 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Necessity of Output Distribution Reweighting for Effective Class Unlearning
Jun 25, 2025In this work, we introduce an output-reweighting unlearning method, RWFT, a lightweight technique that erases an entire class from a trained classifier without full retraining. Forgetting specific classes from trained models is essential for enforcing user deletion rights and mitigating harmful or biased predictions. The full retraining is costly and existing unlearning methods fail to replicate the behavior of the retrained models when predicting samples from the unlearned class. We prove this failure by designing a variant of membership inference attacks, MIA-NN that successfully reveals the unlearned class for any of these methods. We propose a simple redistribution of the probability mass for the prediction on the samples in the forgotten class which is robust to MIA-NN. We also introduce a new metric based on the total variation (TV) distance of the prediction probabilities to quantify residual leakage to prevent future methods from susceptibility to the new attack. Through extensive experiments with state of the art baselines in machine unlearning, we show that our approach matches the results of full retraining in both metrics used for evaluation by prior work and the new metric we propose in this work. Compare to state-of-the-art methods, we gain 2.79% in previously used metrics and 111.45% in our new TV-based metric over the best existing method.
AMUN: Adversarial Machine UNlearning
Mar 02, 2025



Machine unlearning, where users can request the deletion of a forget dataset, is becoming increasingly important because of numerous privacy regulations. Initial works on ``exact'' unlearning (e.g., retraining) incur large computational overheads. However, while computationally inexpensive, ``approximate'' methods have fallen short of reaching the effectiveness of exact unlearning: models produced fail to obtain comparable accuracy and prediction confidence on both the forget and test (i.e., unseen) dataset. Exploiting this observation, we propose a new unlearning method, Adversarial Machine UNlearning (AMUN), that outperforms prior state-of-the-art (SOTA) methods for image classification. AMUN lowers the confidence of the model on the forget samples by fine-tuning the model on their corresponding adversarial examples. Adversarial examples naturally belong to the distribution imposed by the model on the input space; fine-tuning the model on the adversarial examples closest to the corresponding forget samples (a) localizes the changes to the decision boundary of the model around each forget sample and (b) avoids drastic changes to the global behavior of the model, thereby preserving the model's accuracy on test samples. Using AMUN for unlearning a random $10\%$ of CIFAR-10 samples, we observe that even SOTA membership inference attacks cannot do better than random guessing.
LOTOS: Layer-wise Orthogonalization for Training Robust Ensembles
Oct 07, 2024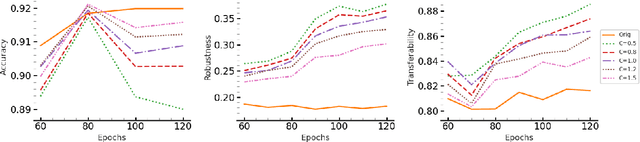

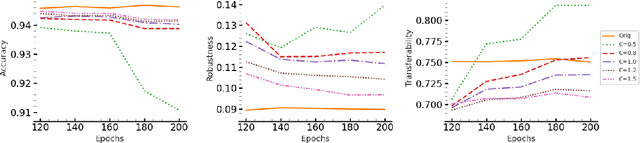

Transferability of adversarial examples is a well-known property that endangers all classification models, even those that are only accessible through black-box queries. Prior work has shown that an ensemble of models is more resilient to transferability: the probability that an adversarial example is effective against most models of the ensemble is low. Thus, most ongoing research focuses on improving ensemble diversity. Another line of prior work has shown that Lipschitz continuity of the models can make models more robust since it limits how a model's output changes with small input perturbations. In this paper, we study the effect of Lipschitz continuity on transferability rates. We show that although a lower Lipschitz constant increases the robustness of a single model, it is not as beneficial in training robust ensembles as it increases the transferability rate of adversarial examples across models in the ensemble. Therefore, we introduce LOTOS, a new training paradigm for ensembles, which counteracts this adverse effect. It does so by promoting orthogonality among the top-$k$ sub-spaces of the transformations of the corresponding affine layers of any pair of models in the ensemble. We theoretically show that $k$ does not need to be large for convolutional layers, which makes the computational overhead negligible. Through various experiments, we show LOTOS increases the robust accuracy of ensembles of ResNet-18 models by $6$ percentage points (p.p) against black-box attacks on CIFAR-10. It is also capable of combining with the robustness of prior state-of-the-art methods for training robust ensembles to enhance their robust accuracy by $10.7$ p.p.