 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandit Approach for Optimizing Training on Synthetic Data
Dec 06, 2024



Supervised machine learning methods require large-scale training datasets to perform well in practice. Synthetic data has been showing great progress recently and has been used as a complement to real data. However, there is yet a great urge to assess the usability of synthetically generated data. To this end, we propose a novel UCB-based training procedure combined with a dynamic usability metric. Our proposed metric integrates low-level and high-level information from synthetic images and their corresponding real and synthetic datasets, surpassing existing traditional metrics. By utilizing a UCB-based dynamic approach ensures continual enhancement of model learning. Unlike other approaches, our method effectively adapts to changes in the machine learning model's state and considers the evolving utility of training samples during the training process. We show that our metric is an effective way to rank synthetic images based on their usability. Furthermore, we propose a new attribute-aware bandit pipeline for generating synthetic data by integrating a Large Language Model with Stable Diffusion. Quantitative results show that our approach can boost the performance of a wide range of supervised classifiers. Notably, we observed an improvement of up to 10% in classification accuracy compared to traditional approaches, demonstrating the effectiveness of our approach. Our source code, datasets, and additional materials are publically available at https://github.com/A-Kerim/Synthetic-Data-Usability-2024.
Advancing Explainable AI Toward Human-Like Intelligence: Forging the Path to Artificial Brain
Feb 07, 2024The intersection of Artificial Intelligence (AI) and neuroscience in Explainable AI (XAI) is pivotal for enhancing transparency and interpretability in complex decision-making processes. This paper explores the evolution of XAI methodologies, ranging from feature-based to human-centric approaches, and delves into their applications in diverse domains, including healthcare and finance. The challenges in achieving explainability in generative models, ensuring responsible AI practices, and addressing ethical implications are discussed. The paper further investigates the potential convergence of XAI with cognitive sciences, the development of emotionally intelligent AI, and the quest for Human-Like Intelligence (HLI) in AI systems. As AI progresses towards Artificial General Intelligence (AGI), considerations of consciousness, ethics, and societal impact become paramount. The ongoing pursuit of deciphering the mysteries of the brain with AI and the quest for HLI represent transformative endeavors, bridging technical advancements with multidisciplinary explorations of human cognition.
Reconstructing the Invisible: Video Frame Restoration through Siamese Masked Conditional Variational Autoencoder
Jan 18, 2024In the domain of computer vision, the restoration of missing information in video frames is a critical challenge, particularly in applications such as autonomous driving and surveillance systems. This paper introduces the Siamese Masked Conditional Variational Autoencoder (SiamMCVAE), leveraging a siamese architecture with twin encoders based on vision transformers. This innovative design enhances the model's ability to comprehend lost content by capturing intrinsic similarities between paired frames. SiamMCVAE proficiently reconstructs missing elements in masked frames, effectively addressing issues arising from camera malfunctions through variational inferences. Experimental results robustly demonstrate the model's effectiveness in restoring missing information, thus enhancing the resilience of computer vision systems. The incorporation of Siamese Vision Transformer (SiamViT) encoders in SiamMCVAE exemplifies promising potential for addressing real-world challenges in computer vision, reinforcing the adaptability of autonomous systems in dynamic environments.
