 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Time-Series Synchronization for Multi-Dimensional Forecasting
Nov 15, 2024The process industry's high expectations for Digital Twins require modeling approaches that can generalize across tasks and diverse domains with potentially different data dimensions and distributional shifts i.e., Foundational Models. Despite success in natural language processing and computer vision, transfer learning with (self-) supervised signals for pre-training general-purpose models is largely unexplored in the context of Digital Twins in the process industry due to challenges posed by multi-dimensional time-series data, lagged cause-effect dependencies, complex causal structures, and varying number of (exogenous) variables. We propose a novel channel-dependent pre-training strategy that leverages synchronized cause-effect pairs to overcome these challenges by breaking down the multi-dimensional time-series data into pairs of cause-effect variables. Our approach focuses on: (i) identifying highly lagged causal relationships using data-driven methods, (ii) synchronizing cause-effect pairs to generate training samples for channel-dependent pre-training, and (iii) evaluating the effectiveness of this approach in channel-dependent forecasting. Our experimental results demonstrate significant improvements in forecasting accuracy and generalization capability compared to traditional training methods.
Learning Paradigms and Modelling Methodologies for Digital Twins in Process Industry
Jul 02, 2024Central to the digital transformation of the process industry are Digital Twins (DTs), virtual replicas of physical manufacturing systems that combine sensor data with sophisticated data-based or physics-based models, or a combination thereof, to tackle a variety of industrial-relevant tasks like process monitoring, predictive control or decision support. The backbone of a DT, i.e. the concrete modelling methodologies and architectural frameworks supporting these models, are complex, diverse and evolve fast, necessitating a thorough understanding of the latest state-of-the-art methods and trends to stay on top of a highly competitive market. From a research perspective, despite the high research interest in reviewing various aspects of DTs, structured literature reports specifically focusing on unravelling the utilized learning paradigms (e.g. self-supervised learning) for DT-creation in the process industry are a novel contribution in this field. This study aims to address these gaps by (1) systematically analyzing the modelling methodologies (e.g. Convolutional Neural Network, Encoder-Decoder, Hidden Markov Model) and paradigms (e.g. data-driven, physics-based, hybrid) used for DT-creation; (2) assessing the utilized learning strategies (e.g. supervised, unsupervised, self-supervised); (3) analyzing the type of modelling task (e.g. regression, classification, clustering); and (4) identifying the challenges and research gaps, as well as, discuss potential resolutions provided.
Probabilistic Distance-Based Outlier Detection
May 16, 2023The scores of distance-based outlier detection methods are difficult to interpret, making it challenging to determine a cut-off threshold between normal and outlier data points without additional context. We describe a generic transformation of distance-based outlier scores into interpretable, probabilistic estimates. The transformation is ranking-stable and increases the contrast between normal and outlier data points. Determining distance relationships between data points is necessary to identify the nearest-neighbor relationships in the data, yet, most of the computed distances are typically discarded. We show that the distances to other data points can be used to model distance probability distributions and, subsequently, use the distributions to turn distance-based outlier scores into outlier probabilities. Our experiments show that the probabilistic transformation does not impact detection performance over numerous tabular and image benchmark datasets but results in interpretable outlier scores with increased contrast between normal and outlier samples. Our work generalizes to a wide range of distance-based outlier detection methods, and because existing distance computations are used, it adds no significant computational overhead.
A NoSQL Data-based Personalized Recommendation System for C2C e-Commerce
Jun 26, 2018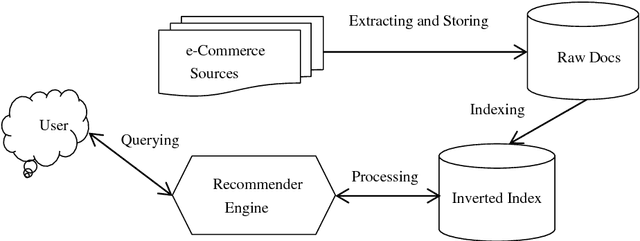
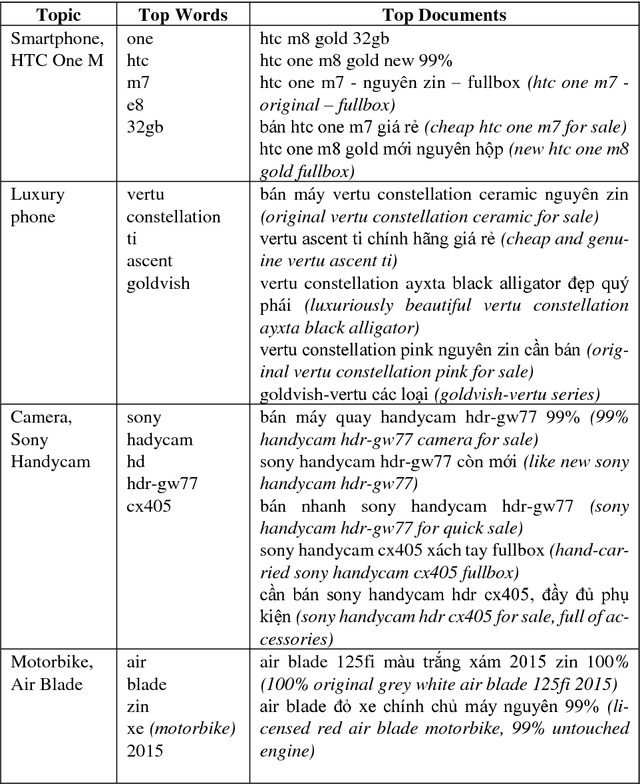
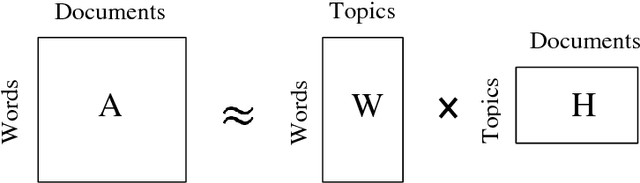
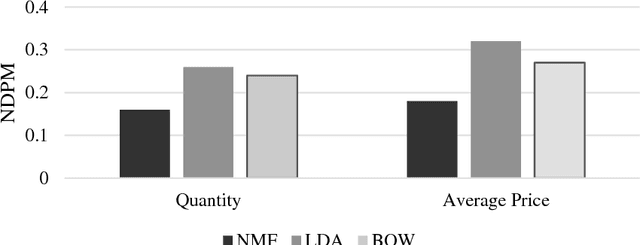
With the considerable development of customer-to-customer (C2C) e-commerce in the recent years, there is a big demand for an effective recommendation system that suggests suitable websites for users to sell their items with some specified needs. Nonetheless, e-commerce recommendation systems are mostly designed for business-to-customer (B2C) websites, where the systems offer the consumers the products that they might like to buy. Almost none of the related research works focus on choosing selling sites for target items. In this paper, we introduce an approach that recommends the selling websites based upon the item's description, category, and desired selling price. This approach employs NoSQL data-based machine learning techniques for building and training topic models and classification models. The trained models can then be used to rank the websites dynamically with respect to the user needs. The experimental results with real-world datasets from Vietnam C2C websites will demonstrate the effectiveness of our proposed method.