 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Knowledge Graph Learning in Industrial Processes
Jul 02, 2024



Industrial processes generate vast amounts of time series data, yet extracting meaningful relationships and insights remains challenging. This paper introduces a framework for automated knowledge graph learning from time series data, specifically tailored for industrial applications. Our framework addresses the complexities inherent in industrial datasets, transforming them into knowledge graphs that improve decision-making, process optimization, and knowledge discovery. Additionally, it employs Granger causality to identify key attributes that can inform the design of predictive models. To illustrate the practical utility of our approach, we also present a motivating use case demonstrating the benefits of our framework in a real-world industrial scenario. Further, we demonstrate how the automated conversion of time series data into knowledge graphs can identify causal influences or dependencies between important process parameters.
Advanced Detection of Source Code Clones via an Ensemble of Unsupervised Similarity Measures
May 03, 2024The capability of accurately determining code similarity is crucial in many tasks related to software development. For example, it might be essential to identify code duplicates for performing software maintenance. This research introduces a novel ensemble learning approach for code similarity assessment, combining the strengths of multiple unsupervised similarity measures. The key idea is that the strengths of a diverse set of similarity measures can complement each other and mitigate individual weaknesses, leading to improved performance. Preliminary results show that while Transformers-based CodeBERT and its variant GraphCodeBERT are undoubtedly the best option in the presence of abundant training data, in the case of specific small datasets (up to 500 samples), our ensemble achieves similar results, without prejudice to the interpretability of the resulting solution, and with a much lower associated carbon footprint due to training. The source code of this novel approach can be downloaded from https://github.com/jorge-martinez-gil/ensemble-codesim.
Source Code Clone Detection Using Unsupervised Similarity Measures
Jan 19, 2024Assessing similarity in source code has gained significant attention in recent years due to its importance in software engineering tasks such as clone detection and code search and recommendation. This work presents a comparative analysis of unsupervised similarity measures for identifying source code clone detection. The goal is to overview the current state-of-the-art techniques, their strengths, and weaknesses. To do that, we compile the existing unsupervised strategies and evaluate their performance on a benchmark dataset to guide software engineers in selecting appropriate methods for their specific use cases. The source code of this study is available at https://github.com/jorge-martinez-gil/codesim
Framework to Automatically Determine the Quality of Open Data Catalogs
Aug 14, 2023
Data catalogs play a crucial role in modern data-driven organizations by facilitating the discovery, understanding, and utilization of diverse data assets. However, ensuring their quality and reliability is complex, especially in open and large-scale data environments. This paper proposes a framework to automatically determine the quality of open data catalogs, addressing the need for efficient and reliable quality assessment mechanisms. Our framework can analyze various core quality dimensions, such as accuracy, completeness, consistency, scalability, and timeliness, offer several alternatives for the assessment of compatibility and similarity across such catalogs as well as the implementation of a set of non-core quality dimensions such as provenance, readability, and licensing. The goal is to empower data-driven organizations to make informed decisions based on trustworthy and well-curated data assets. The source code that illustrates our approach can be downloaded from https://www.github.com/jorge-martinez-gil/dataq/.