Triamese-ViT: A 3D-Aware Method for Robust Brain Age Estimation from MRIs
Jan 13, 2024The integration of machine learning in medicine has significantly improved diagnostic precision, particularly in the interpretation of complex structures like the human brain. Diagnosing challenging conditions such as Alzheimer's disease has prompted the development of brain age estimation techniques. These methods often leverage three-dimensional Magnetic Resonance Imaging (MRI) scans, with recent studies emphasizing the efficacy of 3D convolutional neural networks (CNNs) like 3D ResNet. However, the untapped potential of Vision Transformers (ViTs), known for their accuracy and interpretability, persists in this domain due to limitations in their 3D versions. This paper introduces Triamese-ViT, an innovative adaptation of the ViT model for brain age estimation. Our model uniquely combines ViTs from three different orientations to capture 3D information, significantly enhancing accuracy and interpretability. Tested on a dataset of 1351 MRI scans, Triamese-ViT achieves a Mean Absolute Error (MAE) of 3.84, a 0.9 Spearman correlation coefficient with chronological age, and a -0.29 Spearman correlation coefficient between the brain age gap (BAG) and chronological age, significantly better than previous methods for brian age estimation. A key innovation of Triamese-ViT is its capacity to generate a comprehensive 3D-like attention map, synthesized from 2D attention maps of each orientation-specific ViT. This feature is particularly beneficial for in-depth brain age analysis and disease diagnosis, offering deeper insights into brain health and the mechanisms of age-related neural changes.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023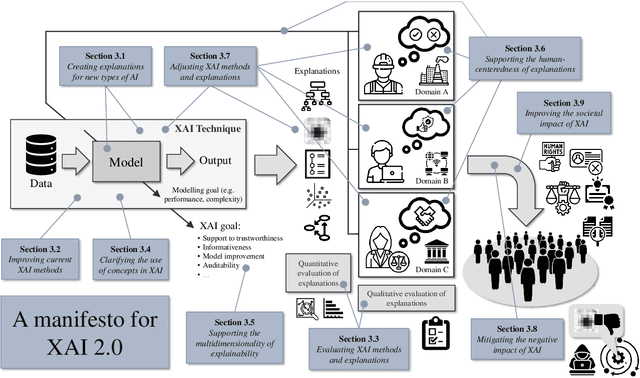
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Marine Debris Detection in Satellite Surveillance using Attention Mechanisms
Jul 09, 2023Marine debris is an important issue for environmental protection, but current methods for locating marine debris are yet limited. In order to achieve higher efficiency and wider applicability in the localization of Marine debris, this study tries to combine the instance segmentation of YOLOv7 with different attention mechanisms and explores the best model. By utilizing a labelled dataset consisting of satellite images containing ocean debris, we examined three attentional models including lightweight coordinate attention, CBAM (combining spatial and channel focus), and bottleneck transformer (based on self-attention). Box detection assessment revealed that CBAM achieved the best outcome (F1 score of 77%) compared to coordinate attention (F1 score of 71%) and YOLOv7/bottleneck transformer (both F1 scores around 66%). Mask evaluation showed CBAM again leading with an F1 score of 73%, whereas coordinate attention and YOLOv7 had comparable performances (around F1 score of 68%/69%) and bottleneck transformer lagged behind at F1 score of 56%. These findings suggest that CBAM offers optimal suitability for detecting marine debris. However, it should be noted that the bottleneck transformer detected some areas missed by manual annotation and displayed better mask precision for larger debris pieces, signifying potentially superior practical performance.
Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach
Oct 11, 2022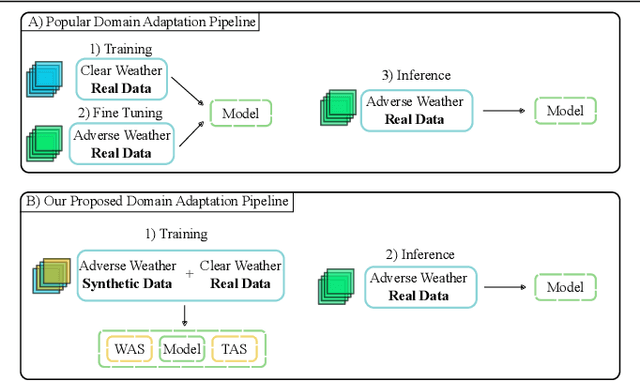


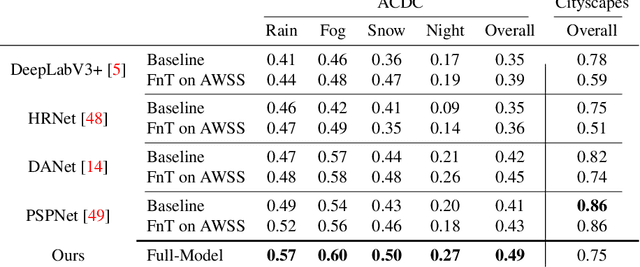
Recent semantic segmentation models perform well under standard weather conditions and sufficient illumination but struggle with adverse weather conditions and nighttime. Collecting and annotating training data under these conditions is expensive, time-consuming, error-prone, and not always practical. Usually, synthetic data is used as a feasible data source to increase the amount of training data. However, just directly using synthetic data may actually harm the model's performance under normal weather conditions while getting only small gains in adverse situations. Therefore, we present a novel architecture specifically designed for using synthetic training data for domain adaptation. We propose a simple yet powerful addition to DeepLabV3+ by using weather and time-of-the-day supervisors trained with multi-task learning, making it both weather and nighttime aware, which improves its mIoU accuracy by $14$ percentage points on the ACDC dataset while maintaining a score of $75\%$ mIoU on the Cityscapes dataset. Our code is available at https://github.com/lsmcolab/Semantic-Segmentation-under-Adverse-Conditions.
