 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Child Vocalization Classification in Multi-Channel Child-Adult Conversations Through Wav2vec2 Children ASR Features
Paper and Code
Sep 13, 2023
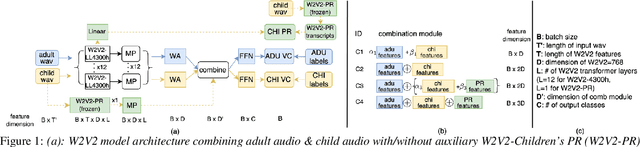

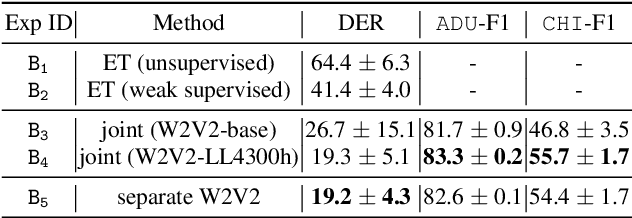
Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder that often emerges in early childhood. ASD assessment typically involves an observation protocol including note-taking and ratings of child's social behavior conducted by a trained clinician. A robust machine learning (ML) model that is capable of labeling adult and child audio has the potential to save significant time and labor in manual coding children's behaviors. This may assist clinicians capture events of interest, better communicate events with parents, and educate new clinicians. In this study, we leverage the self-supervised learning model, Wav2Vec 2.0 (W2V2), pretrained on 4300h of home recordings of children under 5 years old, to build a unified system that performs both speaker diarization (SD) and vocalization classification (VC) tasks. We apply this system to two-channel audio recordings of brief 3-5 minute clinician-child interactions using the Rapid-ABC corpus. We propose a novel technique by introducing auxiliary features extracted from W2V2-based automatic speech recognition (ASR) system for children under 4 years old to improve children's VC task. We test our proposed method of improving children's VC task on two corpora (Rapid-ABC and BabbleCor) and observe consistent improvements. Furthermore, we reach, or perhaps outperform, the state-of-the-art performance of BabbleCor.