Automatic Design of Semantic Similarity Ensembles Using Grammatical Evolution
Jul 03, 2023
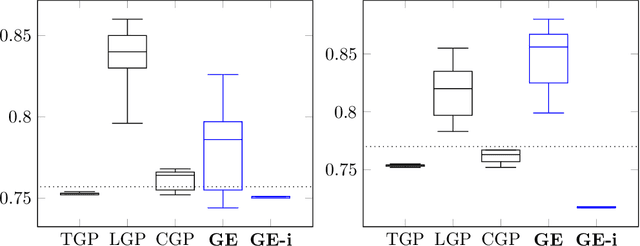
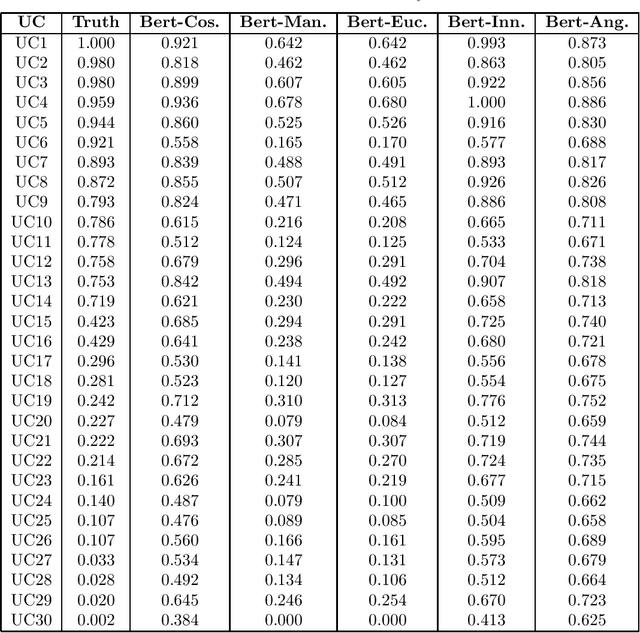
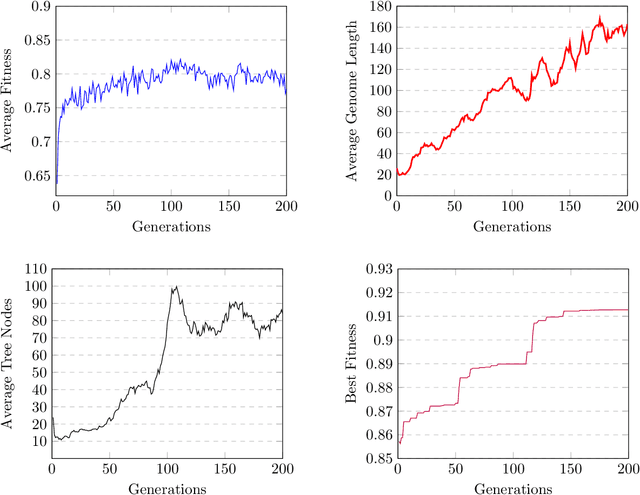
Semantic similarity measures are widely used in natural language processing to catalyze various computer-related tasks. However, no single semantic similarity measure is the most appropriate for all tasks, and researchers often use ensemble strategies to ensure performance. This research work proposes a method for automatically designing semantic similarity ensembles. In fact, our proposed method uses grammatical evolution, for the first time, to automatically select and aggregate measures from a pool of candidates to create an ensemble that maximizes correlation to human judgment. The method is evaluated on several benchmark datasets and compared to state-of-the-art ensembles, showing that it can significantly improve similarity assessment accuracy and outperform existing methods in some cases. As a result, our research demonstrates the potential of using grammatical evolution to automatically compare text and prove the benefits of using ensembles for semantic similarity tasks.
Context-Aware Semantic Similarity Measurement for Unsupervised Word Sense Disambiguation
May 05, 2023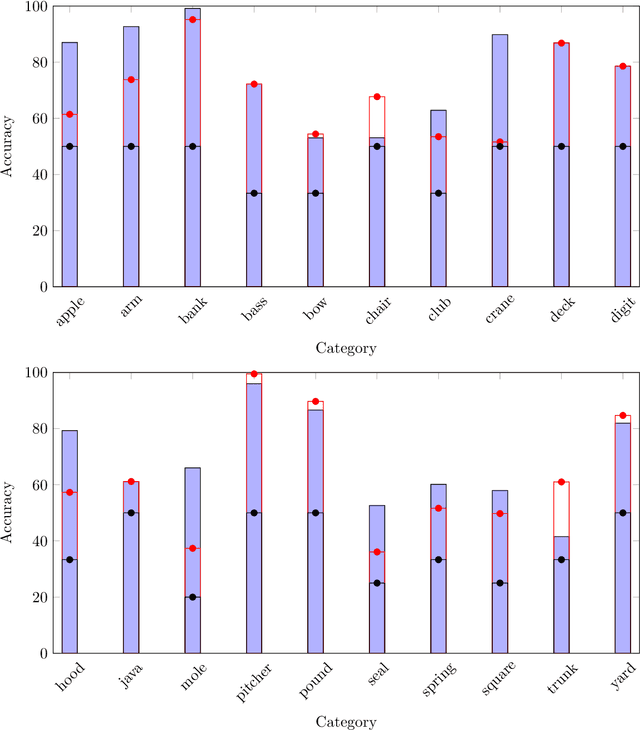
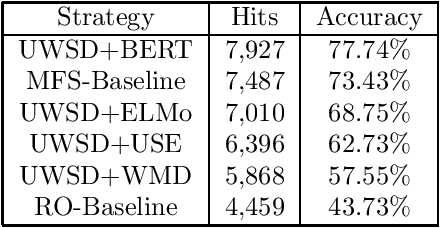
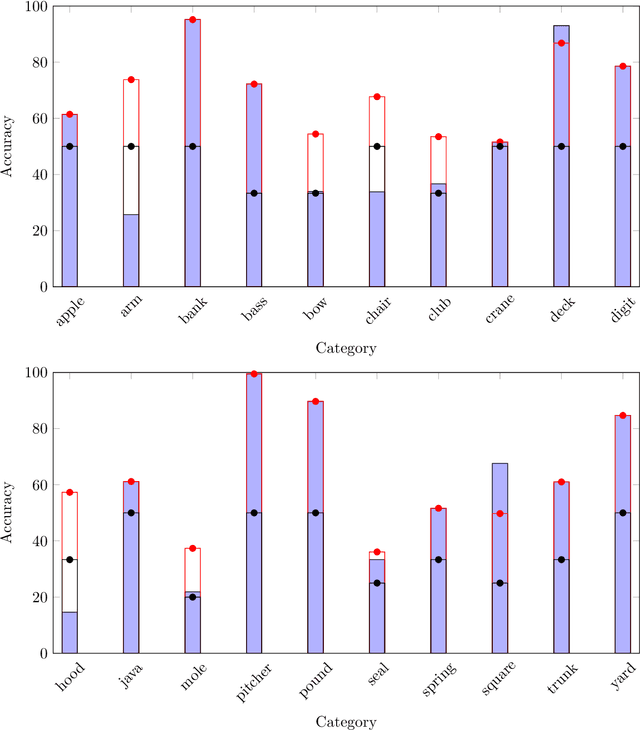

The issue of word sense ambiguity poses a significant challenge in natural language processing due to the scarcity of annotated data to feed machine learning models to face the challenge. Therefore, unsupervised word sense disambiguation methods have been developed to overcome that challenge without relying on annotated data. This research proposes a new context-aware approach to unsupervised word sense