 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Distance-Based Outlier Detection
May 16, 2023The scores of distance-based outlier detection methods are difficult to interpret, making it challenging to determine a cut-off threshold between normal and outlier data points without additional context. We describe a generic transformation of distance-based outlier scores into interpretable, probabilistic estimates. The transformation is ranking-stable and increases the contrast between normal and outlier data points. Determining distance relationships between data points is necessary to identify the nearest-neighbor relationships in the data, yet, most of the computed distances are typically discarded. We show that the distances to other data points can be used to model distance probability distributions and, subsequently, use the distributions to turn distance-based outlier scores into outlier probabilities. Our experiments show that the probabilistic transformation does not impact detection performance over numerous tabular and image benchmark datasets but results in interpretable outlier scores with increased contrast between normal and outlier samples. Our work generalizes to a wide range of distance-based outlier detection methods, and because existing distance computations are used, it adds no significant computational overhead.
OutlierDetection.jl: A modular outlier detection ecosystem for the Julia programming language
Nov 08, 2022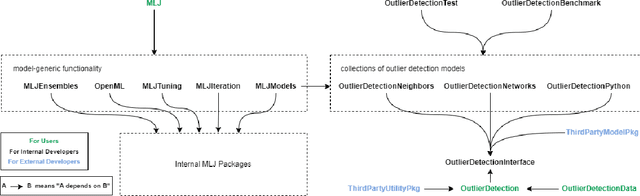



OutlierDetection.jl is an open-source ecosystem for outlier detection in Julia. It provides a range of high-performance outlier detection algorithms implemented directly in Julia. In contrast to previous packages, our ecosystem enables the development highly-scalable outlier detection algorithms using a high-level programming language. Additionally, it provides a standardized, yet flexible, interface for future outlier detection algorithms and allows for model composition unseen in previous packages. Best practices such as unit testing, continuous integration, and code coverage reporting are enforced across the ecosystem. The most recent version of OutlierDetection.jl is available at https://github.com/OutlierDetectionJL/OutlierDetection.jl.
Ensuring the Robustness and Reliability of Data-Driven Knowledge Discovery Models in Production and Manufacturing
Jul 28, 2020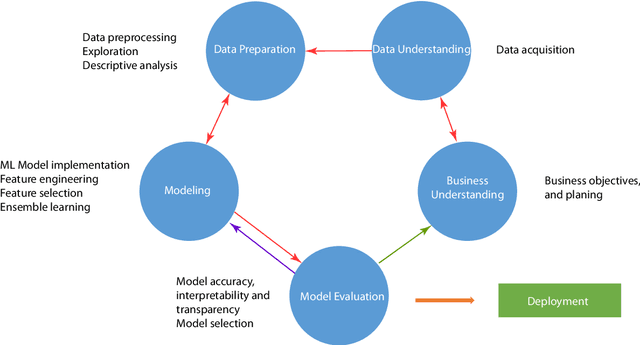
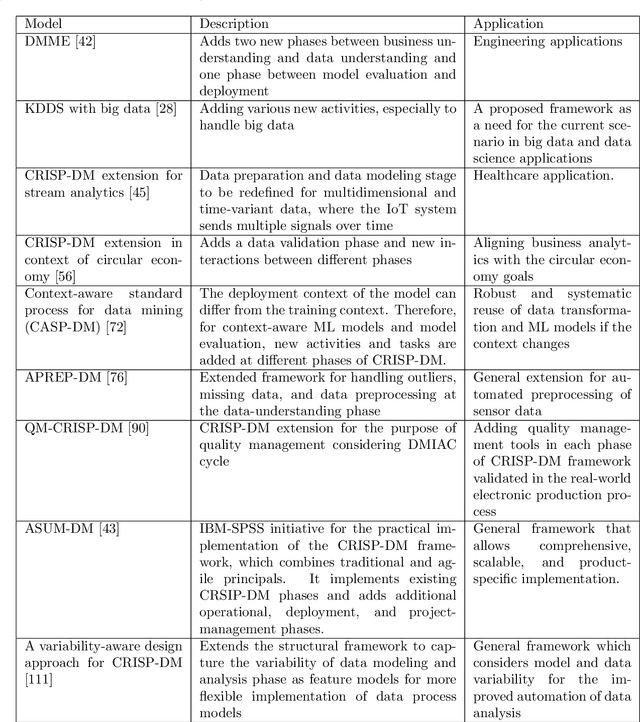
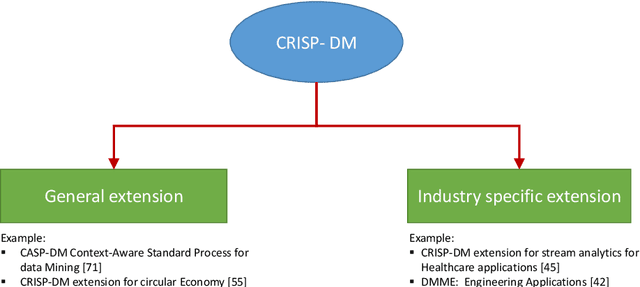
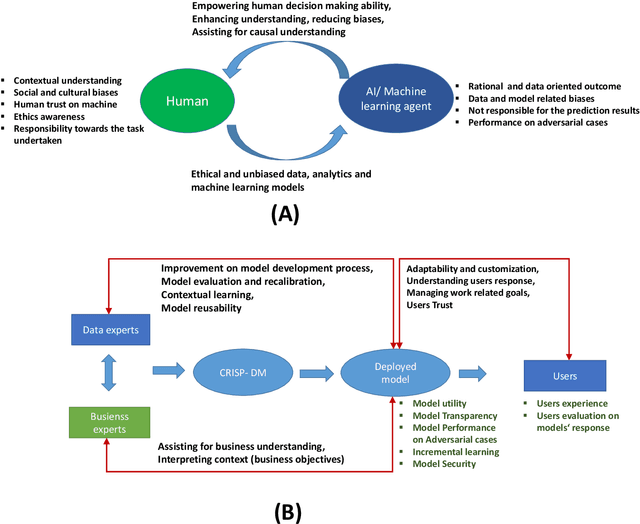
The implementation of robust, stable, and user-centered data analytics and machine learning models is confronted by numerous challenges in production and manufacturing. Therefore, a systematic approach is required to develop, evaluate, and deploy such models. The data-driven knowledge discovery framework provides an orderly partition of the data-mining processes to ensure the practical implementation of data analytics and machine learning models. However, the practical application of robust industry-specific data-driven knowledge discovery models faces multiple data-- and model-development--related issues. These issues should be carefully addressed by allowing a flexible, customized, and industry-specific knowledge discovery framework; in our case, this takes the form of the cross-industry standard process for data mining (CRISP-DM). This framework is designed to ensure active cooperation between different phases to adequately address data- and model-related issues. In this paper, we review several extensions of CRISP-DM models and various data-robustness-- and model-robustness--related problems in machine learning, which currently lacks proper cooperation between data experts and business experts because of the limitations of data-driven knowledge discovery models.