges in fewer epochs and generalizes better. To address this challenge, we introduce a data-driven adaptation based on gradient diversity, enabling DiveBatch to maintain the generalization performance of small-batch training while improving convergence speed and computational efficiency. Gradient diversity has a strong theoretical justification: it emerges from the convergence analysis of SGD. Evaluations of DiveBatch on synthetic and CiFar-10, CiFar-100, and Tiny-ImageNet demonstrate that DiveBatch converges significantly faster than standard SGD and AdaBatch (1.06 -- 5.0x), with a slight trade-off in performance.
Multi-modal Relational Item Representation Learning for Inferring Substitutable and Complementary Items
Jul 29, 2025We introduce a novel self-supervised multi-modal relational item representation learning framework designed to infer substitutable and complementary items. Existing approaches primarily focus on modeling item-item associations deduced from user behaviors using graph neural networks (GNNs) or leveraging item content information. However, these methods often overlook critical challenges, such as noisy user behavior data and data sparsity due to the long-tailed distribution of these behaviors. In this paper, we propose MMSC, a self-supervised multi-modal relational item representation learning framework to address these challenges. Specifically, MMSC consists of three main components: (1) a multi-modal item representation learning module that leverages a multi-modal foundational model and learns from item metadata, (2) a self-supervised behavior-based representation learning module that denoises and learns from user behavior data, and (3) a hierarchical representation aggregation mechanism that integrates item representations at both the semantic and task levels. Additionally, we leverage LLMs to generate augmented training data, further enhancing the denoising process during training. We conduct extensive experiments on five real-world datasets, showing that MMSC outperforms existing baselines by 26.1% for substitutable recommendation and 39.2% for complementary recommendation. In addition, we empirically show that MMSC is effective in modeling cold-start items.
On the Necessity of Output Distribution Reweighting for Effective Class Unlearning
Jun 25, 2025In this work, we introduce an output-reweighting unlearning method, RWFT, a lightweight technique that erases an entire class from a trained classifier without full retraining. Forgetting specific classes from trained models is essential for enforcing user deletion rights and mitigating harmful or biased predictions. The full retraining is costly and existing unlearning methods fail to replicate the behavior of the retrained models when predicting samples from the unlearned class. We prove this failure by designing a variant of membership inference attacks, MIA-NN that successfully reveals the unlearned class for any of these methods. We propose a simple redistribution of the probability mass for the prediction on the samples in the forgotten class which is robust to MIA-NN. We also introduce a new metric based on the total variation (TV) distance of the prediction probabilities to quantify residual leakage to prevent future methods from susceptibility to the new attack. Through extensive experiments with state of the art baselines in machine unlearning, we show that our approach matches the results of full retraining in both metrics used for evaluation by prior work and the new metric we propose in this work. Compare to state-of-the-art methods, we gain 2.79% in previously used metrics and 111.45% in our new TV-based metric over the best existing method.
Breaking Bad Tokens: Detoxification of LLMs Using Sparse Autoencoders
May 20, 2025Large language models (LLMs) are now ubiquitous in user-facing applications, yet they still generate undesirable toxic outputs, including profanity, vulgarity, and derogatory remarks. Although numerous detoxification methods exist, most apply broad, surface-level fixes and can therefore easily be circumvented by jailbreak attacks. In this paper we leverage sparse autoencoders (SAEs) to identify toxicity-related directions in the residual stream of models and perform targeted activation steering using the corresponding decoder vectors. We introduce three tiers of steering aggressiveness and evaluate them on GPT-2 Small and Gemma-2-2B, revealing trade-offs between toxicity reduction and language fluency. At stronger steering strengths, these causal interventions surpass competitive baselines in reducing toxicity by up to 20%, though fluency can degrade noticeably on GPT-2 Small depending on the aggressiveness. Crucially, standard NLP benchmark scores upon steering remain stable, indicating that the model's knowledge and general abilities are preserved. We further show that feature-splitting in wider SAEs hampers safety interventions, underscoring the importance of disentangled feature learning. Our findings highlight both the promise and the current limitations of SAE-based causal interventions for LLM detoxification, further suggesting practical guidelines for safer language-model deployment.
