 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliance-to-Code: Enhancing Financial Compliance Checking via Code Generation
May 26, 2025
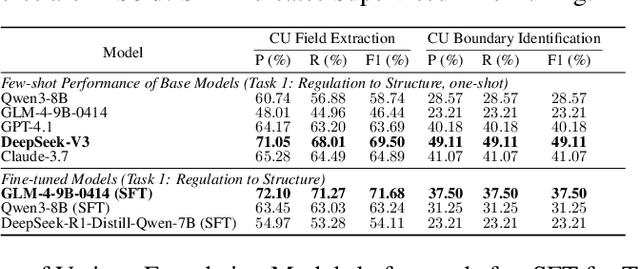
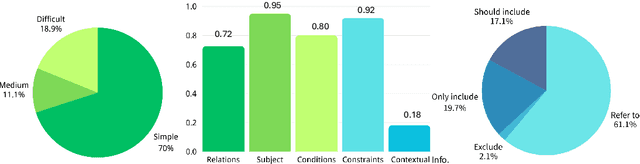
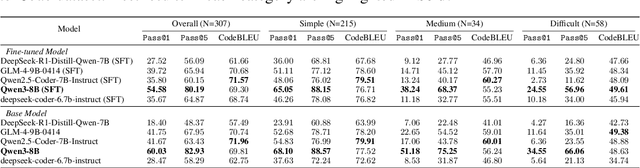
Nowadays, regulatory compliance has become a cornerstone of corporate governance, ensuring adherence to systematic legal frameworks. At its core, financial regulations often comprise highly intricate provisions, layered logical structures, and numerous exceptions, which inevitably result in labor-intensive or comprehension challenges. To mitigate this, recent Regulatory Technology (RegTech) and Large Language Models (LLMs) have gained significant attention in automating the conversion of regulatory text into executable compliance logic. However, their performance remains suboptimal particularly when applied to Chinese-language financial regulations, due to three key limitations: (1) incomplete domain-specific knowledge representation, (2) insufficient hierarchical reasoning capabilities, and (3) failure to maintain temporal and logical coherence. One promising solution is to develop a domain specific and code-oriented datasets for model training. Existing datasets such as LexGLUE, LegalBench, and CODE-ACCORD are often English-focused, domain-mismatched, or lack fine-grained granularity for compliance code generation. To fill these gaps, we present Compliance-to-Code, the first large-scale Chinese dataset dedicated to financial regulatory compliance. Covering 1,159 annotated clauses from 361 regulations across ten categories, each clause is modularly structured with four logical elements-subject, condition, constraint, and contextual information-along with regulation relations. We provide deterministic Python code mappings, detailed code reasoning, and code explanations to facilitate automated auditing. To demonstrate utility, we present FinCheck: a pipeline for regulation structuring, code generation, and report generation.
FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving
Nov 27, 2024



Serving numerous users and requests concurrently requires good fairness in Large Language Models (LLMs) serving system. This ensures that, at the same cost, the system can meet the Service Level Objectives (SLOs) of more users , such as time to first token (TTFT) and time between tokens (TBT), rather than allowing a few users to experience performance far exceeding the SLOs. To achieve better fairness, the preemption-based scheduling policy dynamically adjusts the priority of each request to maintain balance during runtime. However, existing systems tend to overly prioritize throughput, overlooking the overhead caused by preemption-induced context switching, which is crucial for maintaining fairness through priority adjustments. In this work, we identify three main challenges that result in this overhead. 1) Inadequate I/O utilization. 2) GPU idleness. 3) Unnecessary I/O transmission during multi-turn conversations. Our key insight is that the block-based KV cache memory policy in existing systems, while achieving near-zero memory waste, leads to discontinuity and insufficient granularity in the KV cache memory. To respond, we introduce FastSwitch, a fairness-aware serving system that not only aligns with existing KV cache memory allocation policy but also mitigates context switching overhead. Our evaluation shows that FastSwitch outperforms the state-of-the-art LLM serving system vLLM with speedups of 1.4-11.2x across different tail TTFT and TBT.
