 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards federated multivariate statistical process control (FedMSPC)
Nov 04, 2022
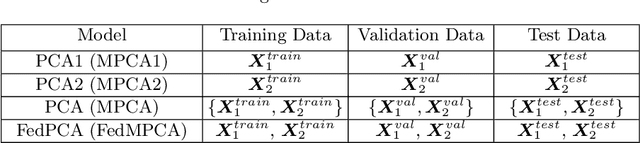


The ongoing transition from a linear (produce-use-dispose) to a circular economy poses significant challenges to current state-of-the-art information and communication technologies. In particular, the derivation of integrated, high-level views on material, process, and product streams from (real-time) data produced along value chains is challenging for several reasons. Most importantly, sufficiently rich data is often available yet not shared across company borders because of privacy concerns which make it impossible to build integrated process models that capture the interrelations between input materials, process parameters, and key performance indicators along value chains. In the current contribution, we propose a privacy-preserving, federated multivariate statistical process control (FedMSPC) framework based on Federated Principal Component Analysis (PCA) and Secure Multiparty Computation to foster the incentive for closer collaboration of stakeholders along value chains. We tested our approach on two industrial benchmark data sets - SECOM and ST-AWFD. Our empirical results demonstrate the superior fault detection capability of the proposed approach compared to standard, single-party (multiway) PCA. Furthermore, we showcase the possibility of our framework to provide privacy-preserving fault diagnosis to each data holder in the value chain to underpin the benefits of secure data sharing and federated process modeling.
Knowledge Graphs in Manufacturing and Production: A Systematic Literature Review
Dec 16, 2020
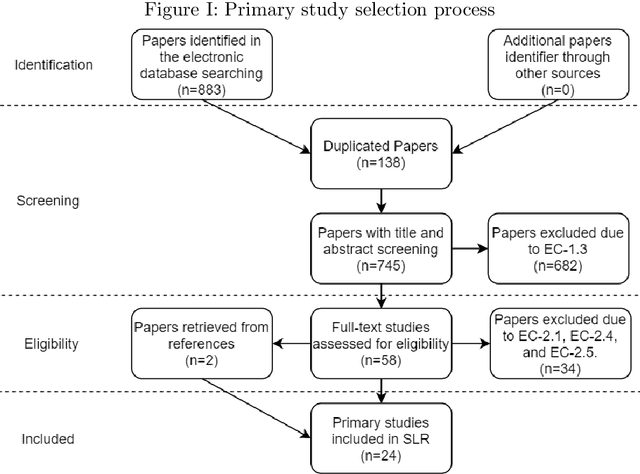

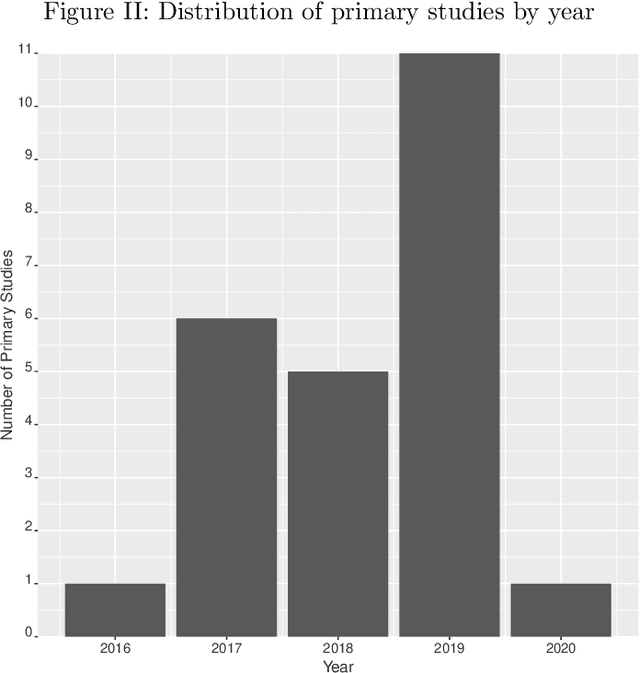
Knowledge graphs in manufacturing and production aim to make production lines more efficient and flexible with higher quality output. This makes knowledge graphs attractive for companies to reach Industry 4.0 goals. However, existing research in the field is quite preliminary, and more research effort on analyzing how knowledge graphs can be applied in the field of manufacturing and production is needed. Therefore, we have conducted a systematic literature review as an attempt to characterize the state-of-the-art in this field, i.e., by identifying exiting research and by identifying gaps and opportunities for further research. To do that, we have focused on finding the primary studies in the existing literature, which were classified and analyzed according to four criteria: bibliometric key facts, research type facets, knowledge graph characteristics, and application scenarios. Besides, an evaluation of the primary studies has also been carried out to gain deeper insights in terms of methodology, empirical evidence, and relevance. As a result, we can offer a complete picture of the domain, which includes such interesting aspects as the fact that knowledge fusion is currently the main use case for knowledge graphs, that empirical research and industrial application are still missing to a large extent, that graph embeddings are not fully exploited, and that technical literature is fast-growing but seems to be still far from its peak.