Leveraging Synthetic Data to Learn Video Stabilization Under Adverse Conditions
Aug 26, 2022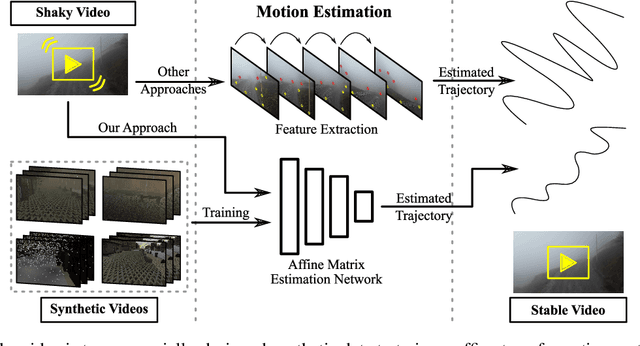
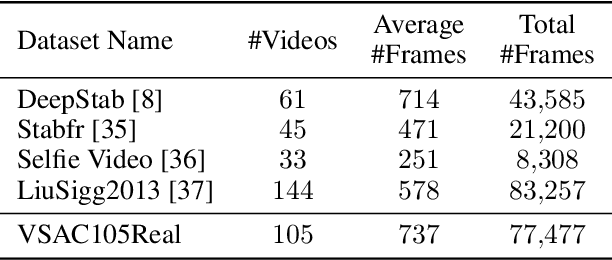
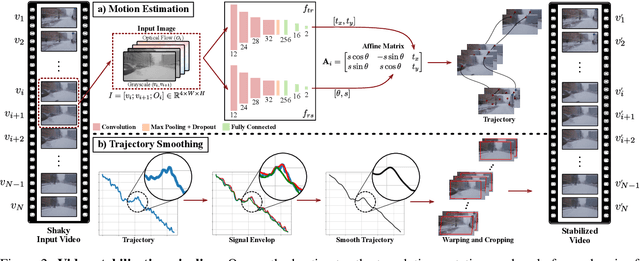
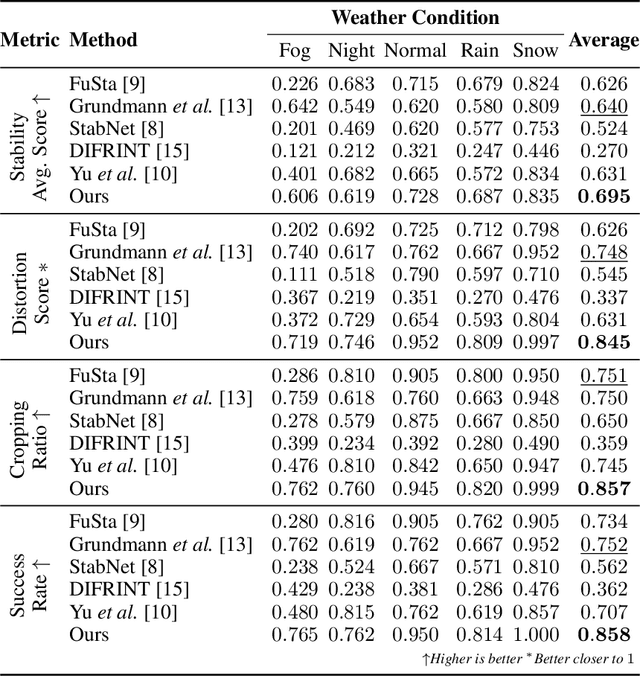
Video stabilization plays a central role to improve videos quality. However, despite the substantial progress made by these methods, they were, mainly, tested under standard weather and lighting conditions, and may perform poorly under adverse conditions. In this paper, we propose a synthetic-aware adverse weather robust algorithm for video stabilization that does not require real data and can be trained only on synthetic data. We also present Silver, a novel rendering engine to generate the required training data with an automatic ground-truth extraction procedure. Our approach uses our specially generated synthetic data for training an affine transformation matrix estimator avoiding the feature extraction issues faced by current methods. Additionally, since no video stabilization datasets under adverse conditions are available, we propose the novel VSAC105Real dataset for evaluation. We compare our method to five state-of-the-art video stabilization algorithms using two benchmarks. Our results show that current approaches perform poorly in at least one weather condition, and that, even training in a small dataset with synthetic data only, we achieve the best performance in terms of stability average score, distortion score, success rate, and average cropping ratio when considering all weather conditions. Hence, our video stabilization model generalizes well on real-world videos and does not require large-scale synthetic training data to converge.
