 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHourly Short Term Load Forecasting for Residential Buildings and Energy Communities
Jan 31, 2025
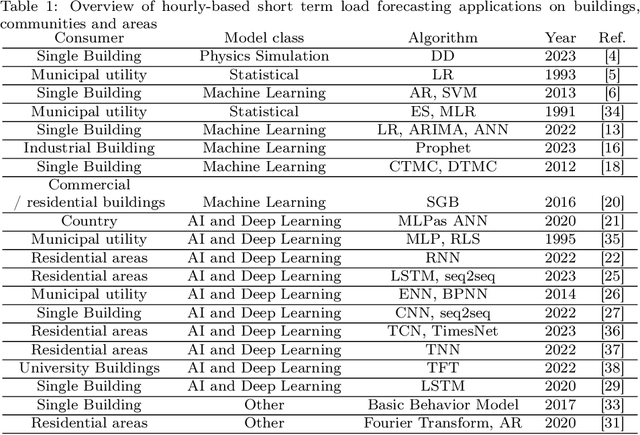


Electricity load consumption may be extremely complex in terms of profile patterns, as it depends on a wide range of human factors, and it is often correlated with several exogenous factors, such as the availability of renewable energy and the weather conditions. The first goal of this paper is to investigate the performance of a large selection of different types of forecasting models in predicting the electricity load consumption within the short time horizon of a day or few hours ahead. Such forecasts may be rather useful for the energy management of individual residential buildings or small energy communities. In particular, we introduce persistence models, standard auto-regressive-based machine learning models, and more advanced deep learning models. The second goal of this paper is to introduce two alternative modeling approaches that are simpler in structure while they take into account domain specific knowledge, as compared to the previously mentioned black-box modeling techniques. In particular, we consider the persistence-based auto-regressive model (PAR) and the seasonal persistence-based regressive model (SPR), priorly introduced by the authors. In this paper, we specifically tailor these models to accommodate the generation of hourly forecasts. The introduced models and the induced comparative analysis extend prior work of the authors which was restricted to day-ahead forecasts. We observed a 15-30% increase in the prediction accuracy of the newly introduced hourly-based forecasting models over existing approaches.
Causal Time-Series Synchronization for Multi-Dimensional Forecasting
Nov 15, 2024The process industry's high expectations for Digital Twins require modeling approaches that can generalize across tasks and diverse domains with potentially different data dimensions and distributional shifts i.e., Foundational Models. Despite success in natural language processing and computer vision, transfer learning with (self-) supervised signals for pre-training general-purpose models is largely unexplored in the context of Digital Twins in the process industry due to challenges posed by multi-dimensional time-series data, lagged cause-effect dependencies, complex causal structures, and varying number of (exogenous) variables. We propose a novel channel-dependent pre-training strategy that leverages synchronized cause-effect pairs to overcome these challenges by breaking down the multi-dimensional time-series data into pairs of cause-effect variables. Our approach focuses on: (i) identifying highly lagged causal relationships using data-driven methods, (ii) synchronizing cause-effect pairs to generate training samples for channel-dependent pre-training, and (iii) evaluating the effectiveness of this approach in channel-dependent forecasting. Our experimental results demonstrate significant improvements in forecasting accuracy and generalization capability compared to traditional training methods.
Safety-Driven Deep Reinforcement Learning Framework for Cobots: A Sim2Real Approach
Jul 02, 2024This study presents a novel methodology incorporating safety constraints into a robotic simulation during the training of deep reinforcement learning (DRL). The framework integrates specific parts of the safety requirements, such as velocity constraints, as specified by ISO 10218, directly within the DRL model that becomes a part of the robot's learning algorithm. The study then evaluated the efficiency of these safety constraints by subjecting the DRL model to various scenarios, including grasping tasks with and without obstacle avoidance. The validation process involved comprehensive simulation-based testing of the DRL model's responses to potential hazards and its compliance. Also, the performance of the system is carried out by the functional safety standards IEC 61508 to determine the safety integrity level. The study indicated a significant improvement in the safety performance of the robotic system. The proposed DRL model anticipates and mitigates hazards while maintaining operational efficiency. This study was validated in a testbed with a collaborative robotic arm with safety sensors and assessed with metrics such as the average number of safety violations, obstacle avoidance, and the number of successful grasps. The proposed approach outperforms the conventional method by a 16.5% average success rate on the tested scenarios in the simulations and 2.5% in the testbed without safety violations. The project repository is available at https://github.com/ammar-n-abbas/sim2real-ur-gym-gazebo.
