 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance
Jul 24, 2024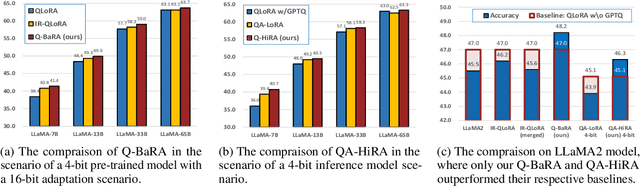
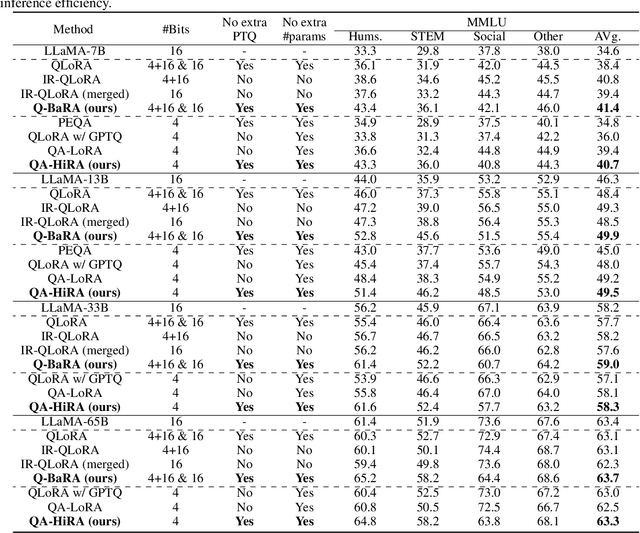
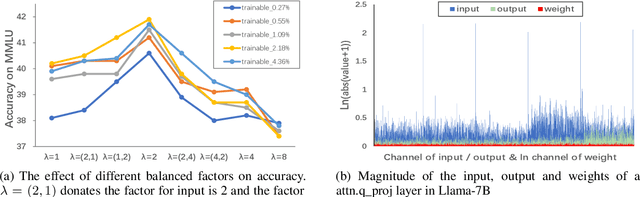
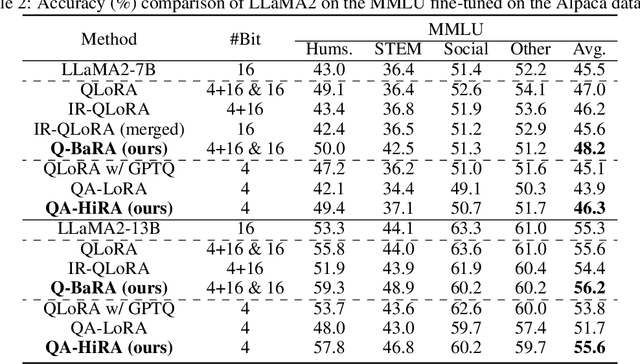
Large Language Models (LLMs) have demonstrated impressive performance across various domains. However, the enormous number of model parameters makes fine-tuning challenging, significantly limiting their application and deployment. Existing solutions combine parameter quantization with Low-Rank Adaptation (LoRA), greatly reducing memory usage but resulting in noticeable performance degradation. In this paper, we identify an imbalance in fine-tuning quantized pre-trained models: overly complex adapter inputs and outputs versus low effective trainability of the adaptation. We propose Quantized LLMs with Balanced-rank Adaptation (Q-BaRA), which simplifies the adapter inputs and outputs while increasing the adapter's rank to achieve a more suitable balance for fine-tuning quantized LLMs. Additionally, for scenarios where fine-tuned LLMs need to be deployed as low-precision inference models, we introduce Quantization-Aware Fine-tuning with Higher Rank Adaptation (QA-HiRA), which simplifies the adapter inputs and outputs to align with the pre-trained model's block-wise quantization while employing a single matrix to achieve a higher rank. Both Q-BaRA and QA-HiRA are easily implemented and offer the following optimizations: (i) Q-BaRA consistently achieves the highest accuracy compared to baselines and other variants, requiring the same number of trainable parameters and computational effort; (ii) QA-HiRA naturally merges adapter parameters into the block-wise quantized model after fine-tuning, achieving the highest accuracy compared to other methods. We apply our Q-BaRA and QA-HiRA to the LLaMA and LLaMA2 model families and validate their effectiveness across different fine-tuning datasets and downstream scenarios. Code will be made available at \href{https://github.com/xiaocaigou/qbaraqahira}{https://github.com/xiaocaigou/qbaraqahira}