disambiguation, which provides a flexible mechanism for incorporating contextual information into the similarity measurement process. We experiment with a popular benchmark dataset to evaluate the proposed strategy and compare its performance with state-of-the-art unsupervised word sense disambiguation techniques. The experimental results indicate that our approach substantially enhances disambiguation accuracy and surpasses the performance of several existing techniques. Our findings underscore the significance of integrating contextual information in semantic similarity measurements to manage word sense ambiguity in unsupervised scenarios effectively.
Optimizing Readability Using Genetic Algorithms
Jan 01, 2023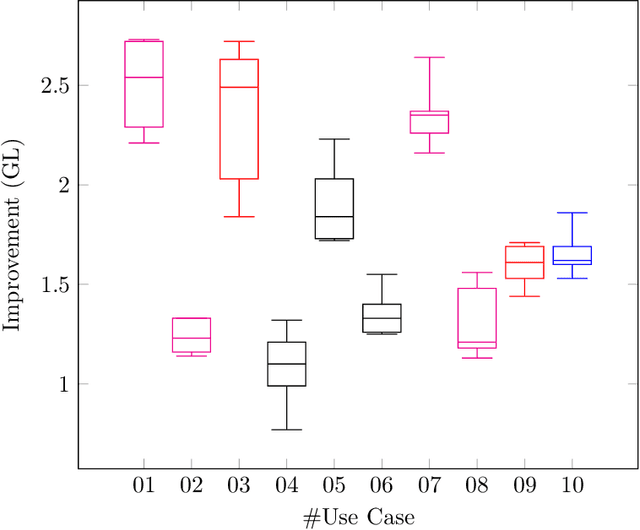
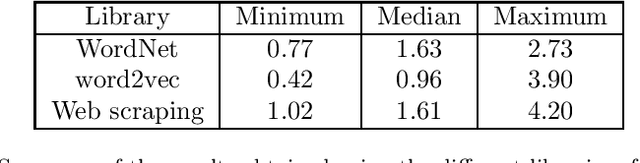
This research presents ORUGA, a method that tries to automatically optimize the readability of any text in English. The core idea behind the method is that certain factors affect the readability of a text, some of which are quantifiable (number of words, syllables, presence or absence of adverbs, and so on). The nature of these factors allows us to implement a genetic learning strategy to replace some existing words with their most suitable synonyms to facilitate optimization. In addition, this research seeks to preserve both the original text's content and form through multi-objective optimization techniques. In this way, neither the text's syntactic structure nor the semantic content of the original message is significantly distorted. An exhaustive study on a substantial number and diversity of texts confirms that our method was able to optimize the degree of readability in all cases without significantly altering their form or meaning. The source code of this approach is available at https://github.com/jorge-martinez-gil/oruga.
