 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Collective Action with Two Collectives
Apr 30, 2025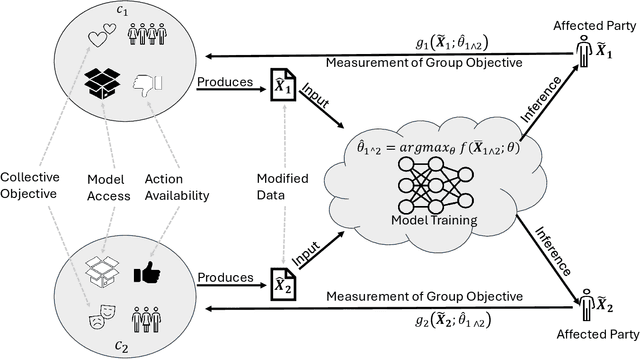
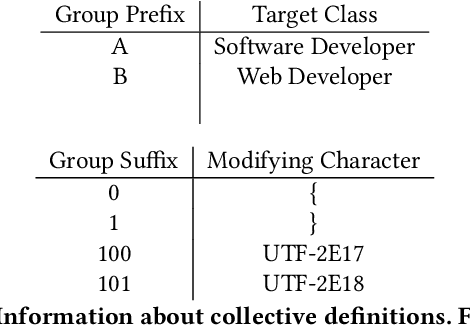
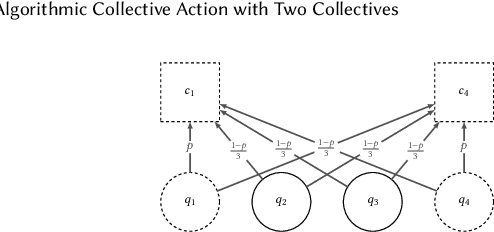
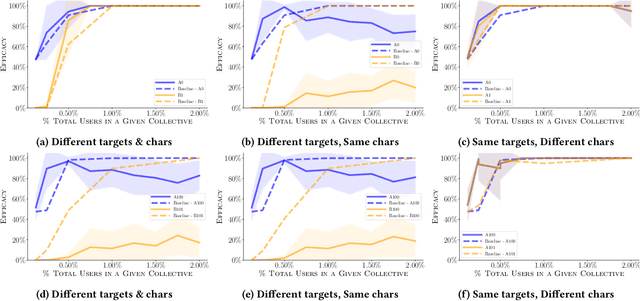
Given that data-dependent algorithmic systems have become impactful in more domains of life, the need for individuals to promote their own interests and hold algorithms accountable has grown. To have meaningful influence, individuals must band together to engage in collective action. Groups that engage in such algorithmic collective action are likely to vary in size, membership characteristics, and crucially, objectives. In this work, we introduce a first of a kind framework for studying collective action with two or more collectives that strategically behave to manipulate data-driven systems. With more than one collective acting on a system, unexpected interactions may occur. We use this framework to conduct experiments with language model-based classifiers and recommender systems where two collectives each attempt to achieve their own individual objectives. We examine how differing objectives, strategies, sizes, and homogeneity can impact a collective's efficacy. We find that the unintentional interactions between collectives can be quite significant; a collective acting in isolation may be able to achieve their objective (e.g., improve classification outcomes for themselves or promote a particular item), but when a second collective acts simultaneously, the efficacy of the first group drops by as much as $75\%$. We find that, in the recommender system context, neither fully heterogeneous nor fully homogeneous collectives stand out as most efficacious and that heterogeneity's impact is secondary compared to collective size. Our results signal the need for more transparency in both the underlying algorithmic models and the different behaviors individuals or collectives may take on these systems. This approach also allows collectives to hold algorithmic system developers accountable and provides a framework for people to actively use their own data to promote their own interests.
Venire: A Machine Learning-Guided Panel Review System for Community Content Moderation
Oct 30, 2024Research into community content moderation often assumes that moderation teams govern with a single, unified voice. However, recent work has found that moderators disagree with one another at modest, but concerning rates. The problem is not the root disagreements themselves. Subjectivity in moderation is unavoidable, and there are clear benefits to including diverse perspectives within a moderation team. Instead, the crux of the issue is that, due to resource constraints, moderation decisions end up being made by individual decision-makers. The result is decision-making that is inconsistent, which is frustrating for community members. To address this, we develop Venire, an ML-backed system for panel review on Reddit. Venire uses a machine learning model trained on log data to identify the cases where moderators are most likely to disagree. Venire fast-tracks these cases for multi-person review. Ideally, Venire allows moderators to surface and resolve disagreements that would have otherwise gone unnoticed. We conduct three studies through which we design and evaluate Venire: a set of formative interviews with moderators, technical evaluations on two datasets, and a think-aloud study in which moderators used Venire to make decisions on real moderation cases. Quantitatively, we demonstrate that Venire is able to improve decision consistency and surface latent disagreements. Qualitatively, we find that Venire helps moderators resolve difficult moderation cases more confidently. Venire represents a novel paradigm for human-AI content moderation, and shifts the conversation from replacing human decision-making to supporting it.