Learning Paradigms and Modelling Methodologies for Digital Twins in Process Industry
Jul 02, 2024Central to the digital transformation of the process industry are Digital Twins (DTs), virtual replicas of physical manufacturing systems that combine sensor data with sophisticated data-based or physics-based models, or a combination thereof, to tackle a variety of industrial-relevant tasks like process monitoring, predictive control or decision support. The backbone of a DT, i.e. the concrete modelling methodologies and architectural frameworks supporting these models, are complex, diverse and evolve fast, necessitating a thorough understanding of the latest state-of-the-art methods and trends to stay on top of a highly competitive market. From a research perspective, despite the high research interest in reviewing various aspects of DTs, structured literature reports specifically focusing on unravelling the utilized learning paradigms (e.g. self-supervised learning) for DT-creation in the process industry are a novel contribution in this field. This study aims to address these gaps by (1) systematically analyzing the modelling methodologies (e.g. Convolutional Neural Network, Encoder-Decoder, Hidden Markov Model) and paradigms (e.g. data-driven, physics-based, hybrid) used for DT-creation; (2) assessing the utilized learning strategies (e.g. supervised, unsupervised, self-supervised); (3) analyzing the type of modelling task (e.g. regression, classification, clustering); and (4) identifying the challenges and research gaps, as well as, discuss potential resolutions provided.
Automated Knowledge Graph Learning in Industrial Processes
Jul 02, 2024Industrial processes generate vast amounts of time series data, yet extracting meaningful relationships and insights remains challenging. This paper introduces a framework for automated knowledge graph learning from time series data, specifically tailored for industrial applications. Our framework addresses the complexities inherent in industrial datasets, transforming them into knowledge graphs that improve decision-making, process optimization, and knowledge discovery. Additionally, it employs Granger causality to identify key attributes that can inform the design of predictive models. To illustrate the practical utility of our approach, we also present a motivating use case demonstrating the benefits of our framework in a real-world industrial scenario. Further, we demonstrate how the automated conversion of time series data into knowledge graphs can identify causal influences or dependencies between important process parameters.
AI-Powered Predictions for Electricity Load in Prosumer Communities
Feb 21, 2024The flexibility in electricity consumption and production in communities of residential buildings, including those with renewable energy sources and energy storage (a.k.a., prosumers), can effectively be utilized through the advancement of short-term demand response mechanisms. It is known that flexibility can further be increased if demand response is performed at the level of communities of prosumers, since aggregated groups can better coordinate electricity consumption. However, the effectiveness of such short-term optimization is highly dependent on the accuracy of electricity load forecasts both for each building as well as for the whole community. Structural variations in the electricity load profile can be associated with different exogenous factors, such as weather conditions, calendar information and day of the week, as well as user behavior. In this paper, we review a wide range of electricity load forecasting techniques, that can provide significant assistance in optimizing load consumption in prosumer communities. We present and test artificial intelligence (AI) powered short-term load forecasting methodologies that operate with black-box time series models, such as Facebook's Prophet and Long Short-term Memory (LSTM) models; season-based SARIMA and smoothing Holt-Winters models; and empirical regression-based models that utilize domain knowledge. The integration of weather forecasts into data-driven time series forecasts is also tested. Results show that the combination of persistent and regression terms (adapted to the load forecasting task) achieves the best forecast accuracy.
