 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Time-Series Synchronization for Multi-Dimensional Forecasting
Nov 15, 2024The process industry's high expectations for Digital Twins require modeling approaches that can generalize across tasks and diverse domains with potentially different data dimensions and distributional shifts i.e., Foundational Models. Despite success in natural language processing and computer vision, transfer learning with (self-) supervised signals for pre-training general-purpose models is largely unexplored in the context of Digital Twins in the process industry due to challenges posed by multi-dimensional time-series data, lagged cause-effect dependencies, complex causal structures, and varying number of (exogenous) variables. We propose a novel channel-dependent pre-training strategy that leverages synchronized cause-effect pairs to overcome these challenges by breaking down the multi-dimensional time-series data into pairs of cause-effect variables. Our approach focuses on: (i) identifying highly lagged causal relationships using data-driven methods, (ii) synchronizing cause-effect pairs to generate training samples for channel-dependent pre-training, and (iii) evaluating the effectiveness of this approach in channel-dependent forecasting. Our experimental results demonstrate significant improvements in forecasting accuracy and generalization capability compared to traditional training methods.
Automated Knowledge Graph Learning in Industrial Processes
Jul 02, 2024



Industrial processes generate vast amounts of time series data, yet extracting meaningful relationships and insights remains challenging. This paper introduces a framework for automated knowledge graph learning from time series data, specifically tailored for industrial applications. Our framework addresses the complexities inherent in industrial datasets, transforming them into knowledge graphs that improve decision-making, process optimization, and knowledge discovery. Additionally, it employs Granger causality to identify key attributes that can inform the design of predictive models. To illustrate the practical utility of our approach, we also present a motivating use case demonstrating the benefits of our framework in a real-world industrial scenario. Further, we demonstrate how the automated conversion of time series data into knowledge graphs can identify causal influences or dependencies between important process parameters.
Learning Paradigms and Modelling Methodologies for Digital Twins in Process Industry
Jul 02, 2024Central to the digital transformation of the process industry are Digital Twins (DTs), virtual replicas of physical manufacturing systems that combine sensor data with sophisticated data-based or physics-based models, or a combination thereof, to tackle a variety of industrial-relevant tasks like process monitoring, predictive control or decision support. The backbone of a DT, i.e. the concrete modelling methodologies and architectural frameworks supporting these models, are complex, diverse and evolve fast, necessitating a thorough understanding of the latest state-of-the-art methods and trends to stay on top of a highly competitive market. From a research perspective, despite the high research interest in reviewing various aspects of DTs, structured literature reports specifically focusing on unravelling the utilized learning paradigms (e.g. self-supervised learning) for DT-creation in the process industry are a novel contribution in this field. This study aims to address these gaps by (1) systematically analyzing the modelling methodologies (e.g. Convolutional Neural Network, Encoder-Decoder, Hidden Markov Model) and paradigms (e.g. data-driven, physics-based, hybrid) used for DT-creation; (2) assessing the utilized learning strategies (e.g. supervised, unsupervised, self-supervised); (3) analyzing the type of modelling task (e.g. regression, classification, clustering); and (4) identifying the challenges and research gaps, as well as, discuss potential resolutions provided.
Opening the black-box of Neighbor Embedding with Hotelling's T2 statistic and Q-residuals
Sep 05, 2022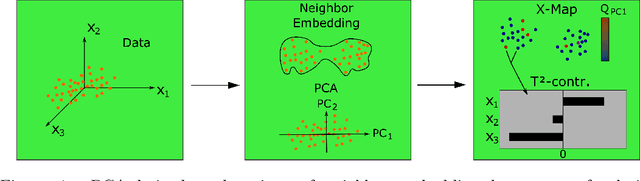
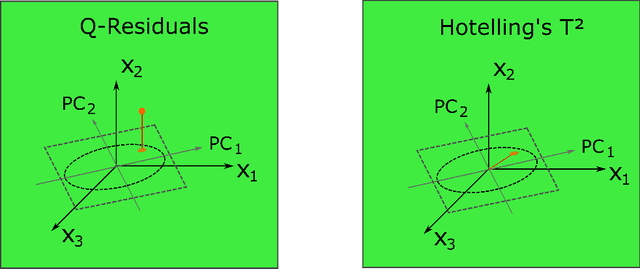
In contrast to classical techniques for exploratory analysis of high-dimensional data sets, such as principal component analysis (PCA), neighbor embedding (NE) techniques tend to better preserve the local structure/topology of high-dimensional data. However, the ability to preserve local structure comes at the expense of interpretability: Techniques such as t-Distributed Stochastic Neighbor Embedding (t-SNE) or Uniform Manifold Approximation and Projection (UMAP) do not give insights into which input variables underlie the topological (cluster) structure seen in the corresponding embedding. We here propose different "tricks" from the chemometrics field based on PCA, Q-residuals and Hotelling's T2 contributions in combination with novel visualization approaches to derive local and global explanations of neighbor embedding. We show how our approach is capable of identifying discriminatory features between groups of data points that remain unnoticed when exploring NEs using standard univariate or multivariate approaches.