A Survey on Legal Question Answering Systems
Oct 12, 2021


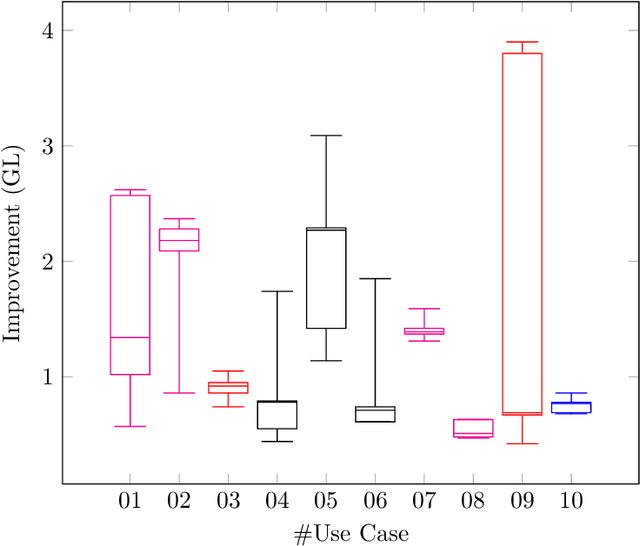
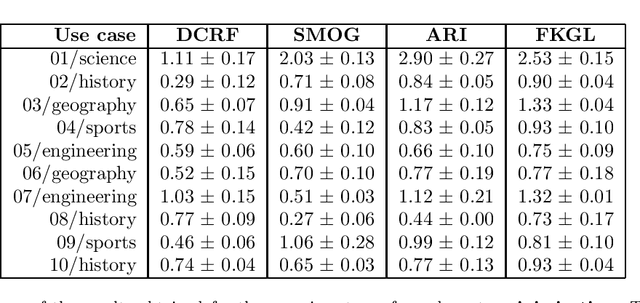
Many legal professionals think that the explosion of information about local, regional, national, and international legislation makes their practice more costly, time-consuming, and even error-prone. The two main reasons for this are that most legislation is usually unstructured, and the tremendous amount and pace with which laws are released causes information overload in their daily tasks. In the case of the legal domain, the research community agrees that a system allowing to generate automatic responses to legal questions could substantially impact many practical implications in daily activities. The degree of usefulness is such that even a semi-automatic solution could significantly help to reduce the workload to be faced. This is mainly because a Question Answering system could be able to automatically process a massive amount of legal resources to answer a question or doubt in seconds, which means that it could save resources in the form of effort, money, and time to many professionals in the legal sector. In this work, we quantitatively and qualitatively survey the solutions that currently exist to meet this challenge.