Algorithmic Collective Action with Two Collectives
Apr 30, 2025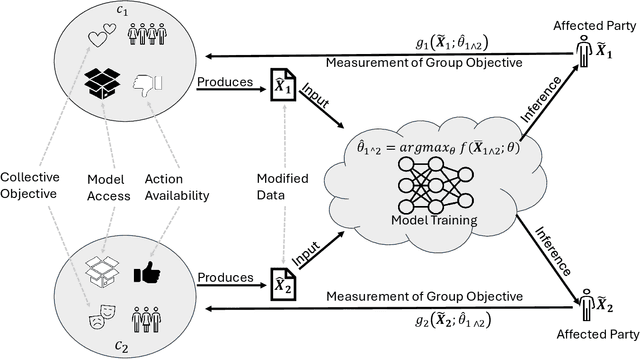
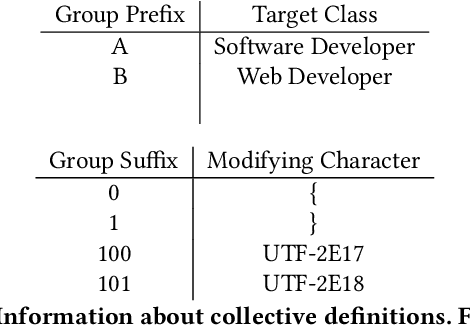
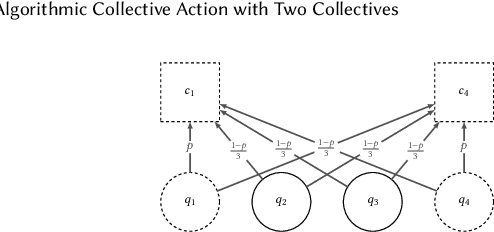
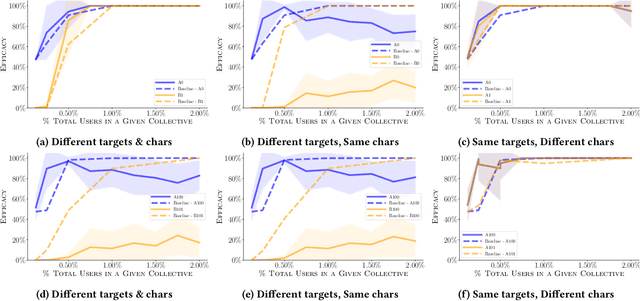
Given that data-dependent algorithmic systems have become impactful in more domains of life, the need for individuals to promote their own interests and hold algorithms accountable has grown. To have meaningful influence, individuals must band together to engage in collective action. Groups that engage in such algorithmic collective action are likely to vary in size, membership characteristics, and crucially, objectives. In this work, we introduce a first of a kind framework for studying collective action with two or more collectives that strategically behave to manipulate data-driven systems. With more than one collective acting on a system, unexpected interactions may occur. We use this framework to conduct experiments with language model-based classifiers and recommender systems where two collectives each attempt to achieve their own individual objectives. We examine how differing objectives, strategies, sizes, and homogeneity can impact a collective's efficacy. We find that the unintentional interactions between collectives can be quite significant; a collective acting in isolation may be able to achieve their objective (e.g., improve classification outcomes for themselves or promote a particular item), but when a second collective acts simultaneously, the efficacy of the first group drops by as much as $75\%$. We find that, in the recommender system context, neither fully heterogeneous nor fully homogeneous collectives stand out as most efficacious and that heterogeneity's impact is secondary compared to collective size. Our results signal the need for more transparency in both the underlying algorithmic models and the different behaviors individuals or collectives may take on these systems. This approach also allows collectives to hold algorithmic system developers accountable and provides a framework for people to actively use their own data to promote their own interests.
AMUN: Adversarial Machine UNlearning
Mar 02, 2025



Machine unlearning, where users can request the deletion of a forget dataset, is becoming increasingly important because of numerous privacy regulations. Initial works on ``exact'' unlearning (e.g., retraining) incur large computational overheads. However, while computationally inexpensive, ``approximate'' methods have fallen short of reaching the effectiveness of exact unlearning: models produced fail to obtain comparable accuracy and prediction confidence on both the forget and test (i.e., unseen) dataset. Exploiting this observation, we propose a new unlearning method, Adversarial Machine UNlearning (AMUN), that outperforms prior state-of-the-art (SOTA) methods for image classification. AMUN lowers the confidence of the model on the forget samples by fine-tuning the model on their corresponding adversarial examples. Adversarial examples naturally belong to the distribution imposed by the model on the input space; fine-tuning the model on the adversarial examples closest to the corresponding forget samples (a) localizes the changes to the decision boundary of the model around each forget sample and (b) avoids drastic changes to the global behavior of the model, thereby preserving the model's accuracy on test samples. Using AMUN for unlearning a random $10\%$ of CIFAR-10 samples, we observe that even SOTA membership inference attacks cannot do better than random guessing.
