 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Apr 13, 2026Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-language models. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .
Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach
Oct 11, 2022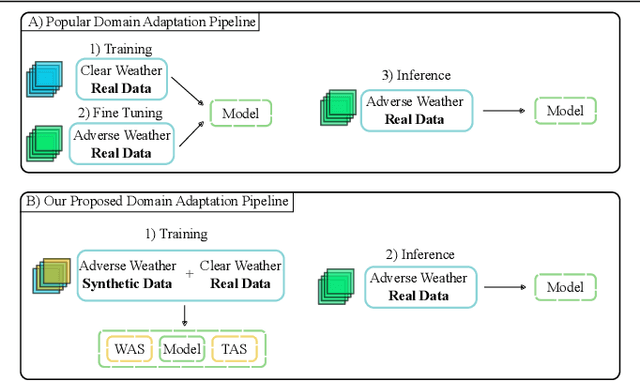


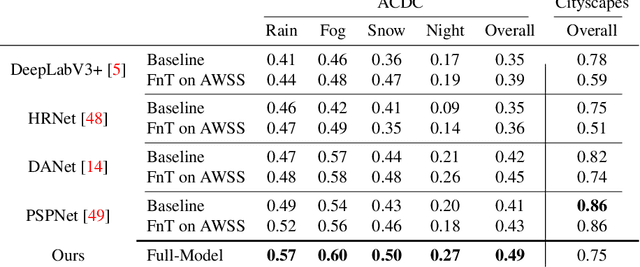
Recent semantic segmentation models perform well under standard weather conditions and sufficient illumination but struggle with adverse weather conditions and nighttime. Collecting and annotating training data under these conditions is expensive, time-consuming, error-prone, and not always practical. Usually, synthetic data is used as a feasible data source to increase the amount of training data. However, just directly using synthetic data may actually harm the model's performance under normal weather conditions while getting only small gains in adverse situations. Therefore, we present a novel architecture specifically designed for using synthetic training data for domain adaptation. We propose a simple yet powerful addition to DeepLabV3+ by using weather and time-of-the-day supervisors trained with multi-task learning, making it both weather and nighttime aware, which improves its mIoU accuracy by $14$ percentage points on the ACDC dataset while maintaining a score of $75\%$ mIoU on the Cityscapes dataset. Our code is available at https://github.com/lsmcolab/Semantic-Segmentation-under-Adverse-Conditions.
Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method
Mar 29, 2022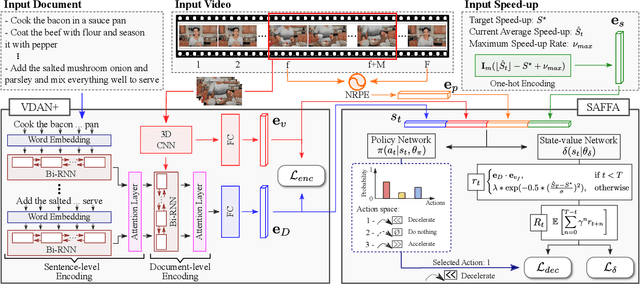

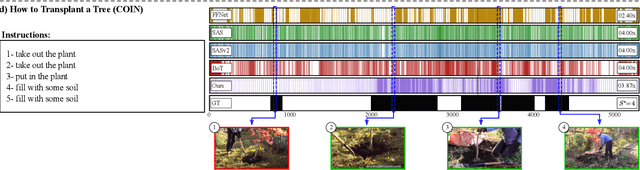
The growth of videos in our digital age and the users' limited time raise the demand for processing untrimmed videos to produce shorter versions conveying the same information. Despite the remarkable progress that summarization methods have made, most of them can only select a few frames or skims, creating visual gaps and breaking the video context. This paper presents a novel weakly-supervised methodology based on a reinforcement learning formulation to accelerate instructional videos using text. A novel joint reward function guides our agent to select which frames to remove and reduce the input video to a target length without creating gaps in the final video. We also propose the Extended Visually-guided Document Attention Network (VDAN+), which can generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in Precision, Recall, and F1 Score against the baselines while effectively controlling the video's output length. Visit https://www.verlab.dcc.ufmg.br/semantic-hyperlapse/tpami2022/ for code and extra results.