Review on Social Behavior Analysis of Laboratory Animals: From Methodologies to Applications
Jun 25, 2022


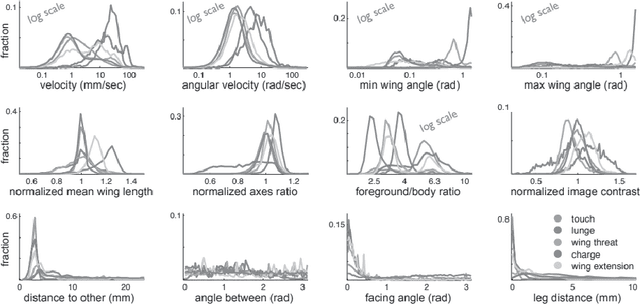
As the bridge between genetic and physiological aspects, animal behaviour analysis is one of the most significant topics in biology and ecological research. However, identifying, tracking and recording animal behaviour are labour intensive works that require professional knowledge. To mitigate the spend for annotating data, researchers turn to computer vision techniques for automatic label algorithms, since most of the data are recorded visually. In this work, we explore a variety of behaviour detection algorithms, covering traditional vision methods, statistical methods and deep learning methods. The objective of this work is to provide a thorough investigation of related work, furnishing biologists with a scratch of efficient animal behaviour detection methods. Apart from that, we also discuss the strengths and weaknesses of those algorithms to provide some insights for those who already delve into this field.
* https://www.routledge.com/Recent-Advances-in-AI-enabled-Automated-Medical-Diagnosis/Jiang-Crookes-Wei-Zhang-Chazot/p/book/9781032008431
Machine Learning-based Biological Ageing Estimation Technologies: A Survey
Jun 25, 2022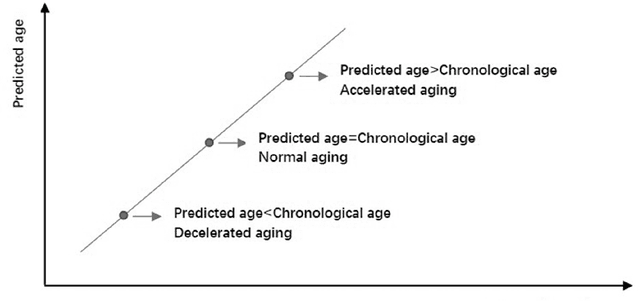


In recent years, there are various methods of estimating Biological Age (BA) have been developed. Especially with the development of machine learning (ML), there are more and more types of BA predictions, and the accuracy has been greatly improved. The models for the estimation of BA play an important role in monitoring healthy aging, and could provide new tools to detect health status in the general population and give warnings to sub-healthy people. We will mainly review three age prediction methods by using ML. They are based on blood biomarkers, facial images, and structural neuroimaging features. For now, the model using blood biomarkers is the simplest, most direct, and most accurate method. The face image method is affected by various aspects such as race, environment, etc., the prediction accuracy is not very good, which cannot make a great contribution to the medical field. In summary, we are here to track the way forward in the era of big data for us and other potential general populations and show ways to leverage the vast amounts of data available today.
* in Recent Advances in AI-enabled Automated Medical Diagnosis https://www.routledge.com/Recent-Advances-in-AI-enabled-Automated-Medical-Diagnosis/Jiang-Crookes-Wei-Zhang-Chazot/p/book/9781032008431