A Zero-Shot Generalization Framework for LLM-Driven Cross-Domain Sequential Recommendation
Jan 31, 2025



Zero-shot cross-domain sequential recommendation (ZCDSR) enables predictions in unseen domains without the need for additional training or fine-tuning, making it particularly valuable in data-sparse environments where traditional models struggle. Recent advancements in large language models (LLMs) have greatly improved ZCDSR by leveraging rich pretrained representations to facilitate cross-domain knowledge transfer. However, a key challenge persists: domain semantic bias, which arises from variations in vocabulary and content focus across domains. This misalignment leads to inconsistencies in item embeddings and hinders generalization. To address this issue, we propose a novel framework designed to enhance LLM-based ZCDSR by improving cross-domain alignment at both the item and sequential levels. At the item level, we introduce a generalization loss that promotes inter-domain compactness by aligning embeddings of similar items across domains while maintaining intra-domain diversity to preserve unique item characteristics. This prevents embeddings from becoming overly generic while ensuring effective transferability. At the sequential level, we develop a method for transferring user behavioral patterns by clustering user sequences in the source domain and applying attention-based aggregation for target domain inference. This dynamic adaptation of user embeddings allows effective zero-shot recommendations without requiring target-domain interactions. Comprehensive experiments across multiple datasets and domains demonstrate that our framework significantly improves sequential recommendation performance in the ZCDSR setting. By mitigating domain bias and enhancing the transferability of sequential patterns, our method provides a scalable and robust approach for achieving more effective zero-shot recommendations across domains.
Venire: A Machine Learning-Guided Panel Review System for Community Content Moderation
Oct 30, 2024Research into community content moderation often assumes that moderation teams govern with a single, unified voice. However, recent work has found that moderators disagree with one another at modest, but concerning rates. The problem is not the root disagreements themselves. Subjectivity in moderation is unavoidable, and there are clear benefits to including diverse perspectives within a moderation team. Instead, the crux of the issue is that, due to resource constraints, moderation decisions end up being made by individual decision-makers. The result is decision-making that is inconsistent, which is frustrating for community members. To address this, we develop Venire, an ML-backed system for panel review on Reddit. Venire uses a machine learning model trained on log data to identify the cases where moderators are most likely to disagree. Venire fast-tracks these cases for multi-person review. Ideally, Venire allows moderators to surface and resolve disagreements that would have otherwise gone unnoticed. We conduct three studies through which we design and evaluate Venire: a set of formative interviews with moderators, technical evaluations on two datasets, and a think-aloud study in which moderators used Venire to make decisions on real moderation cases. Quantitatively, we demonstrate that Venire is able to improve decision consistency and surface latent disagreements. Qualitatively, we find that Venire helps moderators resolve difficult moderation cases more confidently. Venire represents a novel paradigm for human-AI content moderation, and shifts the conversation from replacing human decision-making to supporting it.
