 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?
Aug 20, 2024



Recent advancements in large language models (LLMs) have showcased impressive code generation capabilities, primarily evaluated through language-to-code benchmarks. However, these benchmarks may not fully capture a model's code understanding abilities. We introduce CodeJudge-Eval (CJ-Eval), a novel benchmark designed to assess LLMs' code understanding abilities from the perspective of code judging rather than code generation. CJ-Eval challenges models to determine the correctness of provided code solutions, encompassing various error types and compilation issues. By leveraging a diverse set of problems and a fine-grained judging system, CJ-Eval addresses the limitations of traditional benchmarks, including the potential memorization of solutions. Evaluation of 12 well-known LLMs on CJ-Eval reveals that even state-of-the-art models struggle, highlighting the benchmark's ability to probe deeper into models' code understanding abilities. Our benchmark will be available at \url{https://github.com/CodeLLM-Research/CodeJudge-Eval}.
GLGait: A Global-Local Temporal Receptive Field Network for Gait Recognition in the Wild
Aug 13, 2024



Gait recognition has attracted increasing attention from academia and industry as a human recognition technology from a distance in non-intrusive ways without requiring cooperation. Although advanced methods have achieved impressive success in lab scenarios, most of them perform poorly in the wild. Recently, some Convolution Neural Networks (ConvNets) based methods have been proposed to address the issue of gait recognition in the wild. However, the temporal receptive field obtained by convolution operations is limited for long gait sequences. If directly replacing convolution blocks with visual transformer blocks, the model may not enhance a local temporal receptive field, which is important for covering a complete gait cycle. To address this issue, we design a Global-Local Temporal Receptive Field Network (GLGait). GLGait employs a Global-Local Temporal Module (GLTM) to establish a global-local temporal receptive field, which mainly consists of a Pseudo Global Temporal Self-Attention (PGTA) and a temporal convolution operation. Specifically, PGTA is used to obtain a pseudo global temporal receptive field with less memory and computation complexity compared with a multi-head self-attention (MHSA). The temporal convolution operation is used to enhance the local temporal receptive field. Besides, it can also aggregate pseudo global temporal receptive field to a true holistic temporal receptive field. Furthermore, we also propose a Center-Augmented Triplet Loss (CTL) in GLGait to reduce the intra-class distance and expand the positive samples in the training stage. Extensive experiments show that our method obtains state-of-the-art results on in-the-wild datasets, $i.e.$, Gait3D and GREW. The code is available at https://github.com/bgdpgz/GLGait.
Exploring home robot capabilities by medium fidelity prototyping
Oct 09, 2017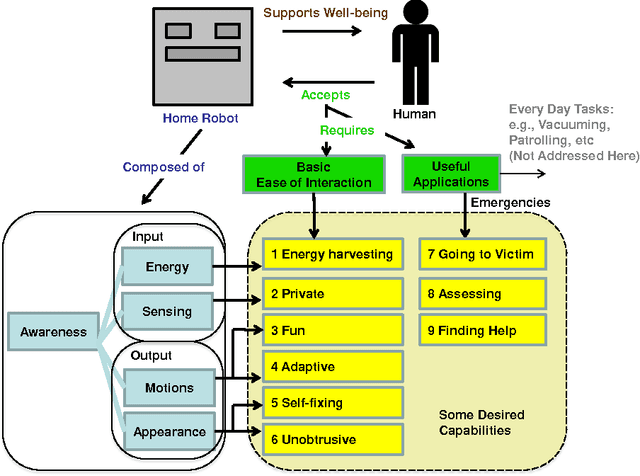
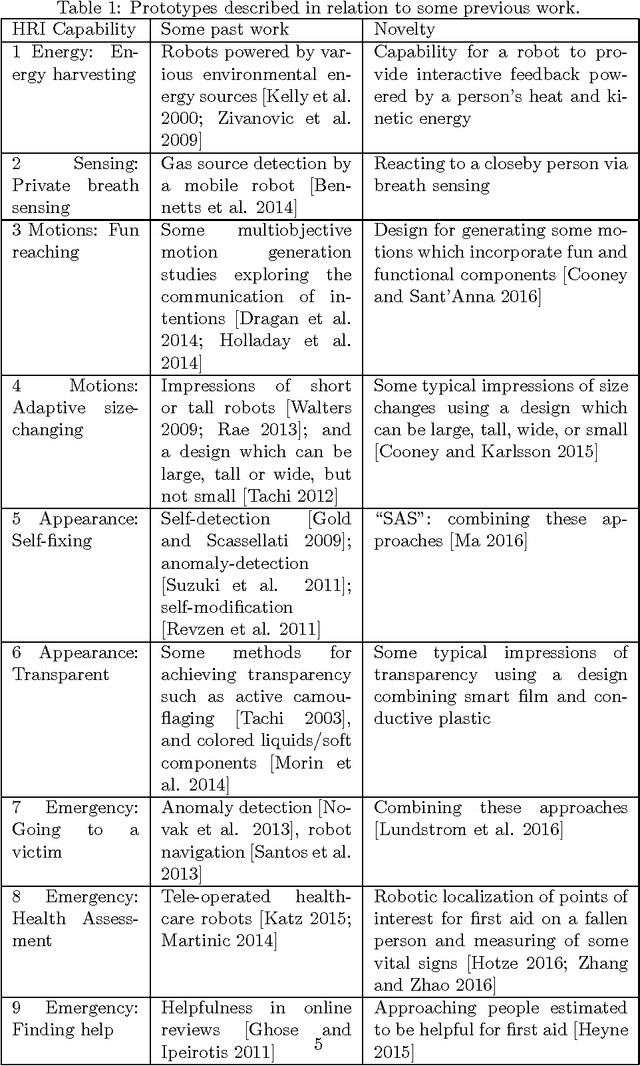
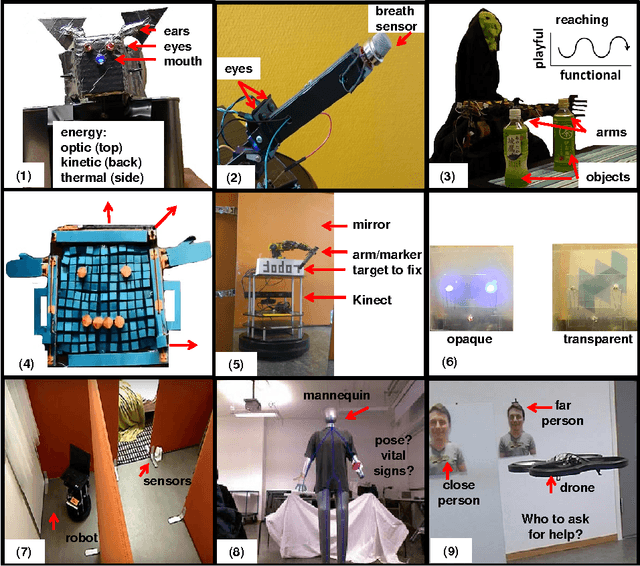

In order for autonomous robots to be able to support people's well-being in homes and everyday environments, new interactive capabilities will be required, as exemplified by the soft design used for Disney's recent robot character Baymax in popular fiction. Home robots will be required to be easy to interact with and intelligent--adaptive, fun, unobtrusive and involving little effort to power and maintain--and capable of carrying out useful tasks both on an everyday level and during emergencies. The current article adopts an exploratory medium fidelity prototyping approach for testing some new robotic capabilities in regard to recognizing people's activities and intentions and behaving in a way which is transparent to people. Results are discussed with the aim of informing next designs.