Enhancing Child Vocalization Classification in Multi-Channel Child-Adult Conversations Through Wav2vec2 Children ASR Features
Sep 13, 2023
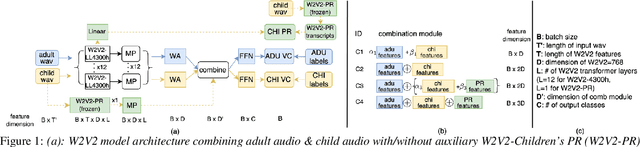

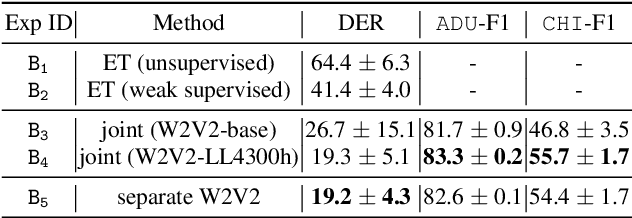
Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder that often emerges in early childhood. ASD assessment typically involves an observation protocol including note-taking and ratings of child's social behavior conducted by a trained clinician. A robust machine learning (ML) model that is capable of labeling adult and child audio has the potential to save significant time and labor in manual coding children's behaviors. This may assist clinicians capture events of interest, better communicate events with parents, and educate new clinicians. In this study, we leverage the self-supervised learning model, Wav2Vec 2.0 (W2V2), pretrained on 4300h of home recordings of children under 5 years old, to build a unified system that performs both speaker diarization (SD) and vocalization classification (VC) tasks. We apply this system to two-channel audio recordings of brief 3-5 minute clinician-child interactions using the Rapid-ABC corpus. We propose a novel technique by introducing auxiliary features extracted from W2V2-based automatic speech recognition (ASR) system for children under 4 years old to improve children's VC task. We test our proposed method of improving children's VC task on two corpora (Rapid-ABC and BabbleCor) and observe consistent improvements. Furthermore, we reach, or perhaps outperform, the state-of-the-art performance of BabbleCor.
Inform the uninformed: Improving Online Informed Consent Reading with an AI-Powered Chatbot
Feb 02, 2023



Informed consent is a core cornerstone of ethics in human subject research. Through the informed consent process, participants learn about the study procedure, benefits, risks, and more to make an informed decision. However, recent studies showed that current practices might lead to uninformed decisions and expose participants to unknown risks, especially in online studies. Without the researcher's presence and guidance, online participants must read a lengthy form on their own with no answers to their questions. In this paper, we examined the role of an AI-powered chatbot in improving informed consent online. By comparing the chatbot with form-based interaction, we found the chatbot improved consent form reading, promoted participants' feelings of agency, and closed the power gap between the participant and the researcher. Our exploratory analysis further revealed the altered power dynamic might eventually benefit study response quality. We discussed design implications for creating AI-powered chatbots to offer effective informed consent in broader settings.
What should I Ask: A Knowledge-driven Approach for Follow-up Questions Generation in Conversational Surveys
May 23, 2022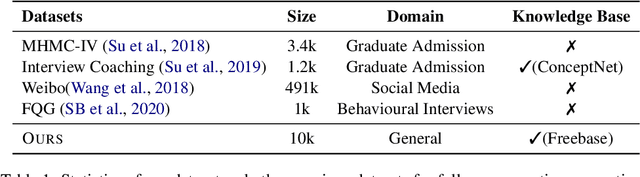
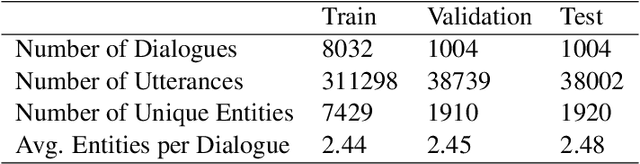
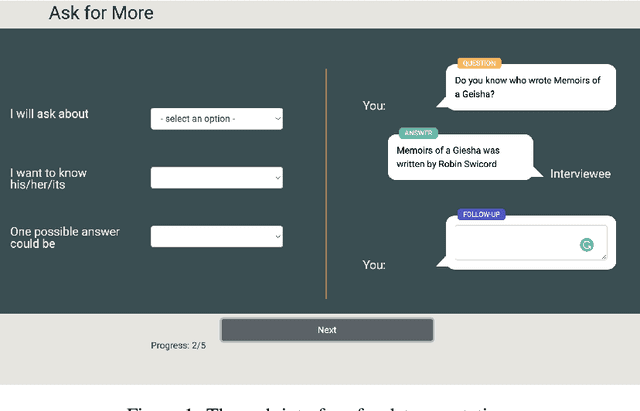
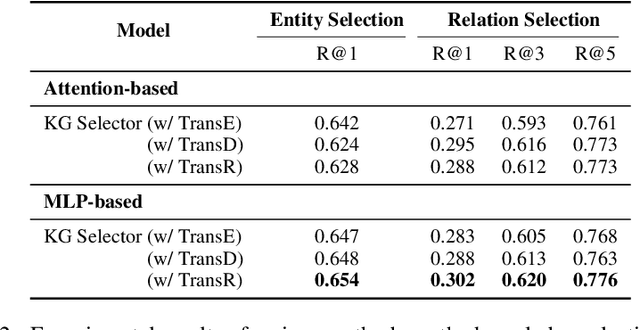
Conversational surveys, where an agent asks open-ended questions through natural language interfaces, offer a new way to collect information from people. A good follow-up question in a conversational survey prompts high-quality information and delivers engaging experiences. However, generating high-quality follow-up questions on the fly is a non-trivial task. The agent needs to understand the diverse and complex participant responses, adhere to the survey goal, and generate clear and coherent questions. In this study, we propose a knowledge-driven follow-up question generation framework. The framework combines a knowledge selection module to identify salient topics in participants' responses and a generative model guided by selected knowledge entity-relation pairs. To investigate the effectiveness of the proposed framework, we build a new dataset for open-domain follow-up question generation and present a new set of reference-free evaluation metrics based on Gricean Maxim. Our experiments demonstrate that our framework outperforms a GPT-based baseline in both objective evaluation and human-expert evaluation.