LOTOS: Layer-wise Orthogonalization for Training Robust Ensembles
Oct 07, 2024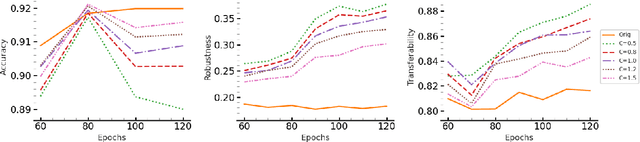

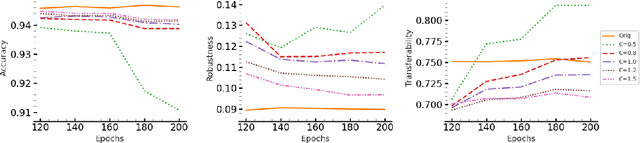

Transferability of adversarial examples is a well-known property that endangers all classification models, even those that are only accessible through black-box queries. Prior work has shown that an ensemble of models is more resilient to transferability: the probability that an adversarial example is effective against most models of the ensemble is low. Thus, most ongoing research focuses on improving ensemble diversity. Another line of prior work has shown that Lipschitz continuity of the models can make models more robust since it limits how a model's output changes with small input perturbations. In this paper, we study the effect of Lipschitz continuity on transferability rates. We show that although a lower Lipschitz constant increases the robustness of a single model, it is not as beneficial in training robust ensembles as it increases the transferability rate of adversarial examples across models in the ensemble. Therefore, we introduce LOTOS, a new training paradigm for ensembles, which counteracts this adverse effect. It does so by promoting orthogonality among the top-$k$ sub-spaces of the transformations of the corresponding affine layers of any pair of models in the ensemble. We theoretically show that $k$ does not need to be large for convolutional layers, which makes the computational overhead negligible. Through various experiments, we show LOTOS increases the robust accuracy of ensembles of ResNet-18 models by $6$ percentage points (p.p) against black-box attacks on CIFAR-10. It is also capable of combining with the robustness of prior state-of-the-art methods for training robust ensembles to enhance their robust accuracy by $10.7$ p.p.
Spectrum Extraction and Clipping for Implicitly Linear Layers
Feb 25, 2024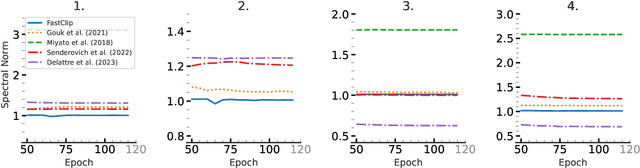
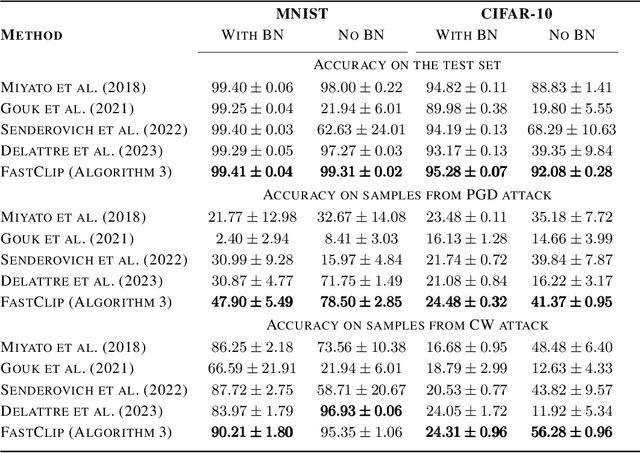
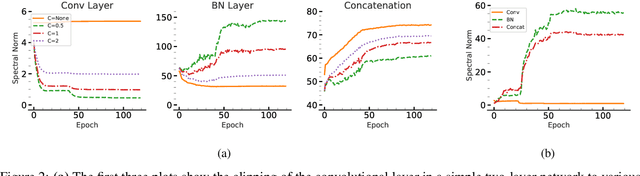
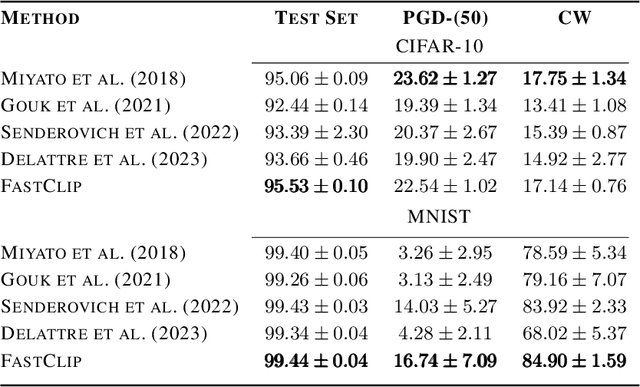
We show the effectiveness of automatic differentiation in efficiently and correctly computing and controlling the spectrum of implicitly linear operators, a rich family of layer types including all standard convolutional and dense layers. We provide the first clipping method which is correct for general convolution layers, and illuminate the representational limitation that caused correctness issues in prior work. We study the effect of the batch normalization layers when concatenated with convolutional layers and show how our clipping method can be applied to their composition. By comparing the accuracy and performance of our algorithms to the state-of-the-art methods, using various experiments, we show they are more precise and efficient and lead to better generalization and adversarial robustness. We provide the code for using our methods at https://github.com/Ali-E/FastClip.