KAPLA: Pragmatic Representation and Fast Solving of Scalable NN Accelerator Dataflow
Jun 09, 2023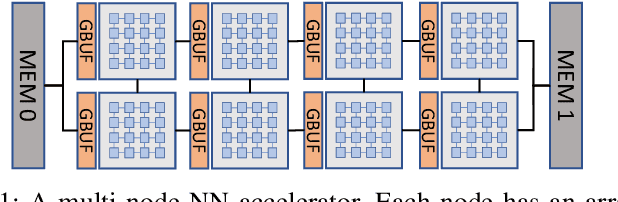
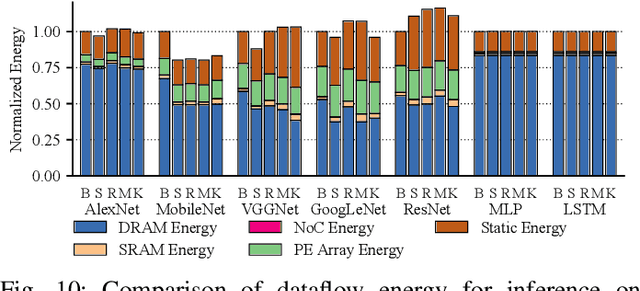
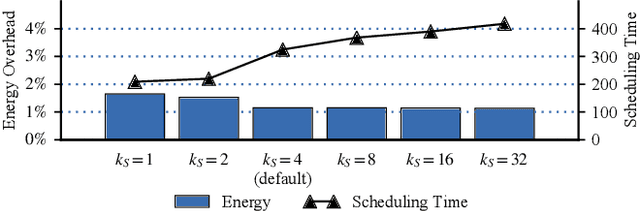
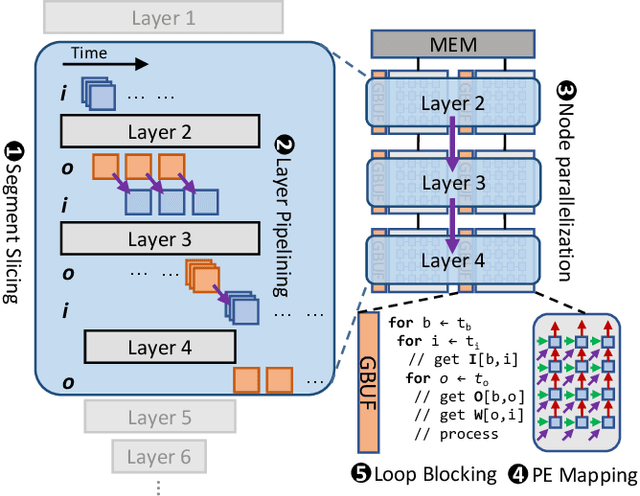
Dataflow scheduling decisions are of vital importance to neural network (NN) accelerators. Recent scalable NN accelerators support a rich set of advanced dataflow techniques. The problems of comprehensively representing and quickly finding optimized dataflow schemes thus become significantly more complicated and challenging. In this work, we first propose comprehensive and pragmatic dataflow representations for temporal and spatial scheduling on scalable multi-node NN architectures. An informal hierarchical taxonomy highlights the tight coupling across different levels of the dataflow space as the major difficulty for fast design exploration. A set of formal tensor-centric directives accurately express various inter-layer and intra-layer schemes, and allow for quickly determining their validity and efficiency. We then build a generic, optimized, and fast dataflow solver, KAPLA, which makes use of the pragmatic directives to explore the design space with effective validity check and efficiency estimation. KAPLA decouples the upper inter-layer level for fast pruning, and solves the lower intra-layer schemes with a novel bottom-up cost descending method. KAPLA achieves within only 2.2% and 7.7% energy overheads on the result dataflow for training and inference, respectively, compared to the exhaustively searched optimal schemes. It also outperforms random and machine-learning-based approaches, with more optimized results and orders of magnitude faster search speedup.