Hierarchical Framework for Interpretable and Probabilistic Model-Based Safe Reinforcement Learning
Oct 28, 2023


The difficulty of identifying the physical model of complex systems has led to exploring methods that do not rely on such complex modeling of the systems. Deep reinforcement learning has been the pioneer for solving this problem without the need for relying on the physical model of complex systems by just interacting with it. However, it uses a black-box learning approach that makes it difficult to be applied within real-world and safety-critical systems without providing explanations of the actions derived by the model. Furthermore, an open research question in deep reinforcement learning is how to focus the policy learning of critical decisions within a sparse domain. This paper proposes a novel approach for the use of deep reinforcement learning in safety-critical systems. It combines the advantages of probabilistic modeling and reinforcement learning with the added benefits of interpretability and works in collaboration and synchronization with conventional decision-making strategies. The BC-SRLA is activated in specific situations which are identified autonomously through the fused information of probabilistic model and reinforcement learning, such as abnormal conditions or when the system is near-to-failure. Further, it is initialized with a baseline policy using policy cloning to allow minimum interactions with the environment to address the challenges associated with using RL in safety-critical industries. The effectiveness of the BC-SRLA is demonstrated through a case study in maintenance applied to turbofan engines, where it shows superior performance to the prior art and other baselines.
* arXiv admin note: text overlap with arXiv:2206.13433
Specialized Deep Residual Policy Safe Reinforcement Learning-Based Controller for Complex and Continuous State-Action Spaces
Oct 15, 2023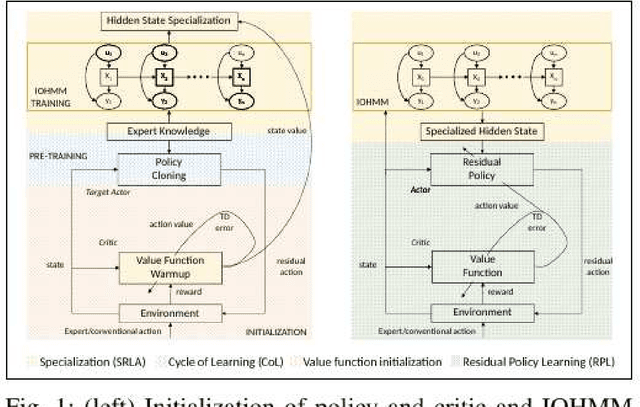
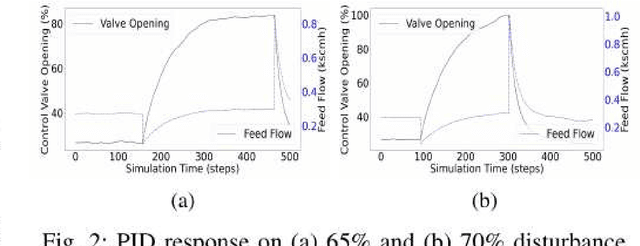
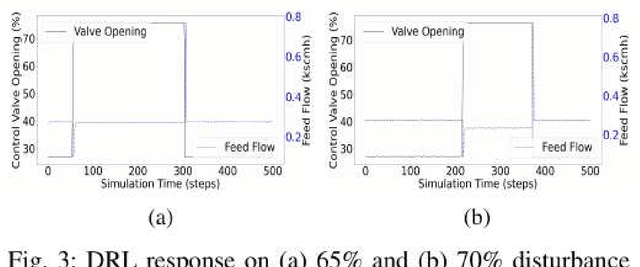
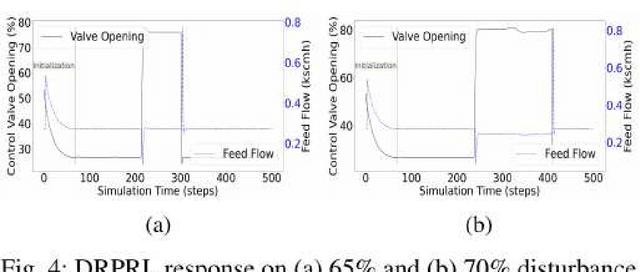
Traditional controllers have limitations as they rely on prior knowledge about the physics of the problem, require modeling of dynamics, and struggle to adapt to abnormal situations. Deep reinforcement learning has the potential to address these problems by learning optimal control policies through exploration in an environment. For safety-critical environments, it is impractical to explore randomly, and replacing conventional controllers with black-box models is also undesirable. Also, it is expensive in continuous state and action spaces, unless the search space is constrained. To address these challenges we propose a specialized deep residual policy safe reinforcement learning with a cycle of learning approach adapted for complex and continuous state-action spaces. Residual policy learning allows learning a hybrid control architecture where the reinforcement learning agent acts in synchronous collaboration with the conventional controller. The cycle of learning initiates the policy through the expert trajectory and guides the exploration around it. Further, the specialization through the input-output hidden Markov model helps to optimize policy that lies within the region of interest (such as abnormality), where the reinforcement learning agent is required and is activated. The proposed solution is validated on the Tennessee Eastman process control.
