 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandit Approach for Optimizing Training on Synthetic Data
Dec 06, 2024



Supervised machine learning methods require large-scale training datasets to perform well in practice. Synthetic data has been showing great progress recently and has been used as a complement to real data. However, there is yet a great urge to assess the usability of synthetically generated data. To this end, we propose a novel UCB-based training procedure combined with a dynamic usability metric. Our proposed metric integrates low-level and high-level information from synthetic images and their corresponding real and synthetic datasets, surpassing existing traditional metrics. By utilizing a UCB-based dynamic approach ensures continual enhancement of model learning. Unlike other approaches, our method effectively adapts to changes in the machine learning model's state and considers the evolving utility of training samples during the training process. We show that our metric is an effective way to rank synthetic images based on their usability. Furthermore, we propose a new attribute-aware bandit pipeline for generating synthetic data by integrating a Large Language Model with Stable Diffusion. Quantitative results show that our approach can boost the performance of a wide range of supervised classifiers. Notably, we observed an improvement of up to 10% in classification accuracy compared to traditional approaches, demonstrating the effectiveness of our approach. Our source code, datasets, and additional materials are publically available at https://github.com/A-Kerim/Synthetic-Data-Usability-2024.
Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach
Oct 11, 2022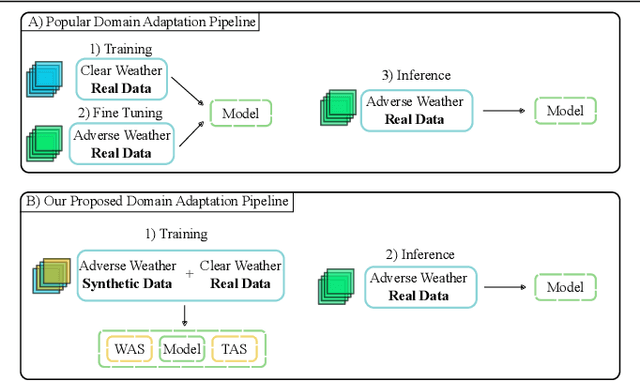


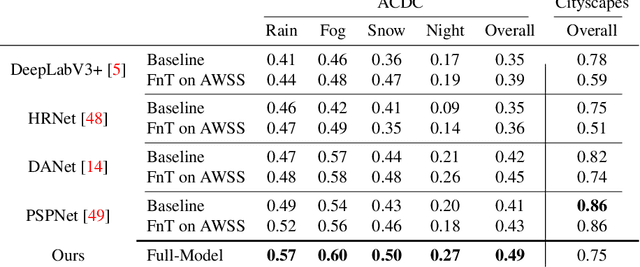
Recent semantic segmentation models perform well under standard weather conditions and sufficient illumination but struggle with adverse weather conditions and nighttime. Collecting and annotating training data under these conditions is expensive, time-consuming, error-prone, and not always practical. Usually, synthetic data is used as a feasible data source to increase the amount of training data. However, just directly using synthetic data may actually harm the model's performance under normal weather conditions while getting only small gains in adverse situations. Therefore, we present a novel architecture specifically designed for using synthetic training data for domain adaptation. We propose a simple yet powerful addition to DeepLabV3+ by using weather and time-of-the-day supervisors trained with multi-task learning, making it both weather and nighttime aware, which improves its mIoU accuracy by $14$ percentage points on the ACDC dataset while maintaining a score of $75\%$ mIoU on the Cityscapes dataset. Our code is available at https://github.com/lsmcolab/Semantic-Segmentation-under-Adverse-Conditions.