Straight to the Point: Fast-forwarding Videos via Reinforcement Learning Using Textual Data
Mar 31, 2020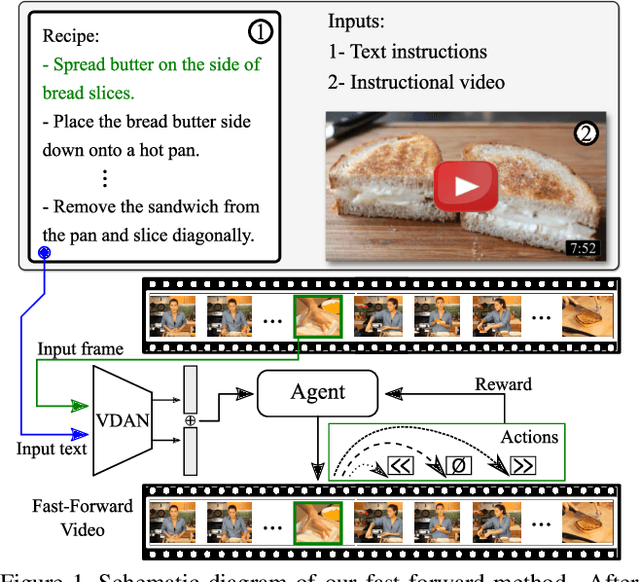
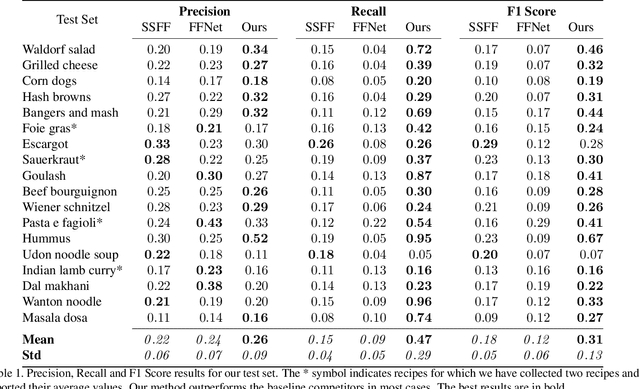
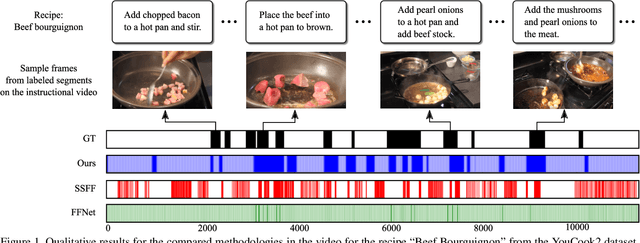
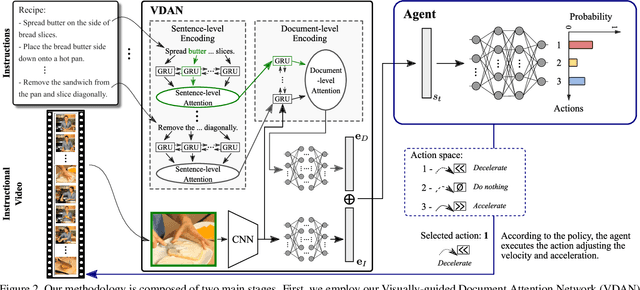
The rapid increase in the amount of published visual data and the limited time of users bring the demand for processing untrimmed videos to produce shorter versions that convey the same information. Despite the remarkable progress that has been made by summarization methods, most of them can only select a few frames or skims, which creates visual gaps and breaks the video context. In this paper, we present a novel methodology based on a reinforcement learning formulation to accelerate instructional videos. Our approach can adaptively select frames that are not relevant to convey the information without creating gaps in the final video. Our agent is textually and visually oriented to select which frames to remove to shrink the input video. Additionally, we propose a novel network, called Visually-guided Document Attention Network (VDAN), able to generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in terms of F1 Score and coverage at the video segment level.