Knowledge Graphs in Manufacturing and Production: A Systematic Literature Review
Dec 16, 2020
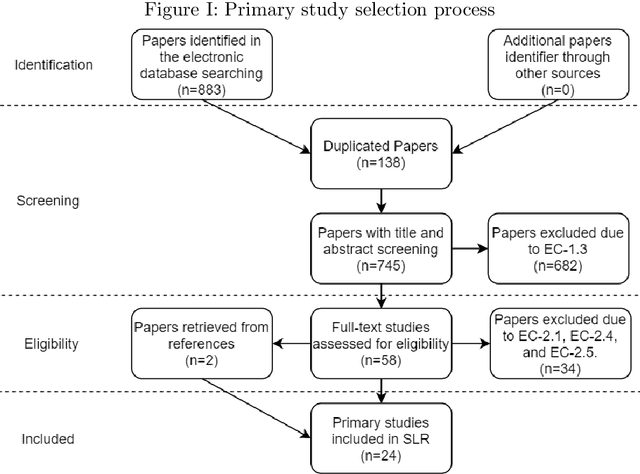

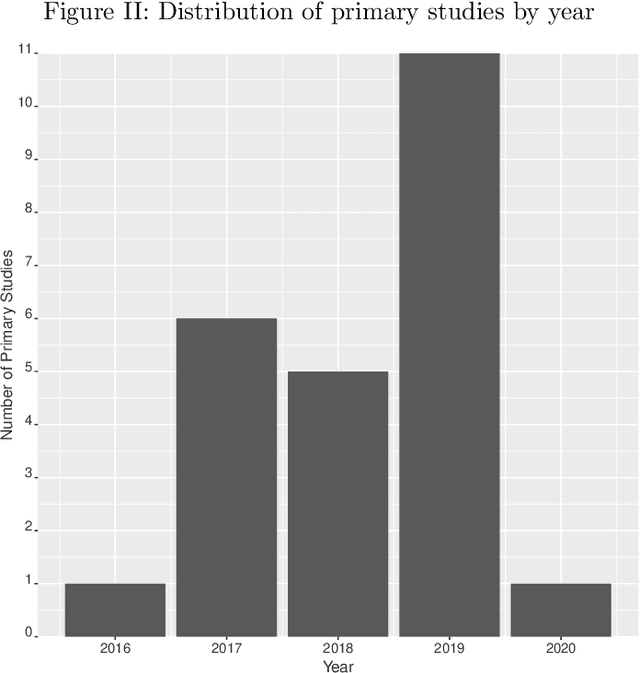
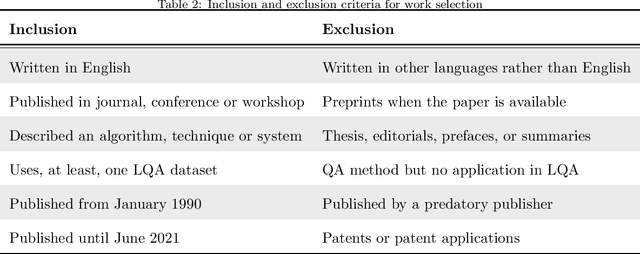
Knowledge graphs in manufacturing and production aim to make production lines more efficient and flexible with higher quality output. This makes knowledge graphs attractive for companies to reach Industry 4.0 goals. However, existing research in the field is quite preliminary, and more research effort on analyzing how knowledge graphs can be applied in the field of manufacturing and production is needed. Therefore, we have conducted a systematic literature review as an attempt to characterize the state-of-the-art in this field, i.e., by identifying exiting research and by identifying gaps and opportunities for further research. To do that, we have focused on finding the primary studies in the existing literature, which were classified and analyzed according to four criteria: bibliometric key facts, research type facets, knowledge graph characteristics, and application scenarios. Besides, an evaluation of the primary studies has also been carried out to gain deeper insights in terms of methodology, empirical evidence, and relevance. As a result, we can offer a complete picture of the domain, which includes such interesting aspects as the fact that knowledge fusion is currently the main use case for knowledge graphs, that empirical research and industrial application are still missing to a large extent, that graph embeddings are not fully exploited, and that technical literature is fast-growing but seems to be still far from its peak.
SIFT: An Algorithm for Extracting Structural Information From Taxonomies
Feb 23, 2016
In this work we present SIFT, a 3-step algorithm for the analysis of the structural information represented by means of a taxonomy. The major advantage of this algorithm is the capability to leverage the information inherent to the hierarchical structures of taxonomies to infer correspondences which can allow to merge them in a later step. This method is particular relevant in scenarios where taxonomy alignment techniques exploiting textual information from taxonomy nodes cannot operate successfully.