Leveraging Synthetic Data to Learn Video Stabilization Under Adverse Conditions
Aug 26, 2022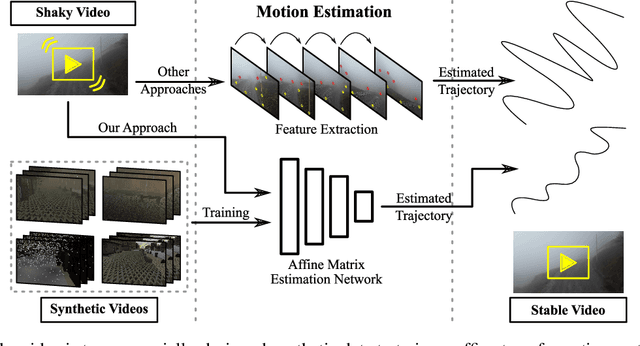
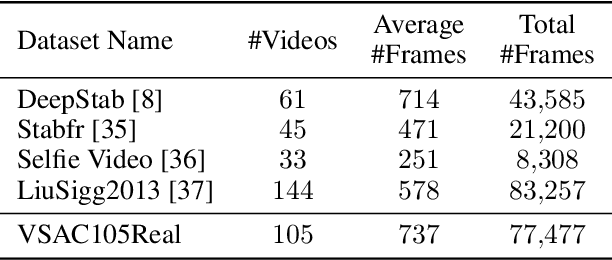
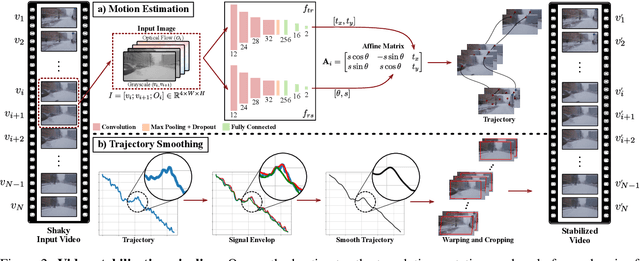
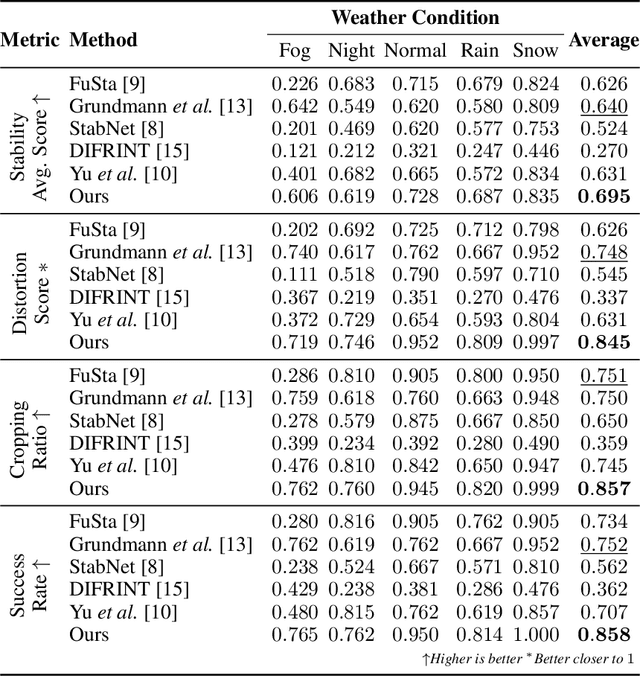
Video stabilization plays a central role to improve videos quality. However, despite the substantial progress made by these methods, they were, mainly, tested under standard weather and lighting conditions, and may perform poorly under adverse conditions. In this paper, we propose a synthetic-aware adverse weather robust algorithm for video stabilization that does not require real data and can be trained only on synthetic data. We also present Silver, a novel rendering engine to generate the required training data with an automatic ground-truth extraction procedure. Our approach uses our specially generated synthetic data for training an affine transformation matrix estimator avoiding the feature extraction issues faced by current methods. Additionally, since no video stabilization datasets under adverse conditions are available, we propose the novel VSAC105Real dataset for evaluation. We compare our method to five state-of-the-art video stabilization algorithms using two benchmarks. Our results show that current approaches perform poorly in at least one weather condition, and that, even training in a small dataset with synthetic data only, we achieve the best performance in terms of stability average score, distortion score, success rate, and average cropping ratio when considering all weather conditions. Hence, our video stabilization model generalizes well on real-world videos and does not require large-scale synthetic training data to converge.