An Evolutionary Stochastic-Local-Search Framework for One-Dimensional Cutting-Stock Problems
Jul 27, 2017

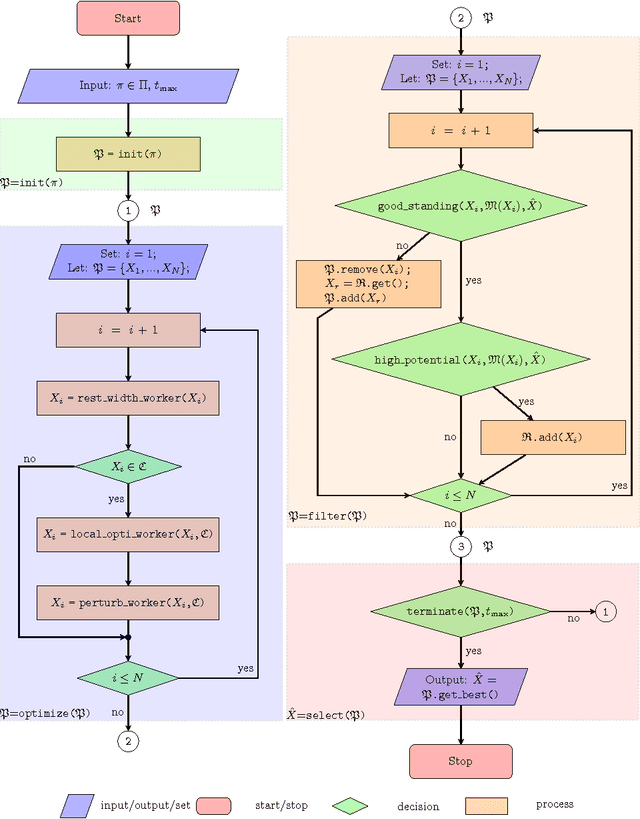

We introduce an evolutionary stochastic-local-search (SLS) algorithm for addressing a generalized version of the so-called 1/V/D/R cutting-stock problem. Cutting-stock problems are encountered often in industrial environments and the ability to address them efficiently usually results in large economic benefits. Traditionally linear-programming-based techniques have been utilized to address such problems, however their flexibility might be limited when nonlinear constraints and objective functions are introduced. To this end, this paper proposes an evolutionary SLS algorithm for addressing one-dimensional cutting-stock problems. The contribution lies in the introduction of a flexible structural framework of the optimization that may accommodate a large family of diversification strategies including a novel parallel pattern appropriate for SLS algorithms (not necessarily restricted to cutting-stock problems). We finally demonstrate through experiments in a real-world manufacturing problem the benefit in cost reduction of the considered diversification strategies.
Aspiration Learning in Coordination Games
Oct 19, 2011



We consider the problem of distributed convergence to efficient outcomes in coordination games through dynamics based on aspiration learning. Under aspiration learning, a player continues to play an action as long as the rewards received exceed a specified aspiration level. Here, the aspiration level is a fading memory average of past rewards, and these levels also are subject to occasional random perturbations. A player becomes dissatisfied whenever a received reward is less than the aspiration level, in which case the player experiments with a probability proportional to the degree of dissatisfaction. Our first contribution is the characterization of the asymptotic behavior of the induced Markov chain of the iterated process in terms of an equivalent finite-state Markov chain. We then characterize explicitly the behavior of the proposed aspiration learning in a generalized version of coordination games, examples of which include network formation and common-pool games. In particular, we show that in generic coordination games the frequency at which an efficient action profile is played can be made arbitrarily large. Although convergence to efficient outcomes is desirable, in several coordination games, such as common-pool games, attainability of fair outcomes, i.e., sequences of plays at which players experience highly rewarding returns with the same frequency, might also be of special interest. To this end, we demonstrate through analysis and simulations that aspiration learning also establishes fair outcomes in all symmetric coordination games, including common-pool games.