 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadGS-Reg: Registering Spine CT with Biplanar X-rays via Joint 3D Radiative Gaussians Reconstruction and 3D/3D Registration
Aug 28, 2025Computed Tomography (CT)/X-ray registration in image-guided navigation remains challenging because of its stringent requirements for high accuracy and real-time performance. Traditional "render and compare" methods, relying on iterative projection and comparison, suffer from spatial information loss and domain gap. 3D reconstruction from biplanar X-rays supplements spatial and shape information for 2D/3D registration, but current methods are limited by dense-view requirements and struggles with noisy X-rays. To address these limitations, we introduce RadGS-Reg, a novel framework for vertebral-level CT/X-ray registration through joint 3D Radiative Gaussians (RadGS) reconstruction and 3D/3D registration. Specifically, our biplanar X-rays vertebral RadGS reconstruction module explores learning-based RadGS reconstruction method with a Counterfactual Attention Learning (CAL) mechanism, focusing on vertebral regions in noisy X-rays. Additionally, a patient-specific pre-training strategy progressively adapts the RadGS-Reg from simulated to real data while simultaneously learning vertebral shape prior knowledge. Experiments on in-house datasets demonstrate the state-of-the-art performance for both tasks, surpassing existing methods. The code is available at: https://github.com/shenao1995/RadGS_Reg.
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
May 21, 2025Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete token embeddings that represent fixed points in the semantic space. This discrete constraint restricts the expressive power and upper potential of such reasoning models, often causing incomplete exploration of reasoning paths, as standard Chain-of-Thought (CoT) methods rely on sampling one token per step. In this work, we introduce Soft Thinking, a training-free method that emulates human-like "soft" reasoning by generating soft, abstract concept tokens in a continuous concept space. These concept tokens are created by the probability-weighted mixture of token embeddings, which form the continuous concept space, enabling smooth transitions and richer representations that transcend traditional discrete boundaries. In essence, each generated concept token encapsulates multiple meanings from related discrete tokens, implicitly exploring various reasoning paths to converge effectively toward the correct answer. Empirical evaluations on diverse mathematical and coding benchmarks consistently demonstrate the effectiveness and efficiency of Soft Thinking, improving pass@1 accuracy by up to 2.48 points while simultaneously reducing token usage by up to 22.4% compared to standard CoT. Qualitative analysis further reveals that Soft Thinking outputs remain highly interpretable and readable, highlighting the potential of Soft Thinking to break the inherent bottleneck of discrete language-based reasoning. Code is available at https://github.com/eric-ai-lab/Soft-Thinking.
Pay More Attention to the Robustness of Prompt for Instruction Data Mining
Mar 31, 2025Instruction tuning has emerged as a paramount method for tailoring the behaviors of LLMs. Recent work has unveiled the potential for LLMs to achieve high performance through fine-tuning with a limited quantity of high-quality instruction data. Building upon this approach, we further explore the impact of prompt's robustness on the selection of high-quality instruction data. This paper proposes a pioneering framework of high-quality online instruction data mining for instruction tuning, focusing on the impact of prompt's robustness on the data mining process. Our notable innovation, is to generate the adversarial instruction data by conducting the attack for the prompt of online instruction data. Then, we introduce an Adversarial Instruction-Following Difficulty metric to measure how much help the adversarial instruction data can provide to the generation of the corresponding response. Apart from it, we propose a novel Adversarial Instruction Output Embedding Consistency approach to select high-quality online instruction data. We conduct extensive experiments on two benchmark datasets to assess the performance. The experimental results serve to underscore the effectiveness of our proposed two methods. Moreover, the results underscore the critical practical significance of considering prompt's robustness.
FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving
Nov 27, 2024



Serving numerous users and requests concurrently requires good fairness in Large Language Models (LLMs) serving system. This ensures that, at the same cost, the system can meet the Service Level Objectives (SLOs) of more users , such as time to first token (TTFT) and time between tokens (TBT), rather than allowing a few users to experience performance far exceeding the SLOs. To achieve better fairness, the preemption-based scheduling policy dynamically adjusts the priority of each request to maintain balance during runtime. However, existing systems tend to overly prioritize throughput, overlooking the overhead caused by preemption-induced context switching, which is crucial for maintaining fairness through priority adjustments. In this work, we identify three main challenges that result in this overhead. 1) Inadequate I/O utilization. 2) GPU idleness. 3) Unnecessary I/O transmission during multi-turn conversations. Our key insight is that the block-based KV cache memory policy in existing systems, while achieving near-zero memory waste, leads to discontinuity and insufficient granularity in the KV cache memory. To respond, we introduce FastSwitch, a fairness-aware serving system that not only aligns with existing KV cache memory allocation policy but also mitigates context switching overhead. Our evaluation shows that FastSwitch outperforms the state-of-the-art LLM serving system vLLM with speedups of 1.4-11.2x across different tail TTFT and TBT.
Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance
Jul 24, 2024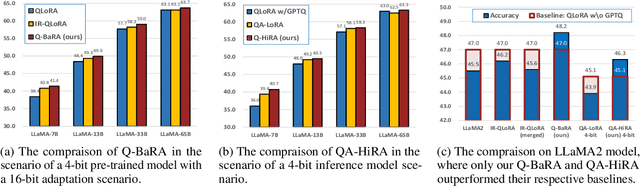
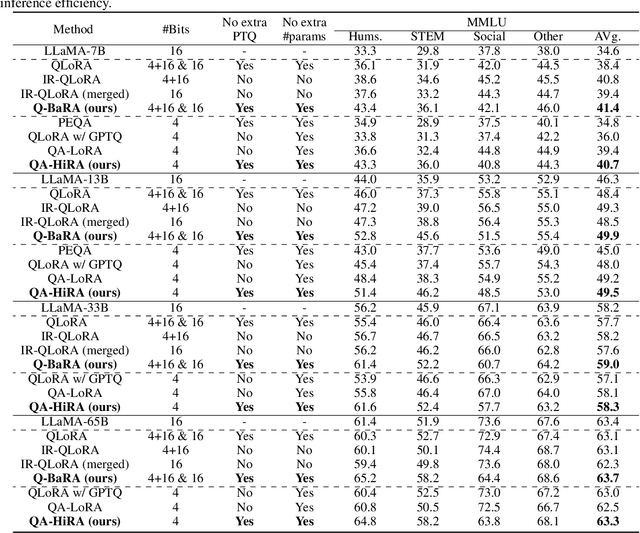
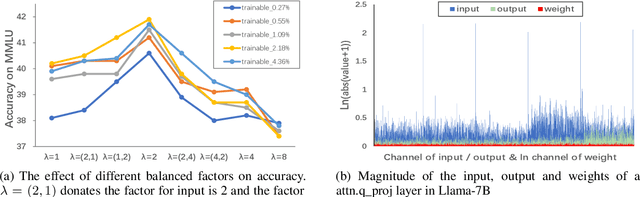
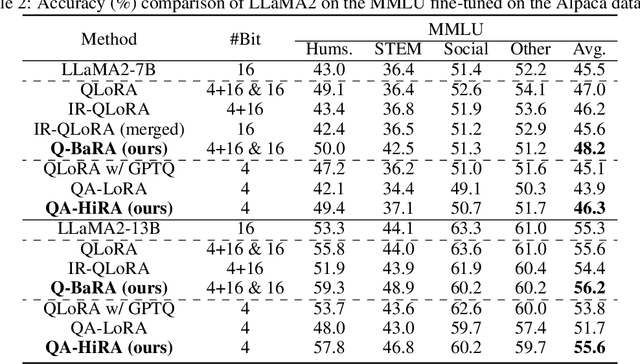
Large Language Models (LLMs) have demonstrated impressive performance across various domains. However, the enormous number of model parameters makes fine-tuning challenging, significantly limiting their application and deployment. Existing solutions combine parameter quantization with Low-Rank Adaptation (LoRA), greatly reducing memory usage but resulting in noticeable performance degradation. In this paper, we identify an imbalance in fine-tuning quantized pre-trained models: overly complex adapter inputs and outputs versus low effective trainability of the adaptation. We propose Quantized LLMs with Balanced-rank Adaptation (Q-BaRA), which simplifies the adapter inputs and outputs while increasing the adapter's rank to achieve a more suitable balance for fine-tuning quantized LLMs. Additionally, for scenarios where fine-tuned LLMs need to be deployed as low-precision inference models, we introduce Quantization-Aware Fine-tuning with Higher Rank Adaptation (QA-HiRA), which simplifies the adapter inputs and outputs to align with the pre-trained model's block-wise quantization while employing a single matrix to achieve a higher rank. Both Q-BaRA and QA-HiRA are easily implemented and offer the following optimizations: (i) Q-BaRA consistently achieves the highest accuracy compared to baselines and other variants, requiring the same number of trainable parameters and computational effort; (ii) QA-HiRA naturally merges adapter parameters into the block-wise quantized model after fine-tuning, achieving the highest accuracy compared to other methods. We apply our Q-BaRA and QA-HiRA to the LLaMA and LLaMA2 model families and validate their effectiveness across different fine-tuning datasets and downstream scenarios. Code will be made available at \href{https://github.com/xiaocaigou/qbaraqahira}{https://github.com/xiaocaigou/qbaraqahira}
Marine Debris Detection in Satellite Surveillance using Attention Mechanisms
Jul 09, 2023Marine debris is an important issue for environmental protection, but current methods for locating marine debris are yet limited. In order to achieve higher efficiency and wider applicability in the localization of Marine debris, this study tries to combine the instance segmentation of YOLOv7 with different attention mechanisms and explores the best model. By utilizing a labelled dataset consisting of satellite images containing ocean debris, we examined three attentional models including lightweight coordinate attention, CBAM (combining spatial and channel focus), and bottleneck transformer (based on self-attention). Box detection assessment revealed that CBAM achieved the best outcome (F1 score of 77%) compared to coordinate attention (F1 score of 71%) and YOLOv7/bottleneck transformer (both F1 scores around 66%). Mask evaluation showed CBAM again leading with an F1 score of 73%, whereas coordinate attention and YOLOv7 had comparable performances (around F1 score of 68%/69%) and bottleneck transformer lagged behind at F1 score of 56%. These findings suggest that CBAM offers optimal suitability for detecting marine debris. However, it should be noted that the bottleneck transformer detected some areas missed by manual annotation and displayed better mask precision for larger debris pieces, signifying potentially superior practical performance.